
Core environment
Core environment
-
Figure 12 illustrates the primary functional components at the core.
Core infrastructure
The core environment runs under Red Hat OpenShift Container Platform (OCP). The recommended infrastructure for the core environment is covered in Core configurations.
OpenShift is used in the core to provide the flexibility and scalability that is required to support multiple edge locations. The Confluent Platform components are run under OpenShift using the Confluent Operator for Kubernetes. With the operator, the streaming platform can be managed as a cloud-native application with resiliency and elastic scaling. Scaling the Kafka brokers to handle the load from multiple edge sites becomes straightforward.
OpenShift also runs the various tools and utilities that are needed for the data science environment. This solution provides a large amount of flexibility since most of the widely used machine learning tools that are run as cloud-native applications and in containers.
OpenShift supports the Kubernetes container storage interface (CSI). This design allows many internal and external storage systems to be used for dynamic and persistent storage. The lab environment used a Dell EMC Isilon H600 system, with dynamic storage provisioned using the Network File System (NFS) protocol. Isilon with HDFS was also used to host the data lake and to store the Kafka topic data replicated from the edge locations.
Core connectivity
The architecture uses connectivity to the core from all edges to consolidate data.
The details of the connection are site and installation-specific. The connection should have enough bandwidth to support the volume of data coming all the edge locations. In general, the connection is not latency sensitive since alerts are processed at the edge. Depending on the data rate, oversubscription of the bandwidth may be appropriate in instances where data from the edges occurs in bursts because of production schedules.
All connections between the core and the edges should be firewalled for security.
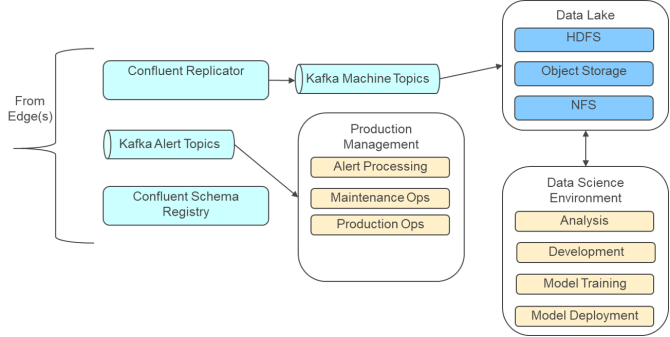
Data flow
Data at the edge is stored in Kafka topics. Since Kafka also runs in the core, this design provides a lot of flexibility in how data moves to the core.
In this architecture, Confluent Replicator is used to copy the topic data from the edges to the core. The data is written to an HDFS file system in the data lake, which provides a copy of the edge data for data protection. The data is also available to the data science environment for analysis and model development. In the development lab environment, a custom version of the cp-server-connect-operator image from Confluent Operator was needed. This customization added kafka-connect-replicator, kafka-connect-hdfs, and kafka-connect-hdfs2-source to the base image.
The alert topics from each edge location can also be streamed to the core. This information can be used to analyze model behavior and for additional alert processing in the core.
After models have been developed and tested or refined, they can be pushed out to the edges to the KSQL nodes for execution.
Data lake
The architecture supports a data lake to store the data from the edges so it can be analyzed. The data lake is hosted outside the OpenShift environment, and is typically an HDFS compatible file system such as a Hadoop cluster or an Isilon system. The lab testing environment used an Isilon H600 with HDFS. Since HDFS is a network file system protocol, the data lake can be accessed directly from any containers that are hosted in the OpenShift environment without any additional configuration beyond authentication. The HDFS protocol is also supported directly by most data science tools, making it a good choice for the data lake.
Data science environment
The architecture supports a wide variety of machine learning and data science tools. Since the core infrastructure is based on Kubernetes, most of the widely used data science tools are available. The choice of data science tools often depends on developer, data scientist and use case specifics. The architecture deliberately does not select any specific tool chain. Rather, it is designed to allow flexibility and evolution, while allowing the use of modern DevOps and MLOps workflows.
The development lab environment used MLFlow to manage the machine learning life cycle. It used a PostgreSQL database under OpenShift to host the MLFlow metadata, and HDFS to store MLFlow artifacts. During development, the MinIO S3 compatible storage system was also used for artifacts, with MinIO running under OpenShift.
In the development lab environment, the models were developed using TensorFlow and Keras. Java was used to develop a KSQL user-defined function. The Java API for TensorFlow was used to call the model from the KSQL user-defined function.
Since the Confluent Platform runs in the core, the models and user-defined functions can be tested and validated in the data science environment at the core before they are release to production and pushed to the edge.
Production management
Note: Production management represents the systems used by the operational technology team.
The architecture supports interfaces to a production management environment for the industrial equipment. Since the production management system is specific to each deployment, the architecture does not specify it. This system can be hosted under OpenShift or can be external to the OpenShift environment.
If the production management system provides an API, alerts and other relevant information can be forwarded to it from the topics using the Kafka Streams API and custom interface programs.