
Overview
Overview
-
The following figure shows the utilization in terms of GPU compute, GPU memory, and encoder and decoder processing for tests A through E. For tests A to D, there is capacity left in in GPU memory, and encoder and decoder processing, even though the compute limit was reached. For Test E, we set up intervals from 0 to 1, to skip one frame for inference. We observed that with this configuration, the decoder processing, along with the GPU compute, both become limiting factors on inference throughput.

Figure 9. GPU Activity (%): GPU Compute, GPU Memory, Encoder, Decoder
The following figures show the plots generated with the NVDIA nvtop profiling tool.
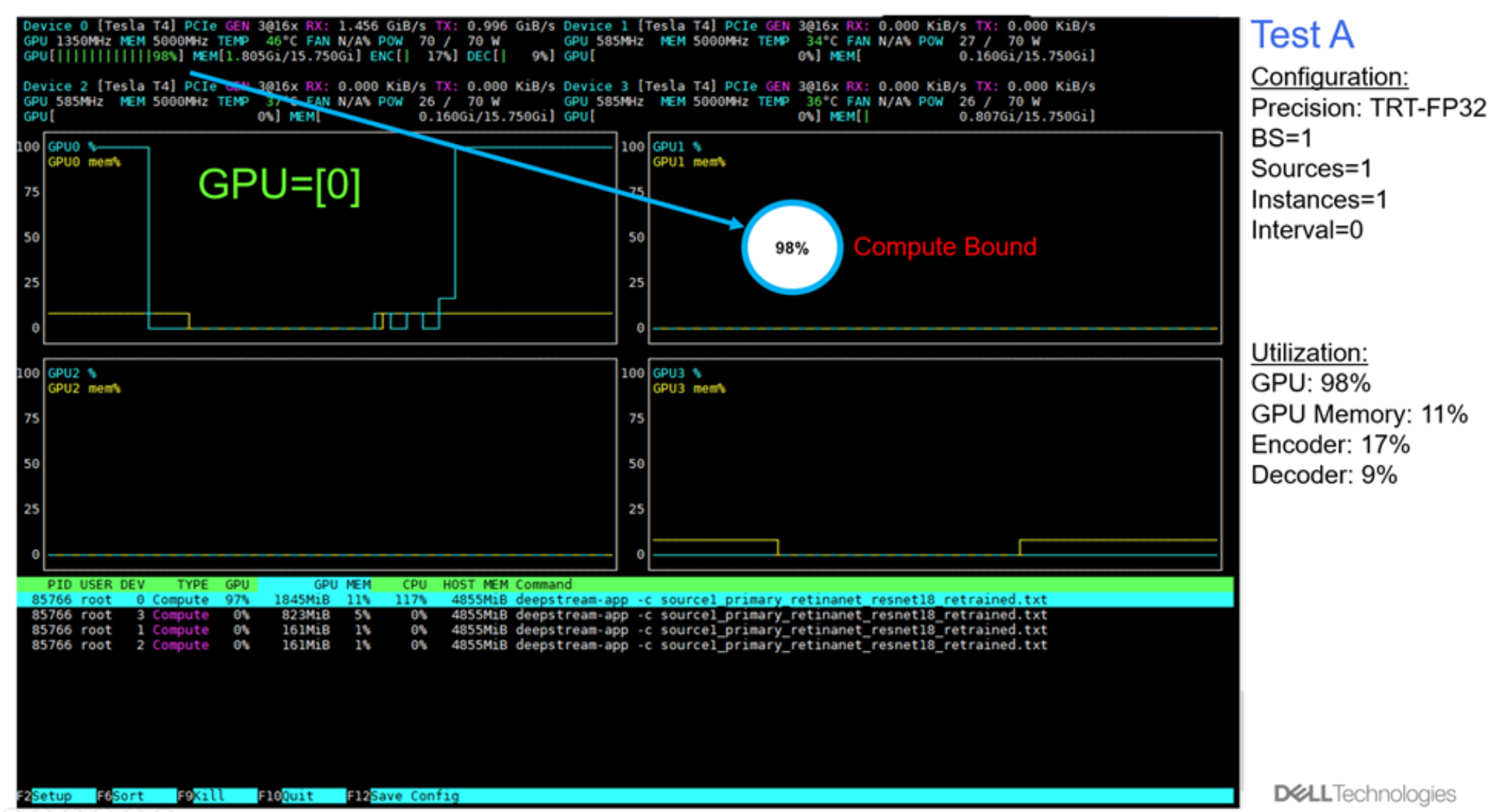
Figure 10. GPU utilization: Test A

Figure 11. GPU utilization: Test B

Figure 12. GPU utilization: Test C
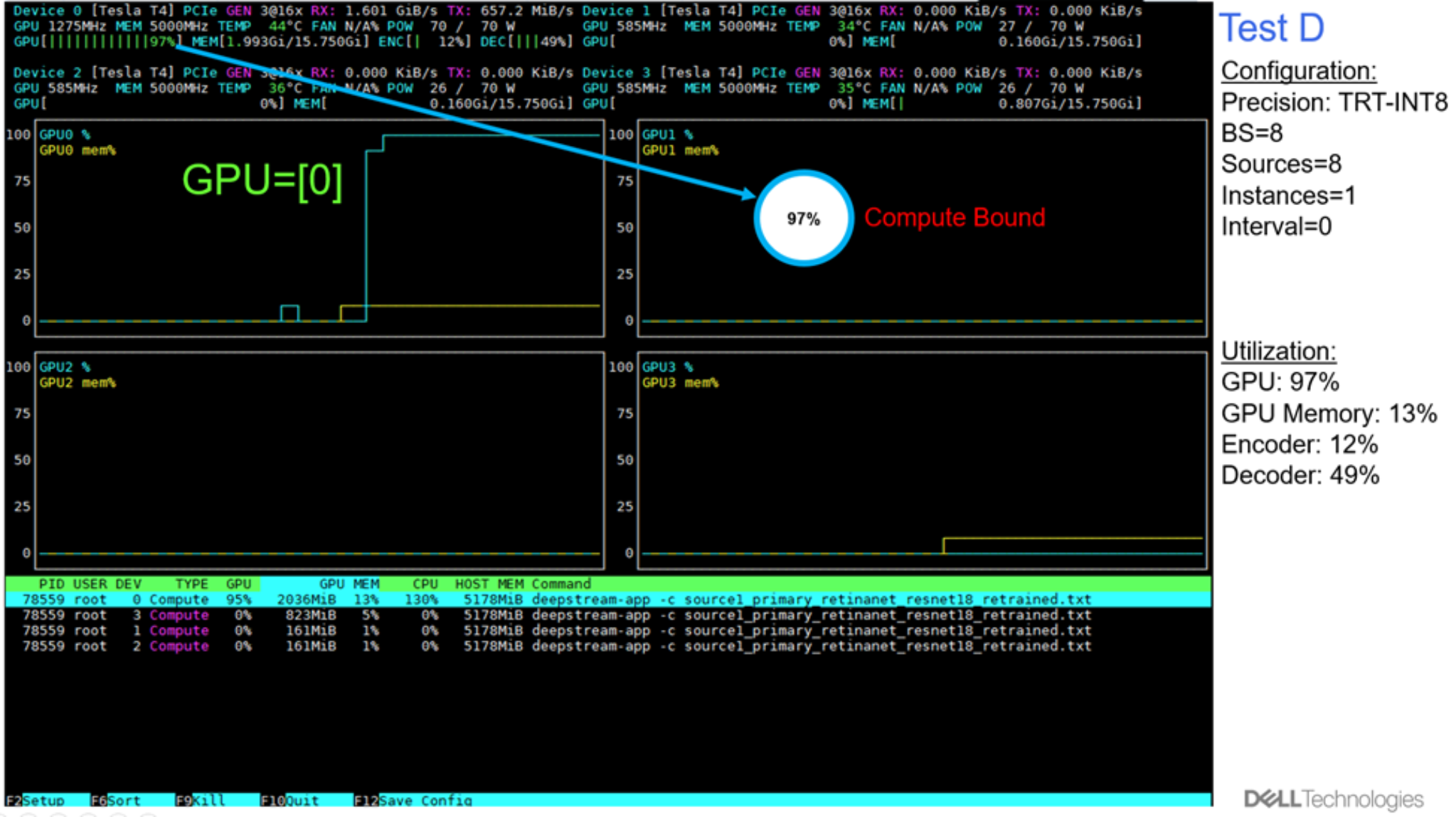
Figure 13. GPU utilization: Test D
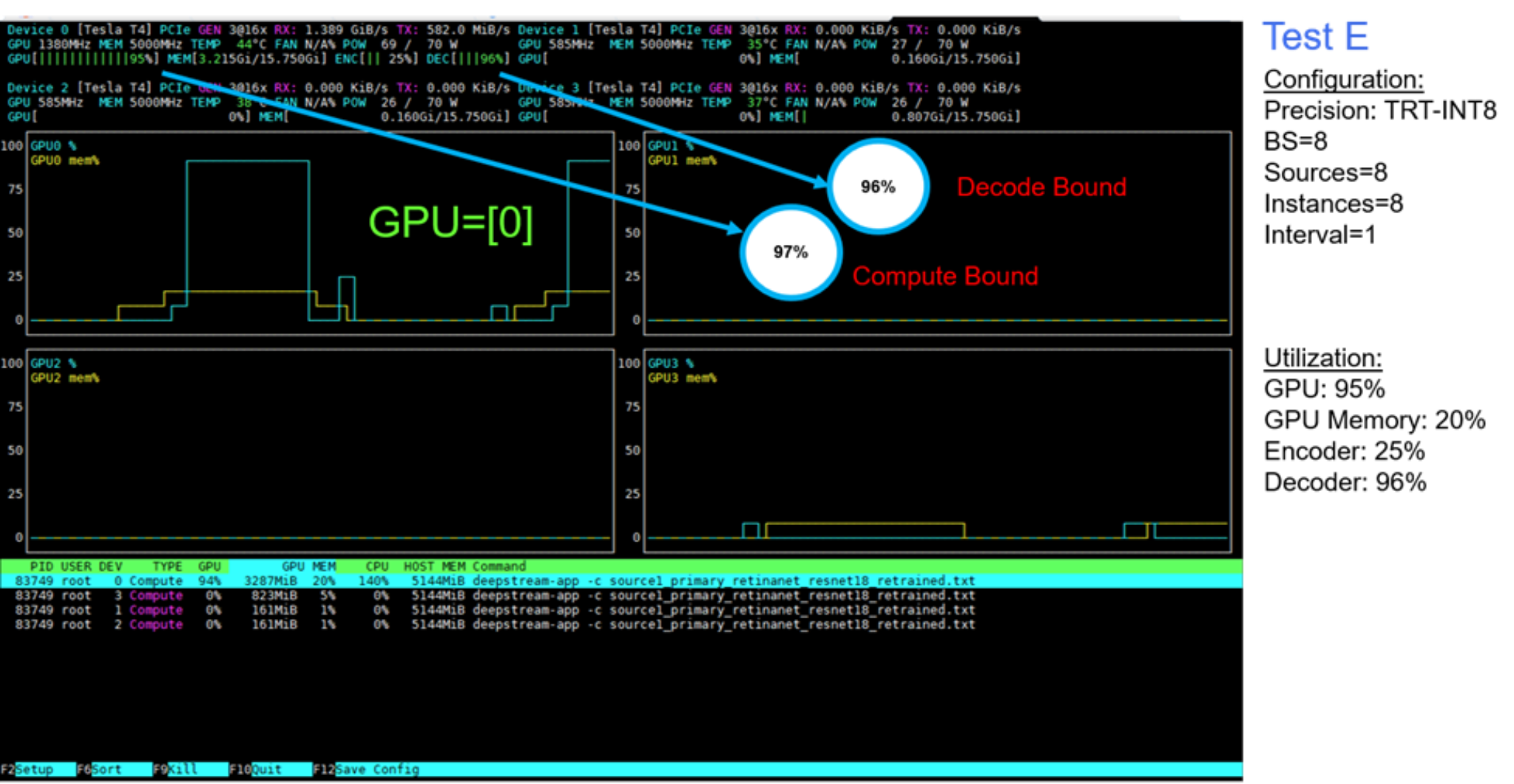
Figure 14. GPU utilization: Test E