
Implementing MLOps
Implementing MLOps
-
MLOps is a defined process and life cycle for ML data, models, and coding. The MLOps life cycle begins with data extraction and preparation as the dataset is massaged into a structure that can effectively feed the model. Experimentation on the data then occurs as data scientists conduct short experiments to initially gauge the usefulness of the outcomes. Model training follows as the algorithm is given data to process and “learn.” Next, the outputs are evaluated and validated against the business objectives and expected outcomes. When the models are adjusted sufficiently, they can be deployed to start processing the data. Constant monitoring occurs along the way to ensure that the process is running smoothly. Automatic retraining can be implemented to help adjust the deployed process and tighten up the results with each iteration. (See the following figure.)
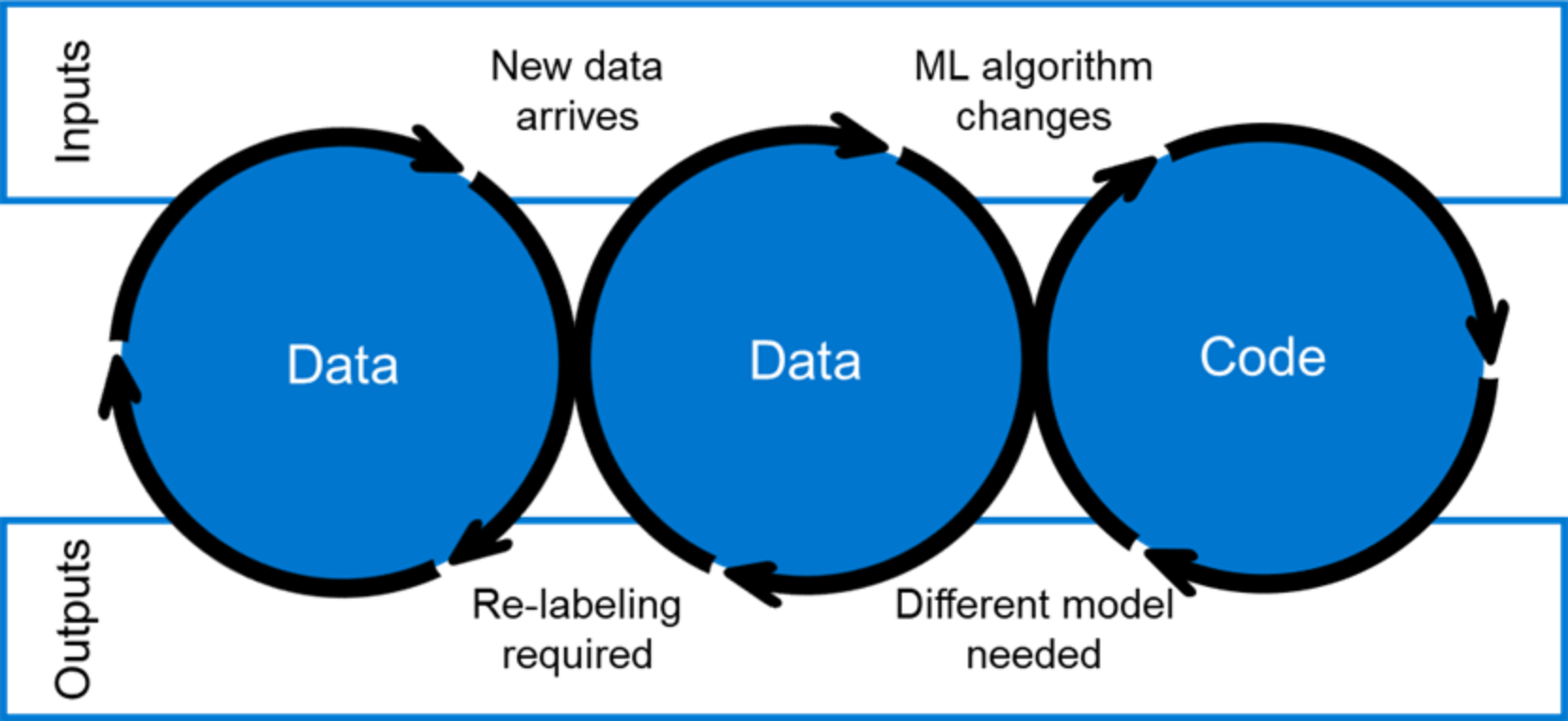
Figure 1. The MLOps pipeline
The primary goals of MLOps are (Source: ml-ops.org):
- Combining the ML platform, data, and software into a single, manageable release cycle
- Automating the testing of data, models and integration
- Introduction of Agile Principles into ML
- Treating ML models and datasets as first-class citizens in a CI/CD world
- Reducing technical variances across ML models
- Creating an agnostic environment concerning language, framework, platform, and infrastructure
A key difference between ML and traditional IT workloads is that ML tends to be more hardware- and platform-driven. ML, especially in DL use cases, has a wider range of underlying hardware types that can include more discrete compute elements. These compute elements include graphics processing units (GPUs) used in this case for general acceleration of highly parallelized analytics), tensor processing units (TPUs) used to support faster neural networks, and other specialized accelerator components. Because of this difference, MLOps needs to comprehend not only the classic data and compute models but must also comprehend more of the many compute elements that can underly each stage of the ML pipeline.
Another difference is that MLOps must go beyond the infrastructure and application focus of DevOps. A proper MLOps structure needs to address all three domains of machine learning: data, ML models, and code.