
Avoiding APD/PDL
Avoiding APD/PDL
-
PDL VMCP settings
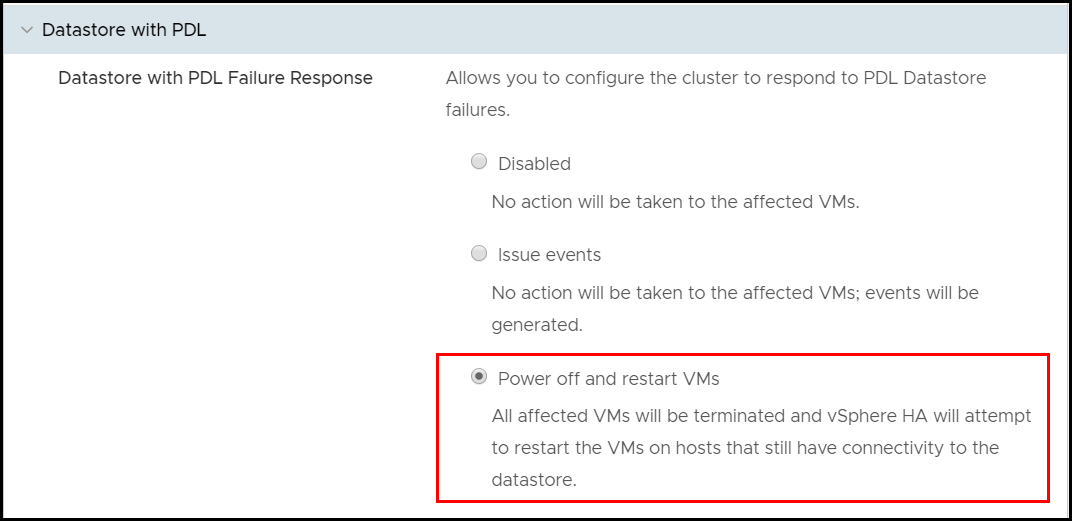
The PDL settings are the simpler of the two failure conditions to configure. This is because there are only two choices: vSphere can issue events, or it can initiate power off of the VMs and restart them on the surviving host(s). As the purpose of HA is to keep the VMs running, the default choice should always be to power off and restart. Once either option is selected, the table at the top of the edit settings is updated to reflect that choice. This is seen in Figure 56.
Figure 56 PDL datastore response for VMCP in the vSphere Client
APD VMCP settings
As APD events are transient by nature, and not a permanent condition like PDL, VMware provides a more nuanced ability to control the behavior within VMCP. Essentially, however, there are still two options to choose from: vSphere can issue events, or it can initiate power off of the VMs and restart them on the surviving host(s) (aggressively or conservatively). Dell recommends taking the conservative approach seen in Figure 57.
Figure 57 APD datastore response for VMCP in the vSphere Client

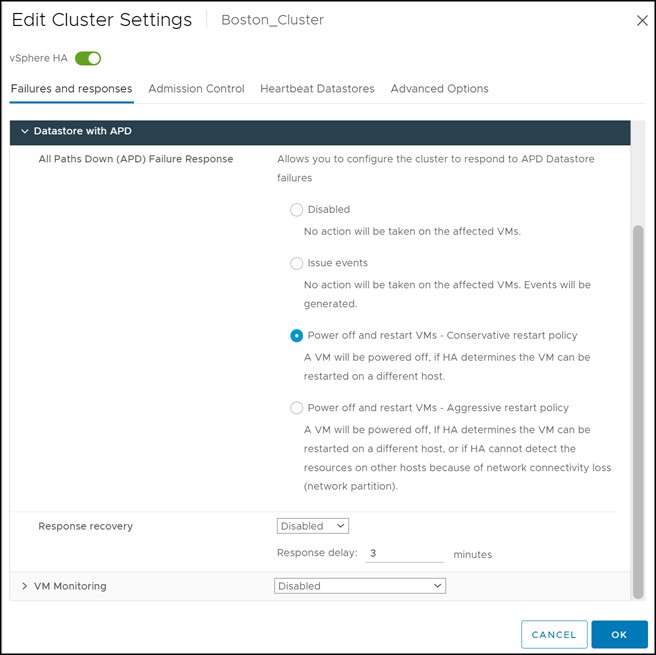
If issue events is selected, vSphere will do nothing more than notify the user through events when an APD event occurs. As such no further configuration is necessary. If, however, either aggressive or conservative restart of the VMs is chosen, as recommended, additional options may be selected to further define how vSphere should behave. The formerly grayed-out option “Response recovery” is now available and a minute value can be selected after which the restart of the VMs would proceed. Note that this delay is in addition to the default 140 second APD timeout. The difference in approaches to restarting the VMs is straightforward. If the outcome of the VM failover is unknown, say in the situation of a network partition, then the conservative approach would not terminate the VM, while the aggressive approach would. Note that if the cluster does not have sufficient resources, neither approach will terminate the VM.
In addition to setting the delay for the restart of the VMs, the user can choose whether vSphere should act if the APD condition resolves before the user-configured delay period is reached. If the setting “Response recovery” is set to “Reset VMs”, and APD recovers before the delay is complete, the affected VMs will be reset which will recover the applications that were impacted by the IO failures. This setting does not have any impact if vSphere is only configured to issue events in the case of APD. VMware and Dell recommend leaving this set to “Disabled” so as to not unnecessarily disrupt the VMs.
The configuration is seen in Figure 58.
Figure 58 Additional APD settings when enabling power off and restart VMs in the vSphere Client
As previously stated, since the purpose of HA is to maintain the availability of VMs, VMware and Dell recommend setting APD to power off and restart the VMs conservatively. Depending on the business requirements, the 3-minute default delay can be adjusted higher or lower.
Note: If either the Host Monitoring or VM Restart Priority settings are disabled, VMCP cannot perform virtual machine restarts. Storage health can still be monitored and events can be issued, however.
APD/PDL monitoring
APD and PDL activities can be monitored from within the vSphere Client or the ESXi host in the vmkernel.log file. VMware provides a screen in vSphere 6 and higher which can be accessed by highlighting the cluster and navigating to the Monitor tab and vSphere HA sub-tab. Here can be seen any APD or PDL events. Note that these events are transitory and no historical information is recorded. Since there is a timeout period, APD is easier to catch than PDL. Figure 59 includes an APD event in this monitoring screen for an FC-NVMe datastore in the vSphere Client.
Figure 59 APD/PDL monitoring in the vSphere Client

The other way monitoring can be accomplished is through the log files in /var/log on the ESXi host. Both APD and PDL events are recorded in various log files. An example of each from the vmkernel.log file is included in the single screenshot in Figure 60.
Figure 60 APD and PDL entries in the vmkernel.log

Avoiding APD/PDL
Though ADP and PDL events can be unexpected, there are times when they can be avoided with proper planning. VMware provides a process wherein datastores can be unmounted and then the underlying device detached from the ESXi host(s). At that point removing the devices on the PowerMax will cause no harm. The following sections will walk the user through the process.
Unmounting
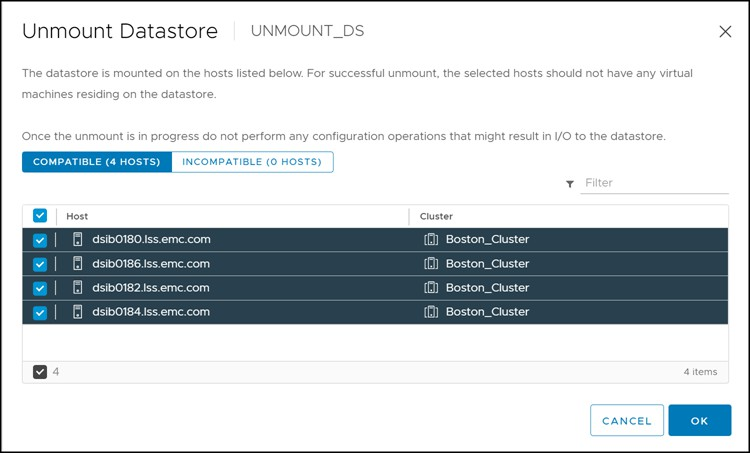
In the following example, the datastore UNMOUNT_DS seen in Figure 61, will be unmounted and the device associated with it detached in the vSphere Client. Before proceeding, make sure that there are no VMs on the datastore, that the datastore is not part of a datastore cluster (SDRS), is not used by vSphere HA as a heartbeat datastore, and does not have Storage I/O Control enabled. All these must be rectified before proceeding or an error will be generated.
Figure 61 Datastore UNMOUNT_DS
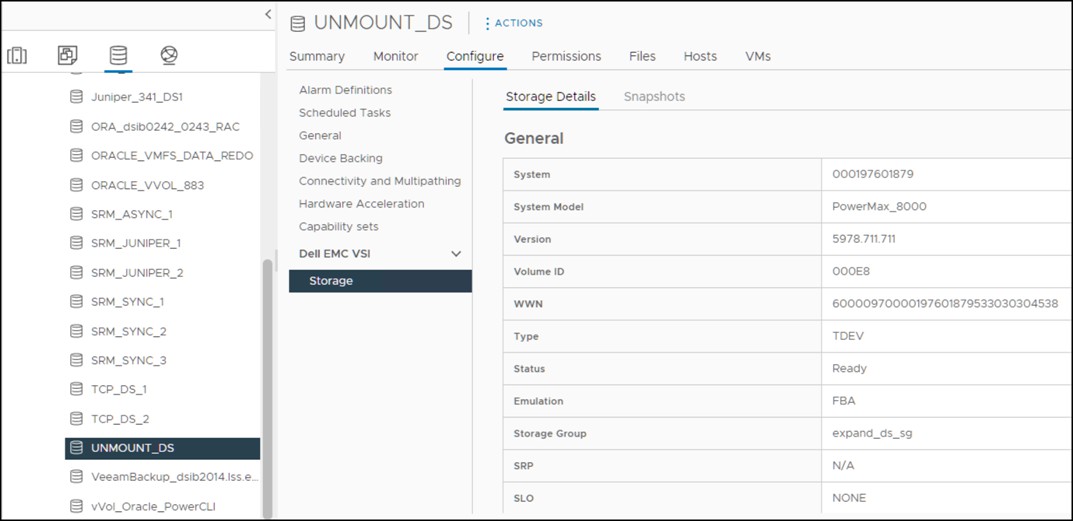
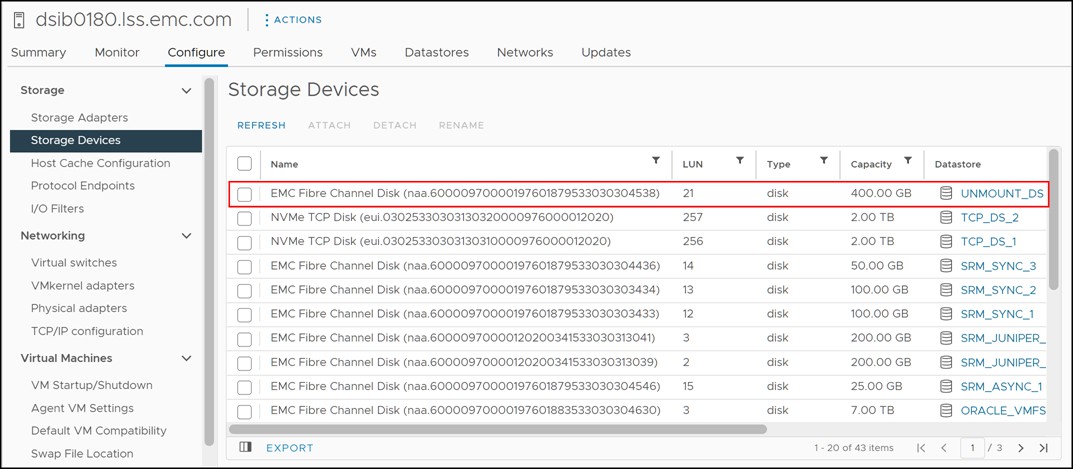
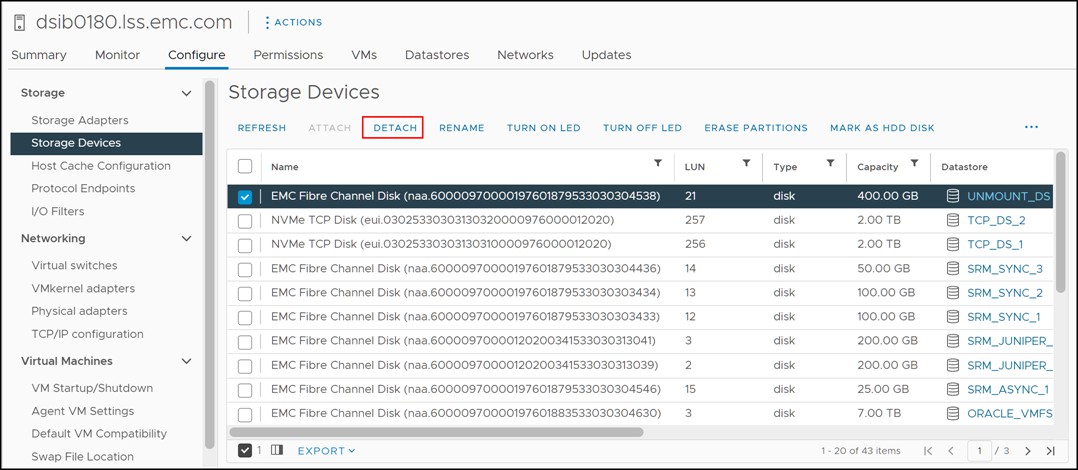
UNMOUNT_DS meets all these prerequisites so it can be unmounted. Be sure to record the naa. of the device as it will be needed when the device is detached. From an ESXi host navigate to Configure -> Storage -> Storage Devices and locate disk. Since each host may have a different LUN number only use the WWN. An example is show in Figure 62.
Figure 62 Underlying device identification of the datastore to be unmounted
Once the datastore is identified, right-click on the datastore and choose “Unmount” as shown in Figure 63. The unmount may also be accomplished through the CLI. The command to do an unmount is esxcli storage filesystem unmount from the ESXi shell.
Figure 63 Unmount datastore UNMOUNT_DS

A single screen follows with the unmount wizard which lists the conditions under which the datastore will not unmount. For instance, if a VM is running on the datastore or it is being used as an HA heartbeat it will fail. The unmount screen is seen in Figure 64.
Figure 64 The unmount wizard in the vSphere Client
VMware will check for violations such as registered VMs. If such a violation exists, the following error in Figure 65 will be generated and the unmount will fail.
Figure 65 An error attempting to unmount a datastore

Note: If there are multiple ESXi hosts in the cluster, VMware will attempt to unmount the datastore from each one. Only those hosts that are in violation will fail the unmount.
For those VMs in violation, unregister the VM or Storage vMotion it to another datastore. Once complete, the result will be an inaccessible datastore. This is shown in Figure 66.
Figure 66 Datastore unmount completion

Detaching
Once the datastore is unmounted, the underlying device needs to be detached from the ESXi hosts. Start by recalling the WWN gathered before the unmount (60000970000197601879533030304538). Once the device is identified in the Storage Devices of one of the hosts, select DETACH as in Figure 67.
Figure 67 Detaching a device after unmounting the volume
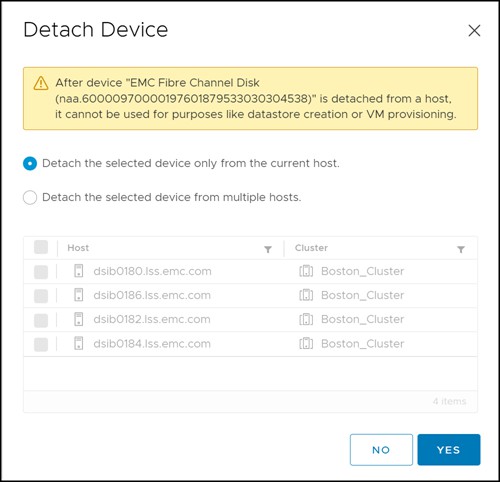
VMware will automatically show all the ESXi hosts where the device is presented. By default, the top radio button will be selected in Figure 68.
Figure 68 Detach device from single ESXi host
To detach the device from all ESXi hosts select the second radio button as in Figure 69.
Figure 69 Detach device from all ESXi hosts

Once detached, run a rescan of the ESXi hosts to remove the inactive datastore. Note that the device will remain in the device list as detached, shown in Figure 70, until the LUN is unmasked from the host and a second rescan is run.
Figure 70 Removal of inaccessible datastore

Removing the masking view on the PowerMax will complete the process, safely avoiding APD or PDL.
PDL AutoRemove
VMware has a feature called PDL AutoRemove. This feature automatically removes a device from a host when it enters a PDL state. The reason behind the feature is to avoid taking up a device slot on the ESXi host when it can no longer accept IO.
PDL AutoRemove occurs only if there are no open handles left on the device. The auto-remove takes place when the last handle on the device closes. If the device recovers, or if it is re-added after having been inadvertently removed, it will be treated as a new device. In such cases VMware does not guarantee consistency for VMs on that datastore.
In a vSphere Metro Storage Cluster (vMSC) environment, such as with SRDF/Metro, VMware recommends that AutoRemove be left in the default state, enabled. This is essential when using SRDF/Metro because if the PDL device is not removed, and a suspend action is taken on a metro pair(s), the non-biased side will experience a loss of communication to the devices that can only be resolved by a host reboot.