
Multinode training
Multinode training
-
The growth of deep learning models with different scaling approaches has been critical for better and faster model generalization, convergence, and quality of service. These results are made possible with multinode multi-GPU runs and different data and parameter sharding techniques.
The following graph from Microsoft research[1] shows the growth of these large NLP models:
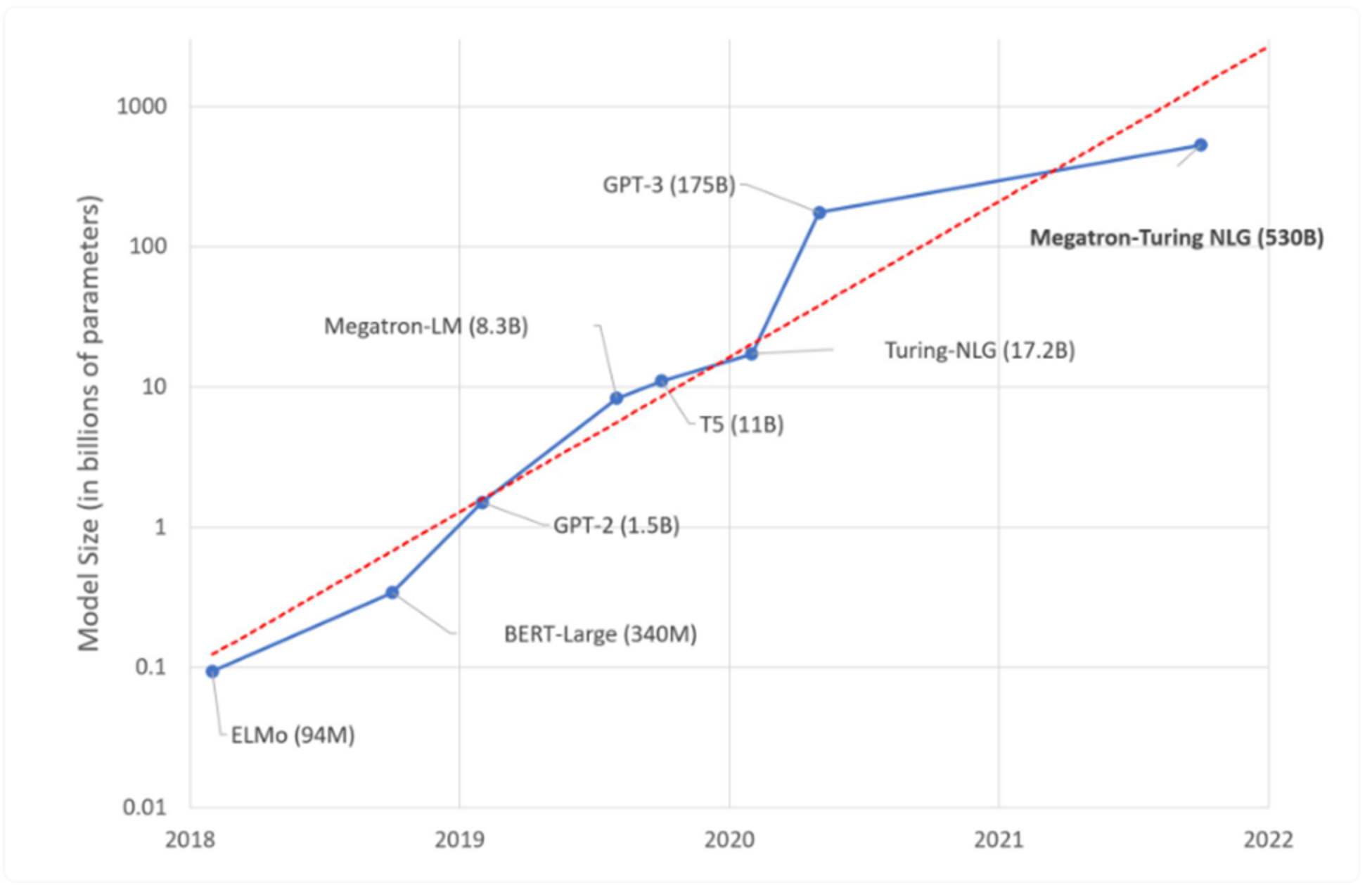
Figure 17. Large parameter models growing at an exponential rate
The dotted red line shows the expected trend. These models demonstrate breakthroughs at different levels. These breakthroughs are possible because of multinode and multi-GPU training with advanced algorithmic speedup approaches that are enabled by optimizing different stacks of workload training. The number of model parameters are growing at an exponential rate. This growth provides enormous optimization opportunities across the stack. For an optimization example, see Scaling Language Model Training to a Trillion Parameters Using Megatron. Also, for more information about other optimization techniques in the software stack for MLPerf v2.0, see The Full Stack Optimization Powering NVIDIA MLPerf Training v2.0. MLPerf.
To measure the effectiveness of delivering something similar for customer workloads at their data centers, it is imperative to showcase the multinode scaling results of the MLPerf training closed division so that comparisons can be made. Therefore, we have made the effort to demonstrate multinode results.
We used the following multinode systems, using the syntax described in a previous section, for testing:
- 2xXE8545x4A100-SXM-40GB
- 4xXE8545x4A100-SXM-40GB
- 8xXE8545x4A100-SXM-40GB
- 16xXE8545x4A100-SXM-40GB
- 32xXE8545x4A100-SXM-40GB
- 2xXE8545x4A100-SXM-80GB
- 4xXE8545x4A100-SXM-80GB
The following figures show the performance of multinode submissions:
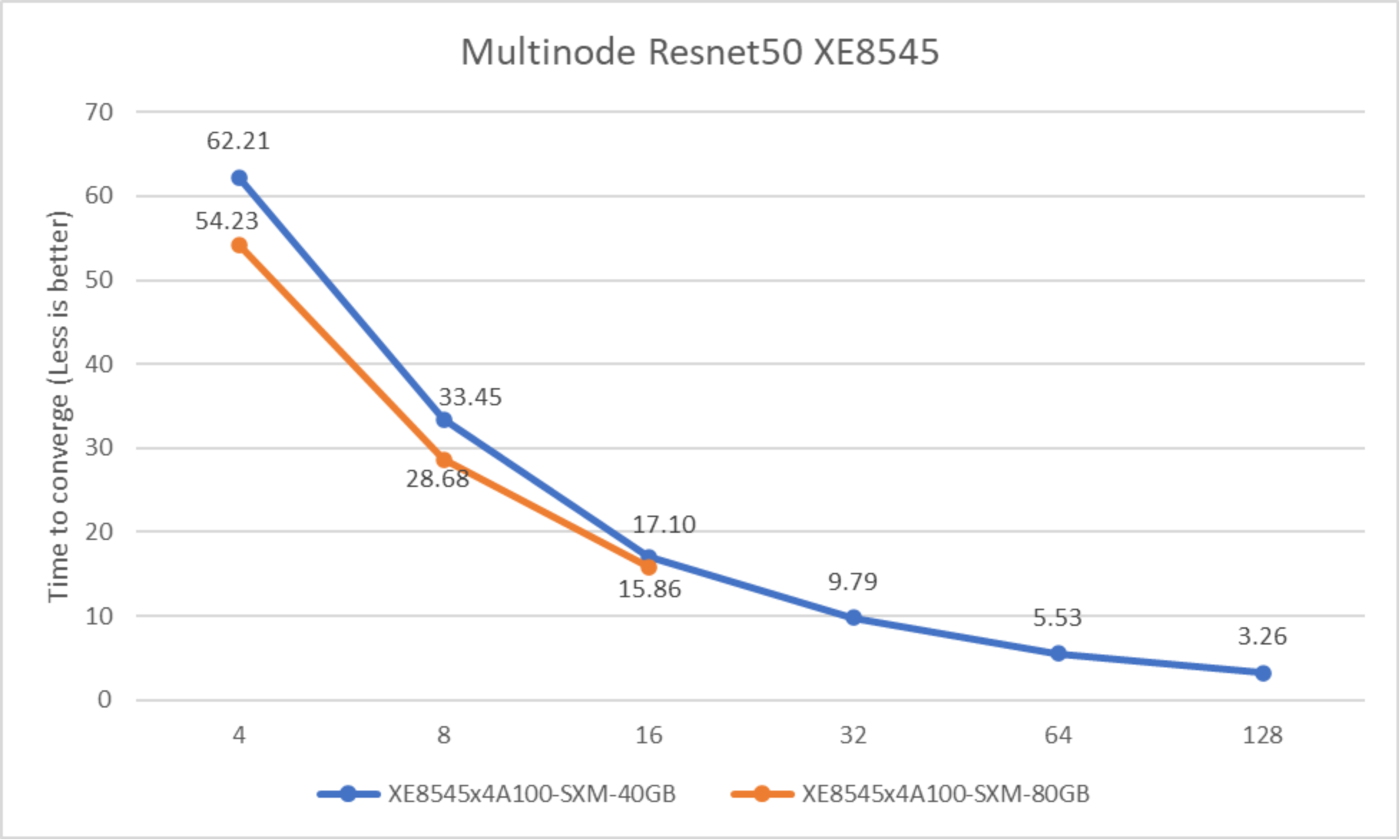
Figure 18. Performance of multinode PowerEdge XE8545 servers for ResNet50 v1.5 comparing A100-40GB and A100-80GB accelerators
The preceding figure demonstrates scaling PowerEdge XE8545 servers for the Resnet50 workload from four GPUs to 16 GPUs for the 80 GB version of the accelerator and four GPUs to 128 GPUs for the 40 GB version. The A100-80GB-SXM accelerator reaches convergence faster than the 40 GB version.
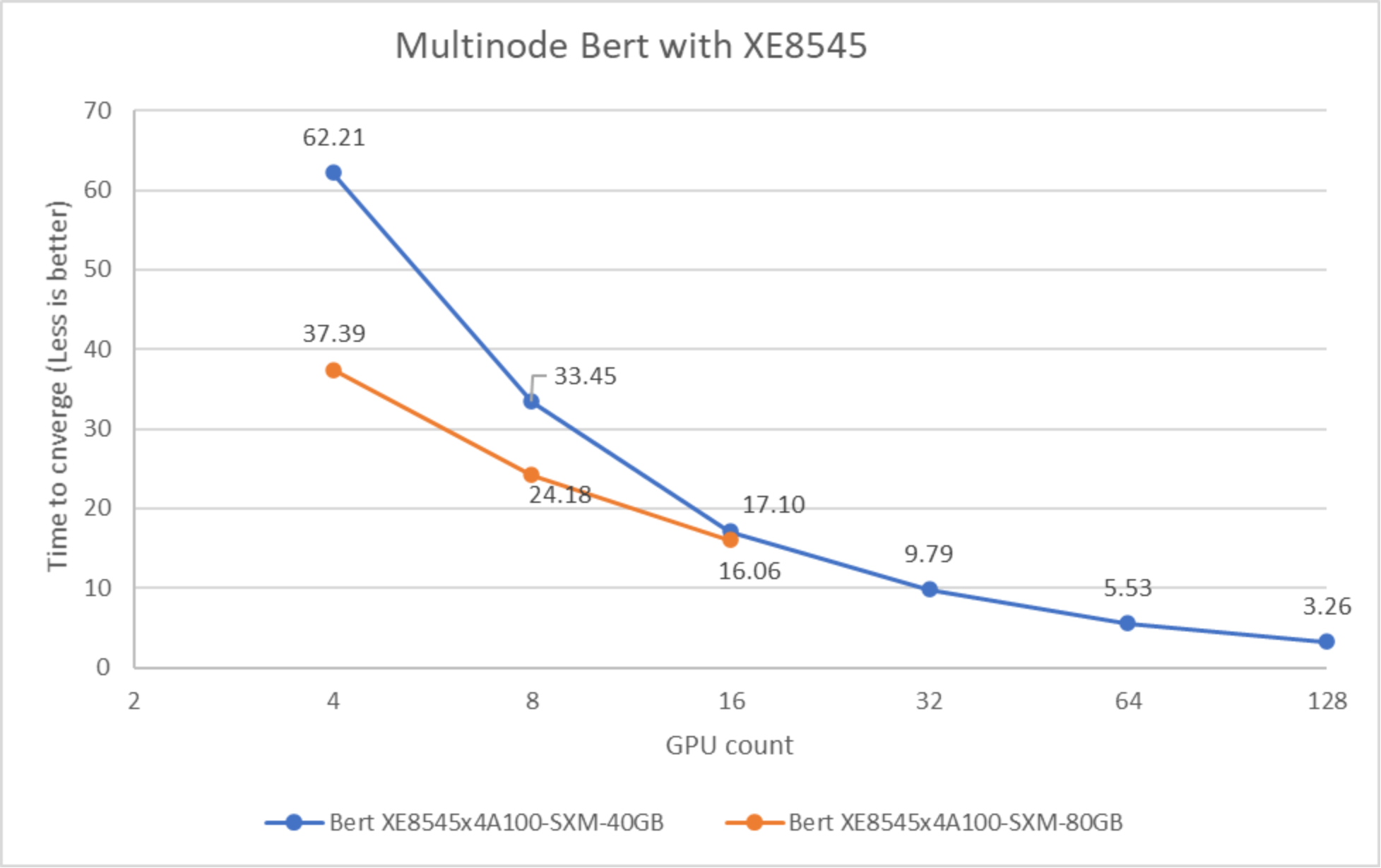
Figure 19. Performance of multinode PowerEdge XE8545 servers for BERT with A100-40 compared to A100-80G accelerators
The preceding figure shows the scaling performance of the BERT workload from four GPUs to 128 GPUs. Adding more compute helps to reach convergence faster. A model like BERT has significant multi-GPU communication; adding more GPUs to solve the problem is useful for enabling faster time to convergence.
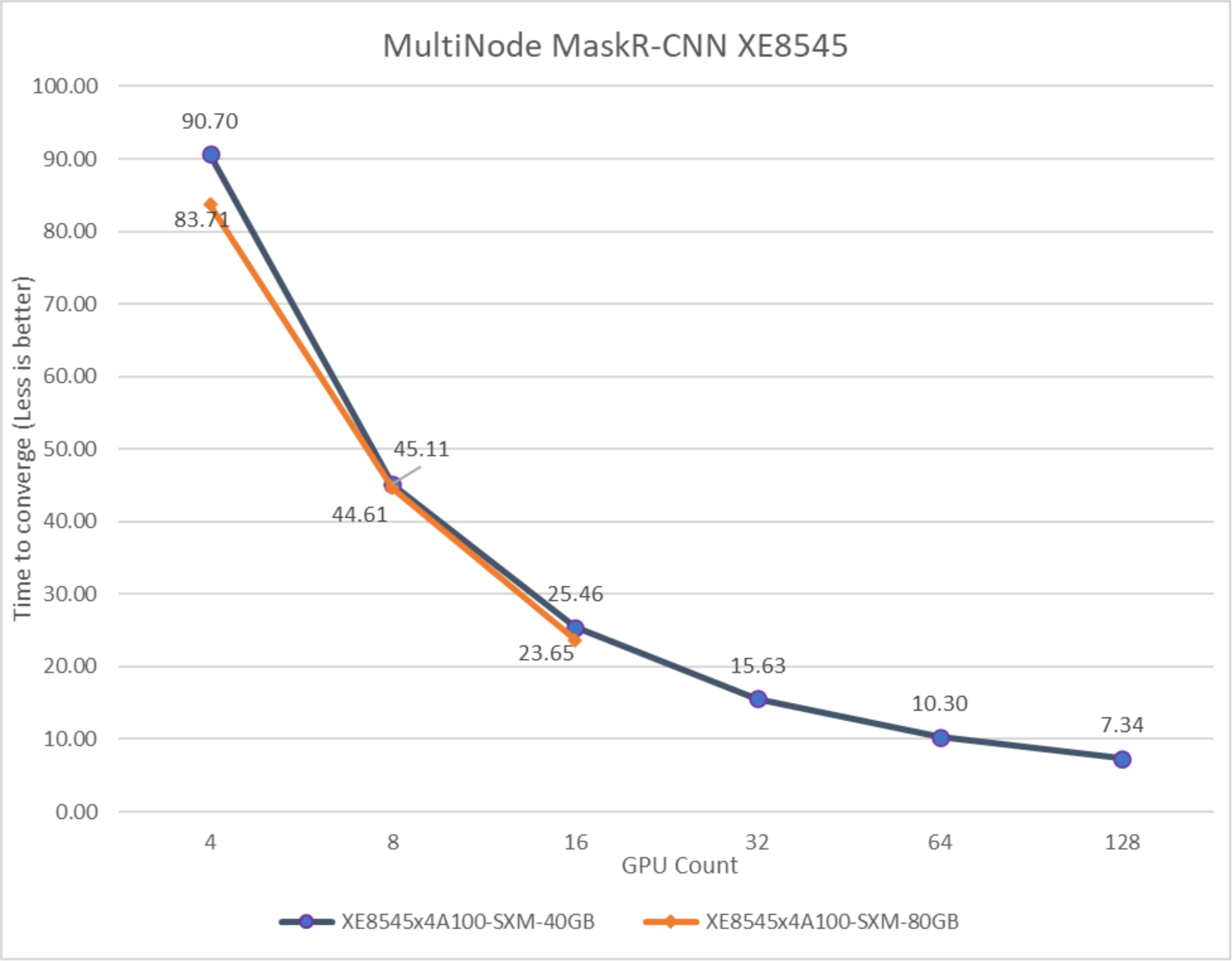
Figure 20. Performance of multinode PowerEdge XE8545 servers for MaskR-CNN with A100-40 vs A100-80G accelerators.
The preceding figure demonstrates the scaling performance of the MaskR-CNN workload from four GPUs to 128 GPUs. Adding more compute helps to reach convergence faster.
All the multinode scaling results show linear or nearly linear scaling and enable users to derive faster time to convergence and higher performance with the addition of more servers and GPUs. These results make Dell servers with NVIDIA GPUs excellent choices to accelerate deep learning workloads. MLPerf training requires passing Reference Convergence Points (RCP) for compliance. These RCPs were inhibitors to show linear scaling in many cases.