
Distributed inference meeting under 100ms market latency requirements
Distributed inference meeting under 100ms market latency requirements
-
Figure 2 shows the next-token latency for the Llama2 7B model with batch size scaling on the X-axis and Latency for Next token (ms) on the Y-axis. The bars represent the respective input token lengths of 256, 1024, and 2048 respectively. As can be seen, for the LLAMA2-7B parameter model, the next token latency is well within the 100ms requirement on a single node for batch size/input token size up to 16/1024. The smaller model size of 7B parameter ensures we can fit processing using a single node.
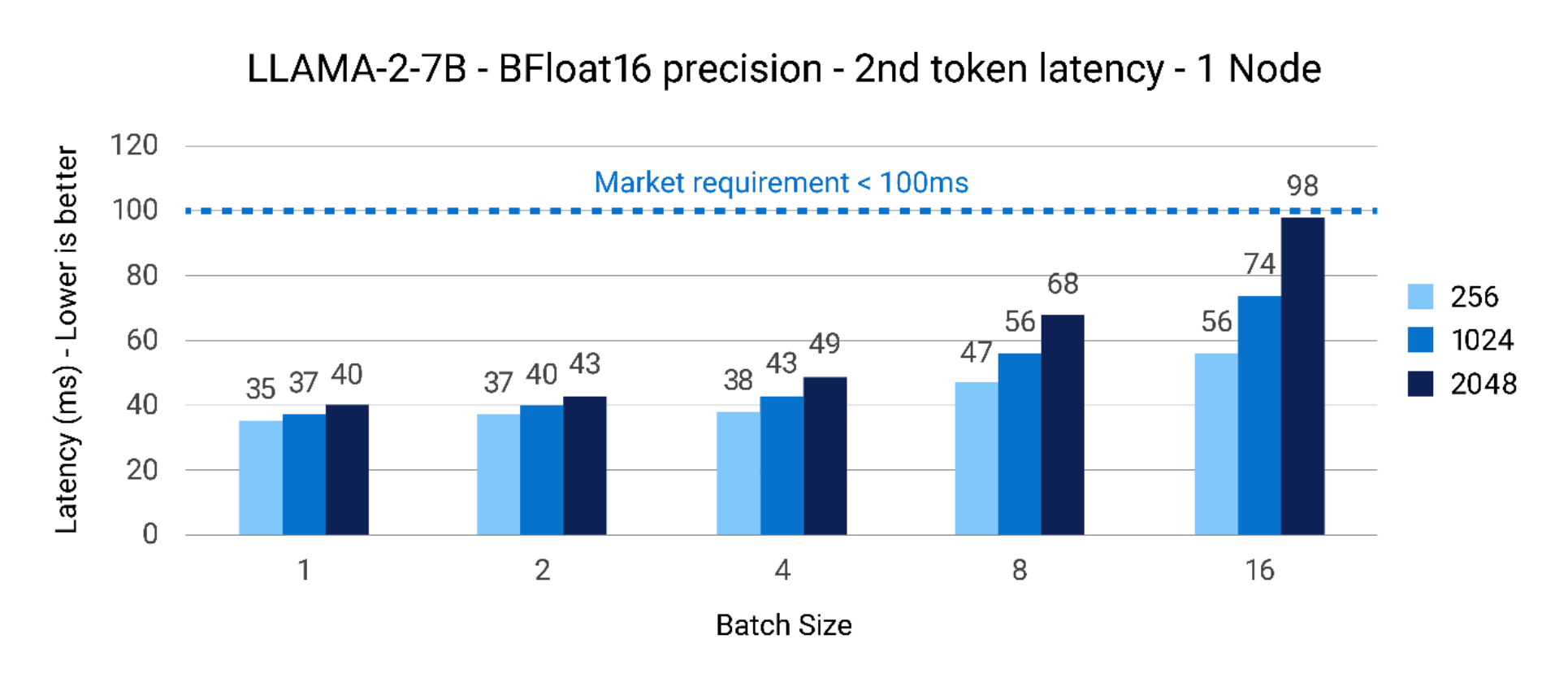
Figure 2. LLAMA2-7B – BFloat16 precision – 1 node next token latency(ms)
Figures 3 and 4 show the batch size scaling on the X-axis with Latency for Next token (ms) on the Y-axis for models LLAMA-2 13B parameters and Falcon-40B parameters. Here, we show the latency data as we scale from 1 to 4 nodes. Once again, the bars represent the respective input token lengths of 256, 1024, and 2048 respectively.
As can be seen, for the LLAMA2-13B parameter model, the next token latency is well within the 100ms requirement on a single node for batch size/input token size up to 8/1024. However, scaling to 4 nodes ensures we can also scale to BS16/2048 Input tokens to be well within the target of 100ms. This shows that depending on the use-case and if a chatbot needs to, a service request of 16 concurrent users for LLAMA2-13B parameter model can achieve that using 4x nodes.
Note: Additional optimizations at the compute, memory bandwidth, and network communication are in progress to ensure the scaling efficiency for multi-node gets to near-linear scaling.
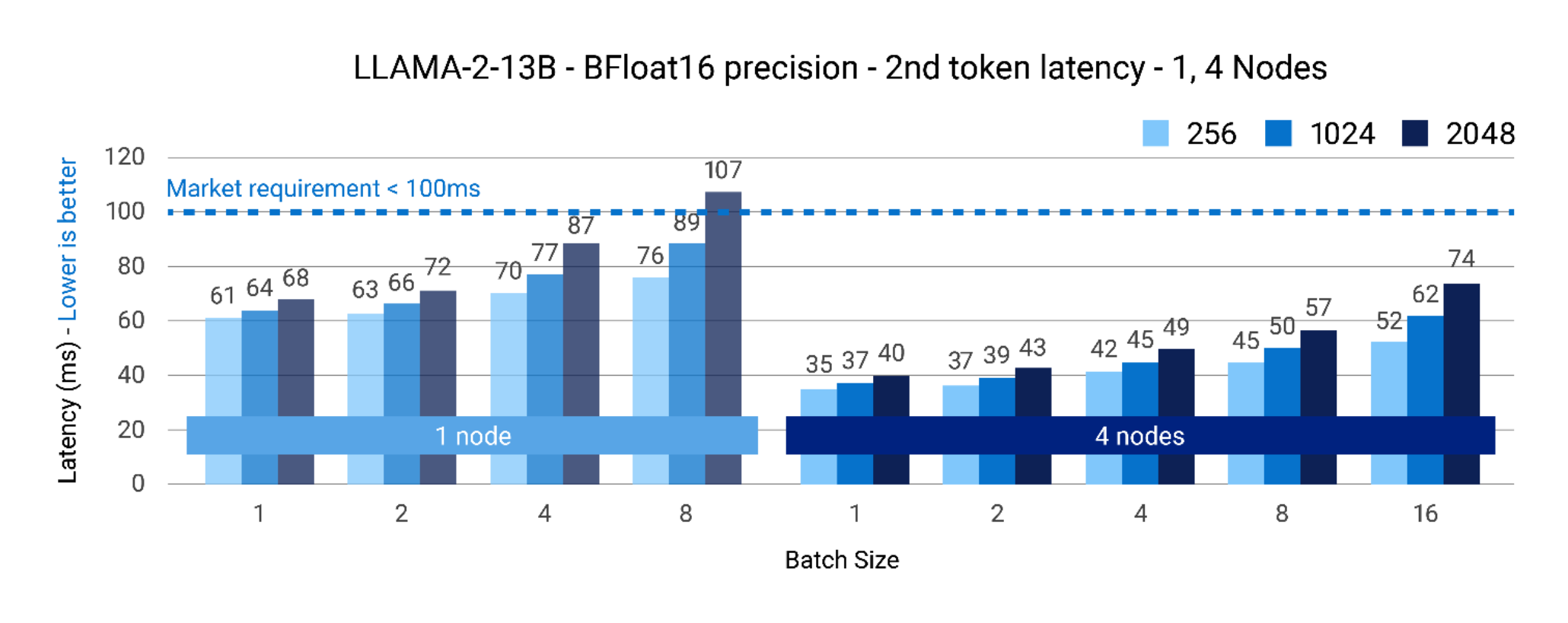
Figure 3. LLAMA2-13B – BFloat16 precision – next token latency(ms) @ 1, 4 nodes
Given the model size of Falcon-40B, starting with a single node and even scaling to two nodes does not help meet the next-token latency requirements. In this scenario, using 4 nodes is an ideal choice to begin with. One can meet the latency targets up to batch size 4, 1024 input tokens with Falcon-40B.
Note: Additional optimizations at the compute, memory bandwidth, and network communication are in progress to ensure the scaling efficiency for multi-node gets to near-linear scaling.
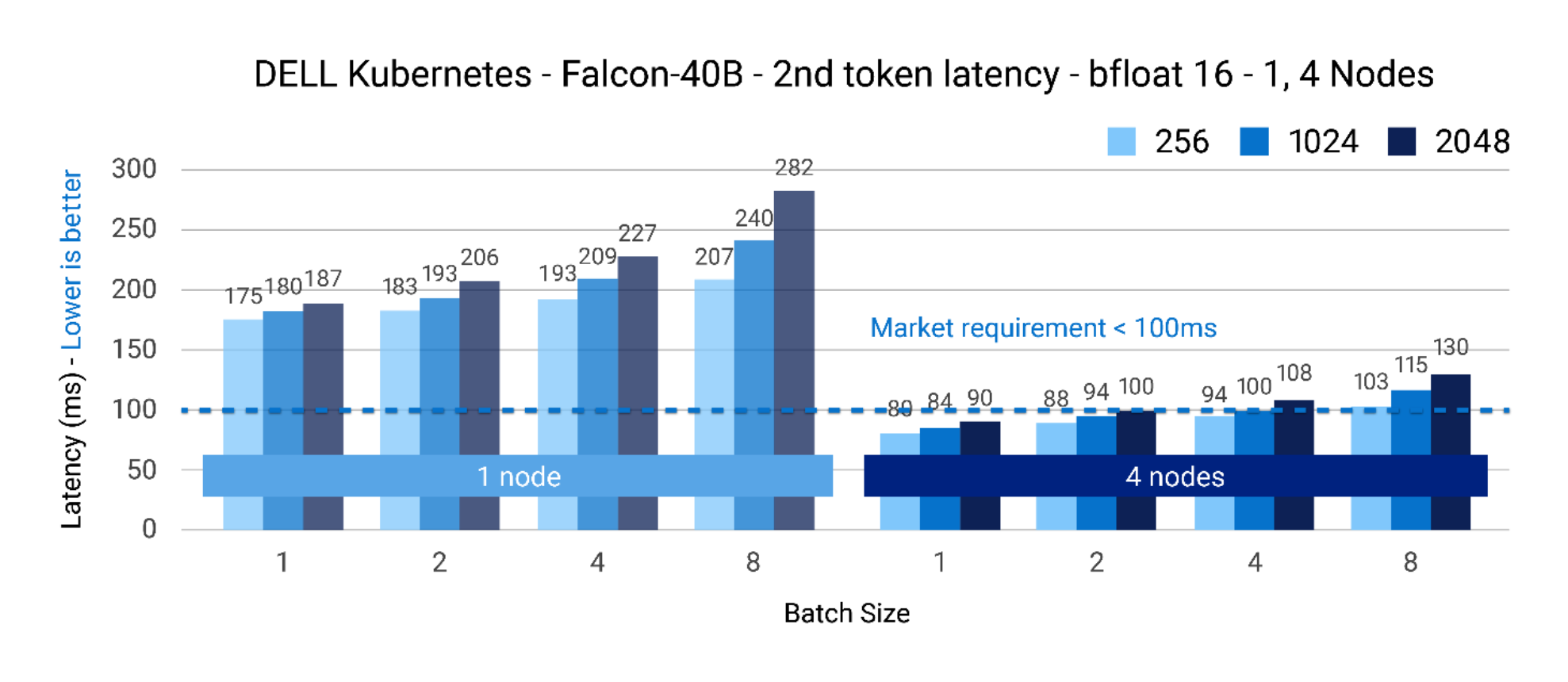
Figure 4. Falcon-40B – BFloat16 precision – next token latency(ms) @ 1, 4 nodes