
Splunk Enterprise
Splunk Enterprise
-
Splunk Enterprise is a software product that enables enterprises to collect, search, organize, analyze, and visualize data that is gathered from various system components. Splunk Enterprise ingests log and streaming data from a wide variety of sources, including websites, applications, sensors, and devices. From each data source, Splunk Enterprise indexes the data stream and parses it into a series of individual events that you can view and search. The Splunk web interface can be used to analyze the data further. The Splunk search language, lookups, macros, and sub searches reduce hours of tedium to seconds of simplicity and tags, saved searches, and dashboards offer both operational insights and collaborative vehicles.
The following figure provides an overview of the Splunk system architecture. A Splunk Enterprise instance can perform the role of a search head, an indexer, or both in small deployments. When the daily ingest rate or search load exceed the sizing recommendations for a combined instance environment, Splunk Enterprise scales out horizontally by adding additional indexers and search heads. For more information, see the Splunk Capacity Planning Manual.
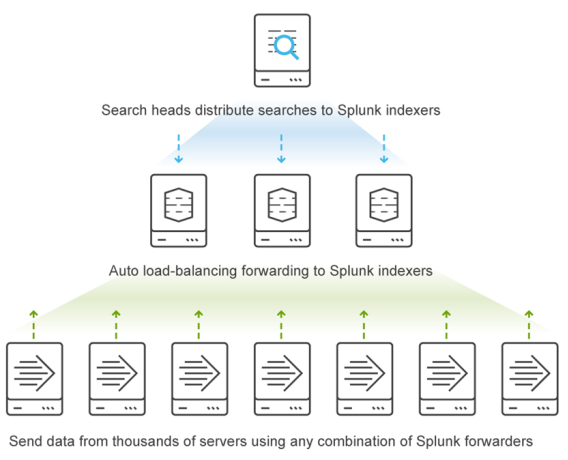
Figure 3. Splunk architecture overview
When a Splunk Enterprise indexer receives data, the indexer parses the raw data into specific events based on the event's timestamp and writes them to the appropriate internal index. Splunk implements a form of storage tiering involving hot/warm and cold buckets of index data to optimize performance for newly indexed data and provide an option to keep older data for more extended periods on higher capacity storage.
Newly indexed data lands in a hot bucket, where it is actively read and written by Splunk. When the number of hot buckets is reached, or when the size of the data in the hot buckets exceeds the specified threshold, the hot bucket is rolled to a warm bucket. Warm buckets reside on the same tier of storage as hot buckets. The only difference is that warm buckets are read-only. The storage that is identified for hot/warm data must be your fastest storage tier because it has the most significant impact on the performance of your Splunk Enterprise deployment.
When the number of warm buckets or volume size is exceeded, data is rolled into a cold bucket, which can optionally reside on another tier of storage. Cold data can reside on an NFS mount if the latency is less than 5 ms (ideally) and not more than 100 ms for indexers or 200 ms for search heads. PowerScale storage, in particular the Isilon Archive nodes, offers an acceptable blend of performance and lower cost per TB, making it a good choice for longer-term retention of cold data.
Data can also be archived or frozen, but the data is no longer searchable by Splunk search heads. Manual user action is required to bring the data back into Splunk Enterprise buckets to be searchable. While you might choose to use frozen buckets to meet compliance retention requirements, this guide shows how the Isilon H500 massive scalability and competitive cost of ownership can empower you to retain more data in the cold bucket, where it remains searchable. The following figure provides more details about Splunk bucket concepts:
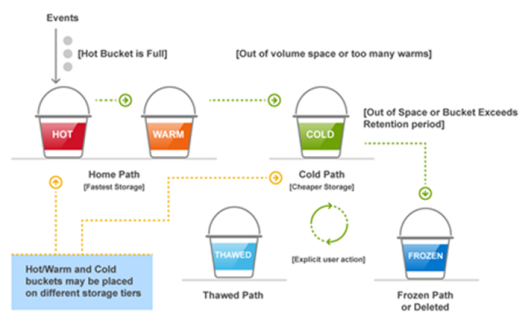
Figure 4. Splunk index buckets
Using this efficient and tunable index placement strategy, Splunk turns silos of data into operational insights and provides end-to-end visibility across your IT infrastructure to enable faster problem solving and informed data-driven decisions.