
Overview of NVIDIA TAO pre-trained models for object detection
Overview of NVIDIA TAO pre-trained models for object detection
-
Object detection is computer-vision technology that both detects multiple objects and describes those objects’ locations. For a given image, object detection recognizes the individual objects and places bounding boxes around them. When running on streams of images, objects can be tracked from frame to frame. The NVIDIA NGC catalog makes available GPU-optimized object-detection model architectures and associated feature-extraction backbone networks that have been pre-trained and can be re-trained using customer and application specific images.
Object-detection model architectures:
- DetectNet_V2
- FasterRCNN
- SSD and DSSD
- YOLOV3 and YOLOV4
- RetinaNet
Feature-extraction backbones:
- MobileNet_v1 and MobileNet_v2
- SqueezeNet
- ResNet10 /18 /34 /50 /101
- GoogleNet
- VGG16 /19
- DarkNet19 /53 and cspdarkNet19 /53
- EfficientNet_b0 – b5
The figure below shows an example of transfer learning applied to object detection using the NVIDIA AI software stack running on a PowerEdge server. We chose to use the RetinaNet object detector and pair it with the EfficientNet_b0 backbone for feature extraction. While the pretraining done by NVIDIA was on the large and diverse set of ImageNet images, we now target the object detector to perform well on traffic images from another data set known as the KITTI benchmark set (see Citations).
We first use the TAO toolkit to convert KITTI dataset images into suitable training records, and use those training records to fine-tune the model. We performed this task with regular training or with Quantization Aware Training (QAT) which limits the precision carried within the computation to reflect the precision that will be used by the eventual inference engine. For our demonstration, we used training on 180 epochs of data samples for each path.
After we reach a desired model accuracy (indicated by the mean Average Precision (mAP) scores highlighted in light blue below), we use the TAO converter to produce 32-bit floating point, 16-bit floating point, or 8-bit integer inference engines. In turn, for any engines, we have our choice of deployment environments. We can run the engine with the TensorRT exec as a standalone inference engine, and we can use it on multiple video streams orchestrated within the DeepStream framework. Finally, we can use it within complex multi-engine instance pipelines created by the integrated DeepStream - Triton Inference Server combination.
To improve performance, we examine two methods which can be employed either separately or together. The first method is to improve throughput performance by making the model smaller thereby speeding up the inference engines that derive from it. This is shown in the right side of the following figure where we prune the model. This task is done by removing nodes from the model that, after training, have small activations and are set to play a smaller role in run time inference. After each pruning pass, we retrain to allow the model to recapture the understanding that may have been incidentally trimmed out of the model. After the model is at a desired size and accuracy, the inference engines can be derived from it and run as described earlier.
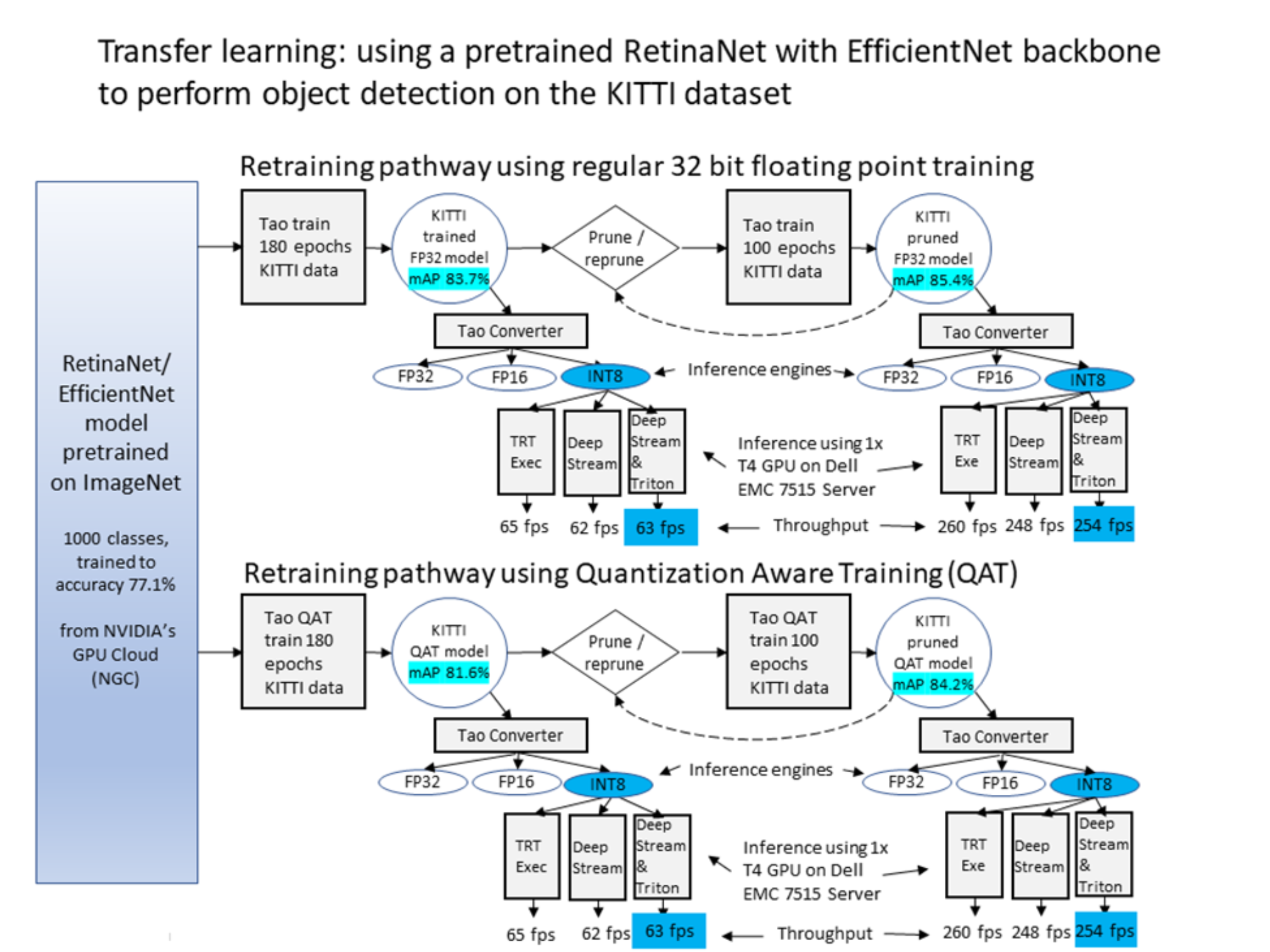
Figure 3. Transfer learning with RetinaNet or EfficientNet using NVIDIA TAO components
The second method of improvement, depicted in the bottom of the figure above, is to use Quantization Aware Training (QAT) to restrict the numerical precision maintained in the model during training. This allows the model to use the training epochs to preserve accuracy and refinement in its predictions. It can achieve this outcome even while using the coarser activations that are allowed by the 8-bit integers that are in use at inference time when using an 8-bit inference engine.
The mAP from the QAT trained models is lower for a given amount of training than for unrestricted 32-bit floating point training. However, the mAP of the 8-bit engines that are derived from the QAT trained mode can be better than the mAP seen from the 8-bit engines that are blindly converted from the non QAT 32-bit models.
The following table shows the 8-bit integer inference throughput numbers running both as a standalone engine and inside of DeepStream (throughput numbers are also given using the MobileNetV2 and ResNet50 backbones).
Table 1. RetinaNet inference throughput with different backbones
Backbone
Precision mode
Input video source
Batch-size; num-sources; model instances
Inference performance (FPS)
TensorRT engine running standalone
DeepStream running TensorRT engine
ResNet18
INT8
sample_1080p_h264.mp4
1, 1, 1
318
297
MobileNetV2
INT8
sample_1080p_h264.mp4
1, 1, 1
379
354
EfficientNet
INT8
sample_1080p_h264.mp5
1, 1, 1
260
248
ResNet50
INT8
sample_1080p_h264.mp6
1, 1, 1
156
154
The next section provides a second example including the RetinaNet running with a ResNet18 backbone. We use this example to discuss the deployment in DeepStream and DeepStream with Triton running on a PowerEdge R7515 server in further detail. The section begins with an overview of the different tools and discusses the details of this RetinaNet and ResNet combination. Though this section provides more detail, see Appendix C: Reproducibility and Appendix D: Training Specification Files for more guidance. These sections provide step-by-step commands and training config-file examples that reproduce different stages of the experiment.