
Replication process
Replication process
-
PowerFlex replication can be used to quickly resume operations remotely after disaster at the local site, to test data at a remote site, to create remote crash-consistent snapshots or to offload backup. PowerFlex has designed replication to allow a sub-minute RPO, reducing the data-loss to be as minimal as possible in the case of a disaster. Replication occurs between two PowerFlex systems, designated as peer systems, which are connected by WAN. PowerFlex achieves replication using newly introduced storage component called the Storage Data Replicator (SDR).
The role of the SDR is to proxy the I/O of replicated volumes between the SDC and the SDSs where data is ultimately stored. It splits write I/O, sending one copy to the SDS nodes in local system and another to a replication journal volume. As it sits between the SDS and SDC, from the point-of view of the SDS, the SDR appears and behaves as an SDC, that is to say, the SDR is sending incoming writes to the SDS and then receiving write acknowledgements from the SDS. Conversely, to the SDC, the SDR appears as, and behaves as, an SDS, to which writes can be sent.
The following figure shows the architecture of PowerFlex asynchronous replication:
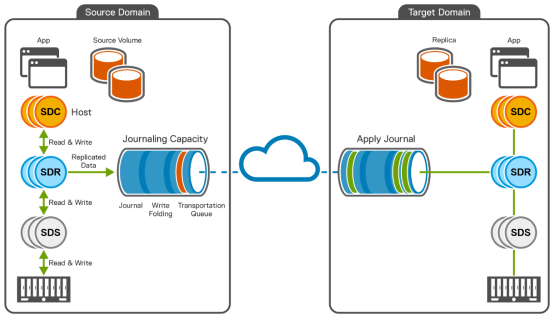
Figure 2. PowerFlex asynchronous replication between two PowerFlex systems
As shown in the figure, there are two PowerFlex clusters, namely the source domain and the target domain. Both systems are distributed using the network. Each cluster can act as a replication source and as a target. All application I/O of replicated volumes are processed by the source SDRs. The source SDC, sends the write I/O traffic to the SDR. The SDR then splits the I/O and forwards it to both the local SDS and the replication journal volume. The local multiple SDS process these write I/O normally, while the SDR assembles the journal data into checkpoints that each represent a point of consistency preserving the write order fidelity. Write I/O traffic of non-replicated volumes passes directly from SDC to SDS. The journal is a component of the SDR which stores data at source before it is sent to the target and at the target, journal stores the data before it is applied to target volumes.
On the source system, journals are accumulated in journal-intervals, or checkpoints. At the end of the collection interval, the checkpoint is closed, and a new journal-interval opens (a new checkpoint). As they near the head for the queue, the journal-intervals are scanned, and writes to the same blocks are consolidated (a process called write folding) to minimize the amount of data sent. These journal-intervals are then sent continuously to the remote system’s target journal buffer over dedicated networks assigned to replication.
On the target system, the journal-intervals are processed by the SDRs residing in the target system. Once all the data for a journal-interval (checkpoint) is received, the data is applied to the target volume by the relevant SDS. After all writes to target volume complete by remote SDS, the SDS will then send acknowledgment back to the SDR, which will then proceed to send the next complete journal-interval.