
Overview
Overview
-
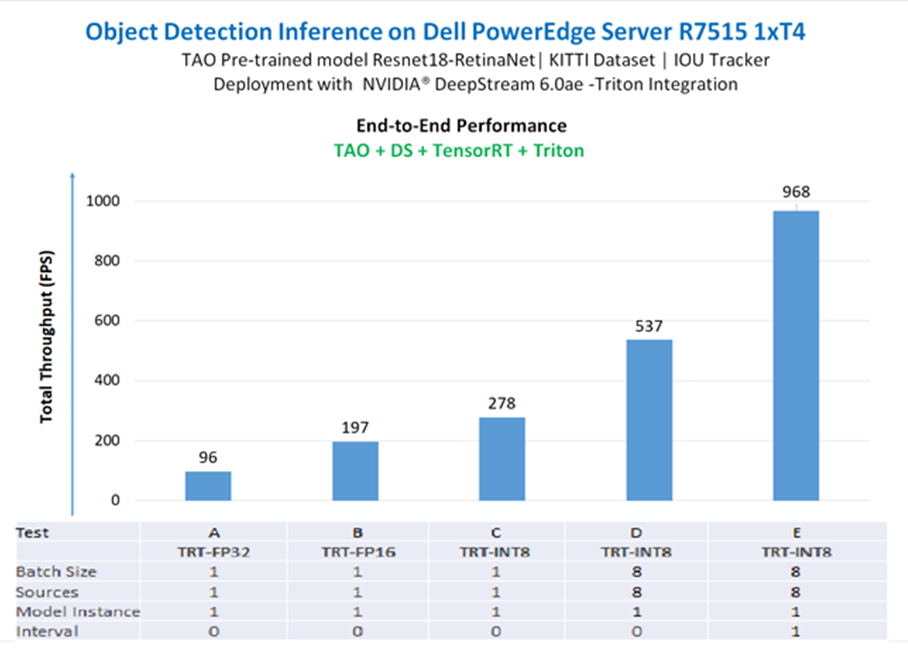
The RetinaNet with ResNet18 models were deployed in the DS-Triton end-to end pipeline with different test configurations to demonstrate inference at scale. All configurations were run using one of the four NVIDIA T4 GPUs on the PowerEdge R7515 server. Each configuration ran on 1,248 x 384 pixel, three-channel images. The following table presents the results and Figure 6 depicts that throughput performance.
- For tests A, B, and C, we used the TAO converter tool to create CUDA-optimized engines for precision modes FP32, FP16, and INT8. We kept the batch size, number of video stream sources, and instances of the model equal to 1. We observed that throughput performance went from 96 with FP32 to 278 for INT8.
- For test D, we increased the batch size and video stream sources to 8. The total inference throughput for this configuration is ~544.
- In test E, we used an interval of 1, which raises total throughput to 968. The processing is decoder-bound and compute-bound (average 95% GPU utilization and 96% decoder utilization) see Figure 14.
Table 4. RetinaNet throughput experiments running on PowerEdge R7515 with one NVIDIA T4 GPU
Test
Precision
GPU ID
Runtime inference batch size
Sources
Count
model
instances
Interval
FPS (avg)
per source
FPS (avg)
total
Speed increase from single-instance 32-bit floating-point baseline model
A
TensorRT-FP32
0
1
1
1
0
96.3
96
Baseline
B
TensorRT-FP16
0
1
1
1
0
196.7
197
~2X
C
TensorRT-INT8
0
1
1
1
0
278.2
278
~3X
D
TensorRT-INT8
0
8
8
1
0
68.0
544
~5X
E
TensorRT-INT8
0
8
8
1
1
121.1
969
~10X
Each custom application involves specific requirements, and the setting or tuning process varies on each case. For setting the parameters, NVIDIA recommends common practices for performance optimization (see DeepStream SDK: Best practices for performance optimization).
The following example shows the visualization produced with the engine running in the DeepStream-Triton framework (see the following figure).

Figure 7. Inference visualization when deployed with DeepStream - Triton