
Step 2: Generate TensorRT engines with TAO converter (from .etlt format to .engine format)
Step 2: Generate TensorRT engines with TAO converter (from .etlt format to .engine format)
-
- Install the converter within the docker image.
Go inside the docker image deepstream:6.0-ea-21.06-Triton, and download and install the tao-converter appropriate for the hardware and software stack under test (in our case for platform x86 + GPU | CUDA 11.1 / cuDNN 8.0 / TensorRT 7.2)
$ sudo docker run --gpus all -it --rm --shm-size=1g --ulimit memlock=-1 –ulimit stack=67108864 -v /tmp/.X11-unix:/tmp/.X11-unix -v /home/:/home/ nvcr.io/nvdeepstream/deepstream6_ea/deepstream:6.0-ea-21.06-triton
$ wget https://developer.nvidia.com/cuda111-cudnn80-trt72-0
$ unzip cuda11.1-trt7.2-20210820T231205Z-001.zip
$ apt-get update
$ apt-get install libssl-dev
$ export TRT_LIB_PATH=/usr/lib/x86_64-linux-gnu
$ export TRT_INC_PATH=/usr/include/x86_64-linux-gnu
$ chmod +x -R /home/
$ chmod 777 -R /home/
$ /home/cuda11.1-trt7.2/tao-converter -h
- Save the docker image changes locally, and work with a local mount volume.
Before exiting the container, open another shell window, find the <CONTAINER ID>, and copy the user Triton blog workspace at the localhost to save changes locally and modify files for experiments from localhost.
$ sudo docker ps
$ sudo docker cp <CONTAINER ID>:/opt/nvidia/deepstream/deepstream-6.0 "/home/Deepstream_6.0_Triton/"
Make the docker commit to save the changes within the docker
$ sudo docker commit <CONTAINER ID> nvcr.io/nvdeepstream/deepstream6_ea/deepstream:6.0-ea-21.06-Triton_committed
- Convert to TensorRT engine in FP32 precision mode (from .etlt format to .engine format).
$ export KEY=<YOUR_KEY>
$ /home/cuda11.1-trt7.2/tao-converter -k $KEY \
-d 3,384,1248 \
-o NMS \
-e $USER /home/experiments/retinanet/export/retinanet_resnet18_INT8_FP32.engine \
-b 8 \
-m 8 \
-t fp32 \
-i nchw \ /home/experiments/retinanet/experiment_dir_retrain/weights/retinanet_resnet18_FP32_BS8.etlt
- Convert to TensorRT engine in FP16 precision mode (from .etlt format to .engine format).
The below commands were used to generate the TensorRT engines optimized for max_batch_size=8 (implicit batch networks).
$ export KEY=<YOUR_KEY>
$ /home/cuda11.1-trt7.2/tao-converter -k $KEY \
-d 3,384,1248 \
-o NMS \
-e $USER /home/experiments/retinanet/export/retinanet_resnet18_INT8_FP16.engine \
-b 8 \
-m 8 \
-t fp16 \
-i nchw \ /home/experiments/retinanet/experiment_dir_retrain/weights/retinanet_resnet18_FP16_BS8.etlt
- Convert to TensorRT engine in INT8 precision mode (from .etlt format to .engine format).
$ export KEY=<YOUR_KEY>
$ /home/cuda11.1-trt7.2/tao-converter -k $KEY \
-d 3,384,1248 \
-o NMS \
-c /home/experiments/retinanet/export/cal.bin \
-e $USER /home/experiments/retinanet/export/retinanet_resnet18_INT8_BS8.engine \
-b 8 \
-m 8 \
-t int8 \
-i nchw \ /home/experiments/retinanet/experiment_dir_retrain/weights/retinanet_resnet18_INT8_BS8.etlt
- Inspect the TensorRT engines with the NVIDIA Polygraphy tool (optional).
Polygraphy is a toolkit to assist in running and debugging deep learning models in various frameworks.
# To inspect models with Polygraphy
$ python3 -m pip install nvidia-pyindex
$ polygraphy inspect model /home/experiments/retinanet/export/retinanet_resnet18_INT8_BS8.engine
Stdout:
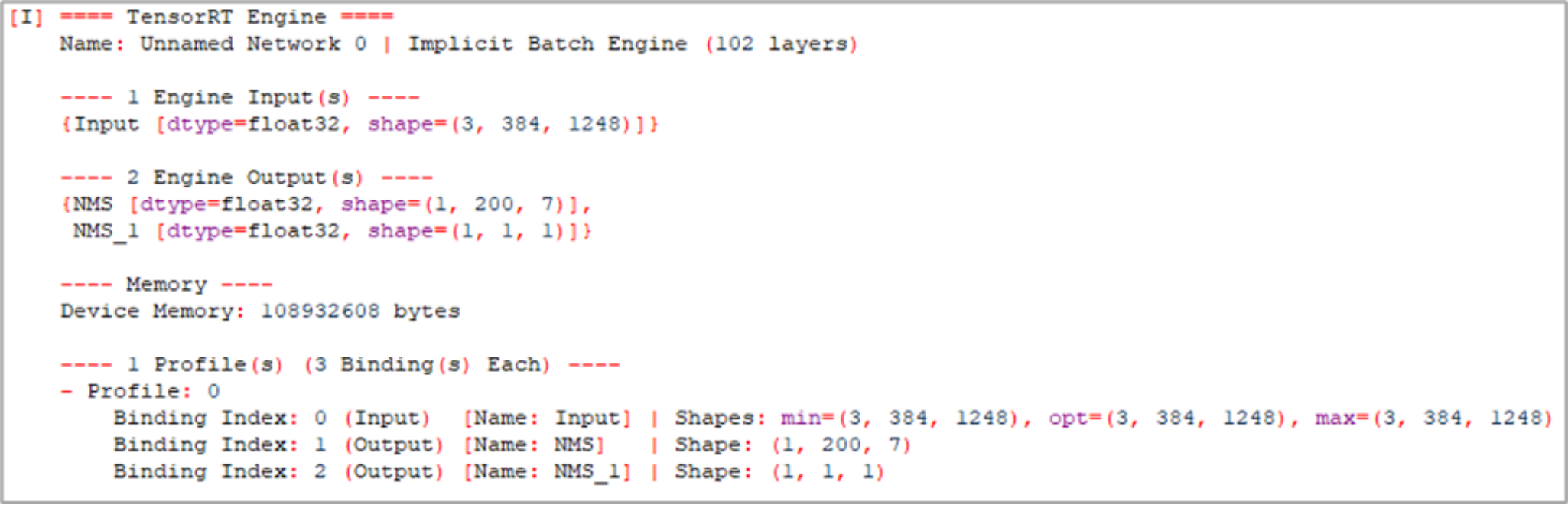
Figure 18. Model inspection with NVIDIA Polygraphy tool