
Splunk distributed clustered deployment
Splunk distributed clustered deployment
-
The Splunk solution is deployed on a hyperconverged deployment with PowerFlex rack. As per Splunk validated architectures (SVA) document, for 50 GB/day ingestion volume, single instance deployment is recommended. In this solution, to demonstrate the Splunk enterprise distributed clustered deployment, a multi-instance setup with replication and search factor of 2 is used. For more details about SVA, see Splunk Validated Architectures.
The following table provides the configuration details used in Splunk deployment:
Table 2. Configuration details
Sizing
50 GB/day clustered
Retention(hot/warm)
30 days
Number of PowerFlex Nodes
4
Compute
PowerEdge R640 Servers
CPU
2 x Intel Xeon (24C,2.70 GHz)
Memory
384 GB
Storage
10 x 3.84 TB SSDs
Network
25 GbE Cisco Nexus
Hot/warm Storage
1 TB
Cold Storage
Configurable
PowerScale
A200
For detailed configuration information about Splunk Clustered deployment on PowerFlex rack, see Hardware and Software components.
The following figure provides an overview of the logical architecture of Splunk enterprise distributed clustered deployment on PowerFlex rack for 50 GB/day ingestion volume with 30-day hot/warm and configurable cold data retention using PowerScale:
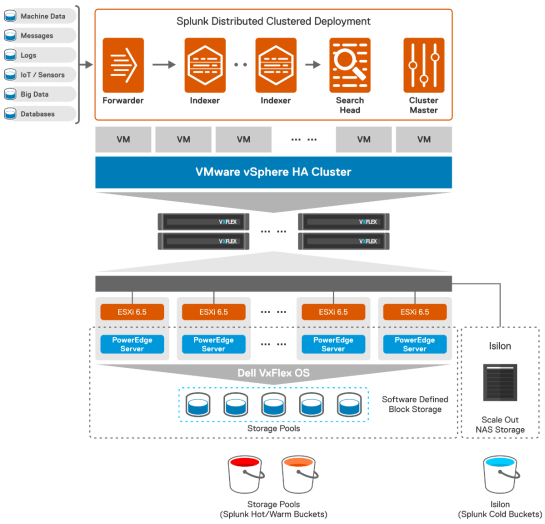
Figure 3. Logical Architecture of Splunk Enterprise distributed clustered deployment-single site
The PowerFlex rack HCI is configured with ESXi hypervisor for compute, network, and PowerFlex (previously VxFlex OS) for software-defined storage. Hyperconverged infrastructure configuration has SDC and SDS role that is configured on each node of the cluster. SDC provides the compute capabilities while SDS provides backend storage.
The Storage Data Server (SDS) aggregates the raw local storage in a node and serves it up as PowerFlex storage. A single protection domain is carved out of SSD drives on these four SDS nodes. A single storage pool is configured, and multiple volumes were carved out to meet the Splunk requirements. These volumes are mapped to the ESXi cluster and added as a datastore and later mapped as disks drive to Splunk virtual machine using VMware Paravirtual SCSI (PVSCSI) adapters.
Each PowerFlex rack node has a Dell Storage Virtual Machine (SVM) running on it, providing both storage clustering and storage services.
In this solution, 50 GB log data has forwarded using the universal forwarder to indexer cluster, where the log data gets indexed and resides in hot bucket.
The search head helps you to search indexed data available in the hot/warm bucket. Once the retention exceeds the 30-day period, the data moves to PowerScale cold bucket.