
Introduction
Introduction
-
Deep Learning (DL) applications have become pervasive in application domains in various fields of science and technology [1], which have been increasingly dependent on DL methods for regression and classification tasks. Furthermore, recent advances in the computer architecture, especially with the advent of custom accelerators for Machine Learning (ML) based computations, have significantly accelerated model training and inference times. Higher model training and inference performance has led the application developers to train more complex models, and/or train on much larger training datasets in order to create better DL models. However, one common limitation in training such complex models is the high memory consumption. Depending on the network hyper-parameters such as number of layers, batch size, input data dimensions, floating point precision, and underlying framework implementation (such Tensorflow, PyTorch, and so on), memory consumption can quickly escalate beyond the capacity limitation provided by the underlying hardware. Figure 1 shows the peak memory consumed by a DL network called 3D U-net, trained to perform semantic segmentation on high resolution 3D brain MRI scans for brain tumor detection. As shown in the figure, with the increase of the input image dimensions and batch size, the peak memory consumption can quickly escalate toward and beyond 1TB, making it unfeasible to run on a single accelerator (for example, GPU) on most compute nodes.
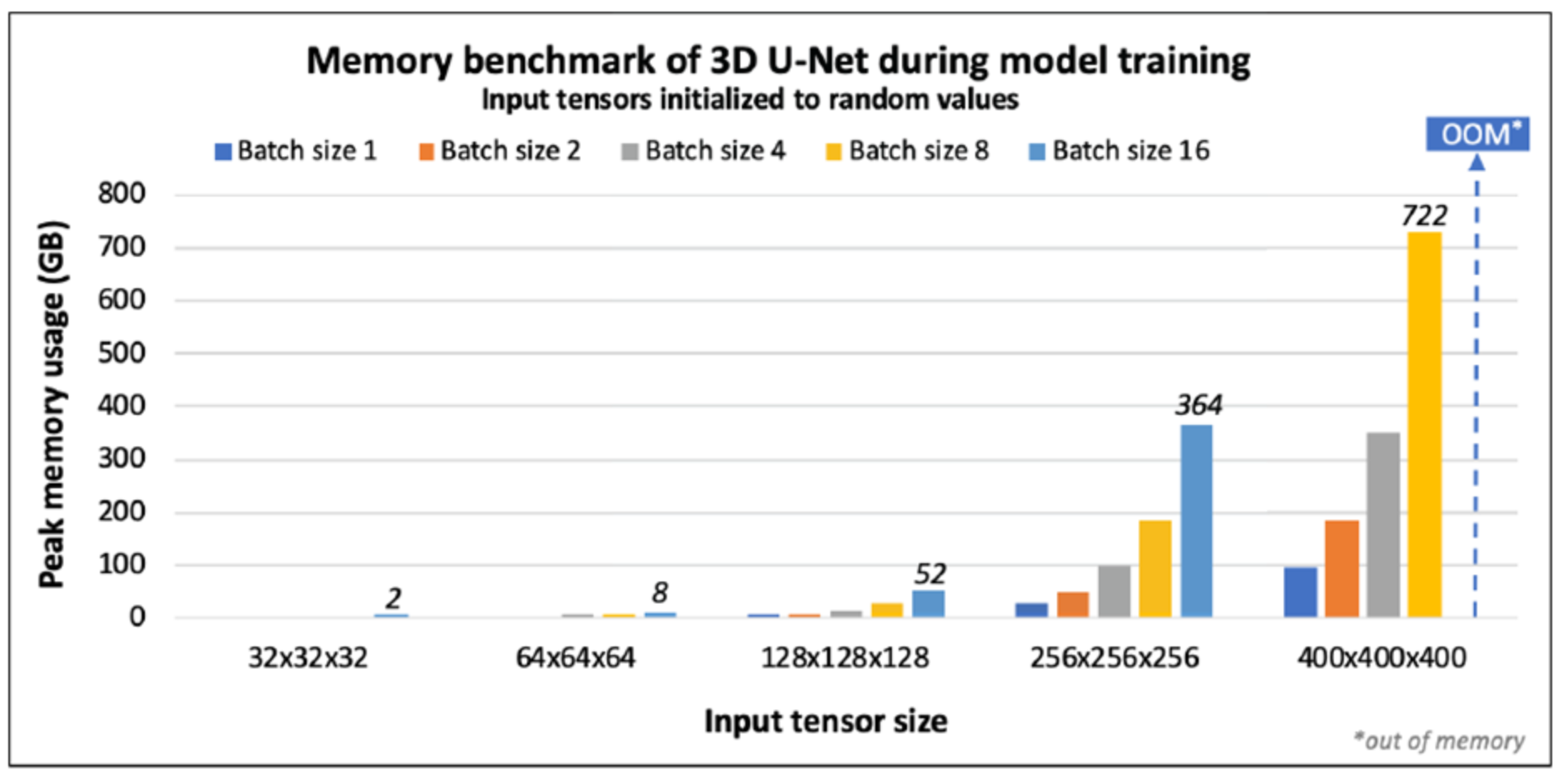
As mentioned previously, in memory-intensive DL workloads such as 3D U-net, the memory being consumed often exceeds the available system resources. Therefore, running the model training task without the proper knowledge on its memory requirement would result in poor utilization of the computing resources due to frequent OutOfMemory errors. In fact, a recent empirical study [2] performed to analyze the common DL workload job failures that occurred on a Microsoft Cloud platform revealed that close to 9% of the job failures are caused by OutOfMemory errors, where the jobs consume more than the available amount of memory. Due to the nature of these applications, these errors occur during the runtime, resulting in loss of valuable compute hours and a need to rerun the application with additional memory resources. Accurately estimating memory needs of memory-intensive DL workloads is therefore crucial in order to make efficient use of the underlying compute resources.
To successfully train a Deep Learning workload on a given computing resource without exceeding the memory capacity limitation, it is valuable to develop a model to estimate the peak memory consumption for a given DL network configuration. Generating a reliable memory consumption model for DL workloads has multiple advantages. Firstly, by reliably capturing the memory consumption prior to execution we can run the largest possible application configuration on the given system resources. Secondly, while scaling the model training onto multiple nodes, a common phenomenon while training large-scale DL workloads, identifying the peak memory consumption prior to runtime can help distribute the workload in an optimal manner, thereby achieving peak throughput. However, reliably predicting the memory consumption prior to runtime is a non-trivial task for application developers. As mentioned before, memory consumed during the model training phase depends on various parameters such as the network architecture, batch size, input dimension of the training data, data precision, and so on.
In this paper, we present a multi-parameter modeling approach to generate analytical models that accurately predicts the peak memory consumption of a Deep Learning workload. In the next section, we present a DL application, 3D U-net as our case study. First, we perform a memory characterization of 3D U-net, identifying key parameters that contribute to its high memory consumption. As a baseline, we then generate a basic analytical model by studying the network architecture to estimate memory requirements. We will show how a model generated by studying the network architecture falls short of accurately predicting the runtime memory consumption, thereby highlighting a need for a better modeling approach for generating a memory consumption model.
In the section Modeling methodology we present our modeling approach, which leverages symbolic regression principles [5] to generate a multi-parameter model capturing the impact of key application parameters on memory consumption. As shown in Model evaluation, using a small number of training samples from the 3D U-net case study, our modeling approach was able to generate memory consumption models that produced predictions that are less than 5% Mean Absolute Percentage Error (MAPE) when validated against untrained data points. We also compared our model approach against models generated from other machine-learning based regression methods, demonstrating the superior accuracy of our modeling approach.