
Measuring system performance
Measuring system performance
-
MLCommons™ aims to provide a testing suite to support “like-to-like” comparison between submitters in their “closed” division. MLCommons™ enables like-to-like comparison by enforcing strict rules to which the submitters must adhere. Key rules include reproducibility by incorporating determinism for different deployment scenarios, ensuring all submissions meet the expected target accuracies, and testing for compliance of the submissions to rules.
The following figure shows the six models in the official v1.0 release for the Datacenter benchmarks suite. Those benchmarks highlighted in the blue rectangles are officially submitted and verified by MLPerf. The other benchmarks, such as 3D UNet and DLRM, are results generated after submission. All benchmarks are in the Closed division.
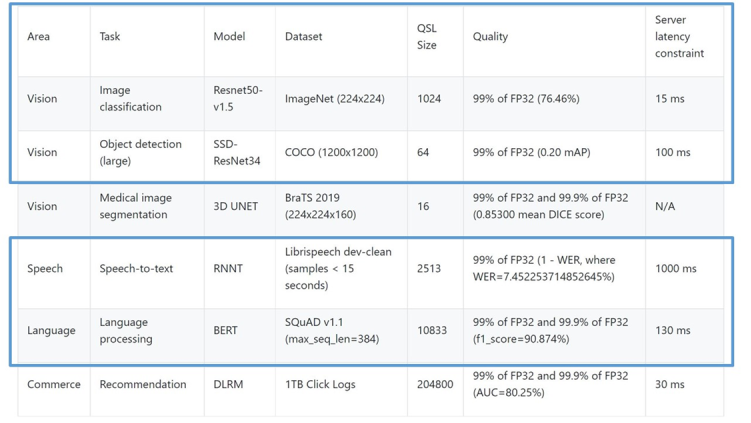
Figure 4. Closed Datacenter Suite Benchmarks from MLCommons™