
Job Engine architecture
Job Engine architecture
-
The OneFS Job Engine runs across the entire cluster and is responsible for dividing and conquering large storage management and protection tasks. It reduces a task into smaller work items and then allocates, or maps, these portions of the overall job to multiple worker threads on each node. The Job Engine tracks and reports on progress as the job runs and provides a detailed report and status upon completion or termination.
The Job Engine includes a comprehensive check-pointing system that allows jobs to be paused and resumed, in addition to being stopped and started. The Job Engine framework also includes an adaptive impact management system, drive-sensitive impact control, and the ability to run multiple jobs at once.
The Job Engine typically runs jobs as background tasks across the cluster, using spare or specially reserved capacity and resources. The jobs themselves can be categorized into three primary classes:
- File System Maintenance Jobs—These jobs perform background file system maintenance, and they typically require access to all nodes. These jobs are required to run in default configurations and often in degraded cluster conditions. Examples include file system protection and drive rebuilds.
- Feature Support Jobs—The feature support jobs perform work that facilitates some extended storage management functions, and they typically run only when the feature has been configured. Examples include deduplication and anti-virus scanning.
- User Action Jobs—These jobs are run directly by the storage administrator to accomplish some data management goal. Examples include parallel tree deletes and permissions maintenance.
Although the file system maintenance jobs are run by default, either on a schedule or in reaction to a particular file system event, any Job Engine job can be managed by configuring both its priority level in relation to other jobs (as discussed in Job priority) and its impact policy (as discussed in Job impact policies).
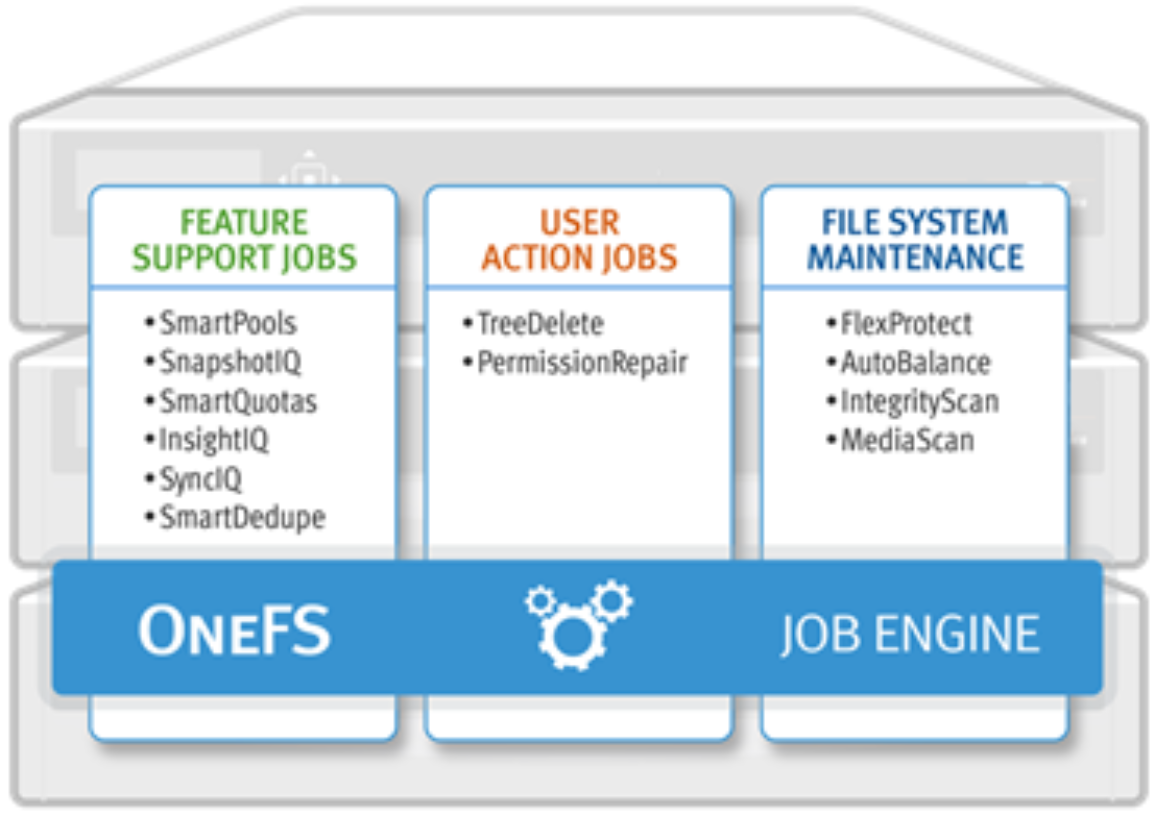
Figure 1. OneFS Job Engine primary functions