
Near Real-time Prediction Service
Near Real-time Prediction Service
-
The objective of the model prediction service is to provide model predictions to the business CRM application on demand.
As the same model is used in the batch pipeline and for the service, it is necessary to focus on the reusability of the model. Independent from the service to which the model is imported, the model must be able to be ported to the service to ensure that the same version of the model is maintained for use-cases. A wheel file (.whl) has been created and stored in Dell’s private Python Package Index (PYPI) repository to be an artifact for the model. This package could be installed in the service environment. During the build stage of the service, it draws that artifact and package it with the other dependencies.
To deliver the service, the service performance, compatibility, and portability has been considered. For performance, the service needs to respond to requests within seconds, even at times of increased load. To integrate with the business CRM system, the service must be available over a compatible interface. To future proof the service, this interface must be industry standard. And finally, the service must be portable to different infrastructures with minimal effort.
In reverse order, to develop a service that can be ported from one environment to another, the service was built into a Docker container. Container services are widely available within Dell Technologies and with third-party vendors. The container is currently deployed to a Pivotal Kubernetes Service (PKS), a container-based environment. To integrate with the business application, an HTTP RESTful interface is exposed, an industry standard protocol and design style, which abstracts from the implementation details of the model service. To develop a service that responds within latency requirements, the service start-up time delay by loading model implementations from disk had to be considered. Thus, by using Uvicorn, an Async web server, it was mitigated as much as possible. It is worth noting that, while most of the computation is CPU bound, in the filtering stage the compute may be Input/Output (IO) bound as it communicates with an external language detection service depending on the service configuration. To scale at peak load, Kubernetes and Gunicorn are used to perform with horizontal scaling.
For the model artifact creation and container build, it is mandatory to make sure the artifacts generated do not violate the security standards of Dell Technologies. So, the CI/CD pipeline that does the security checks for the model artifact and the service container is put in place.
The following figure shows the model service architecture:
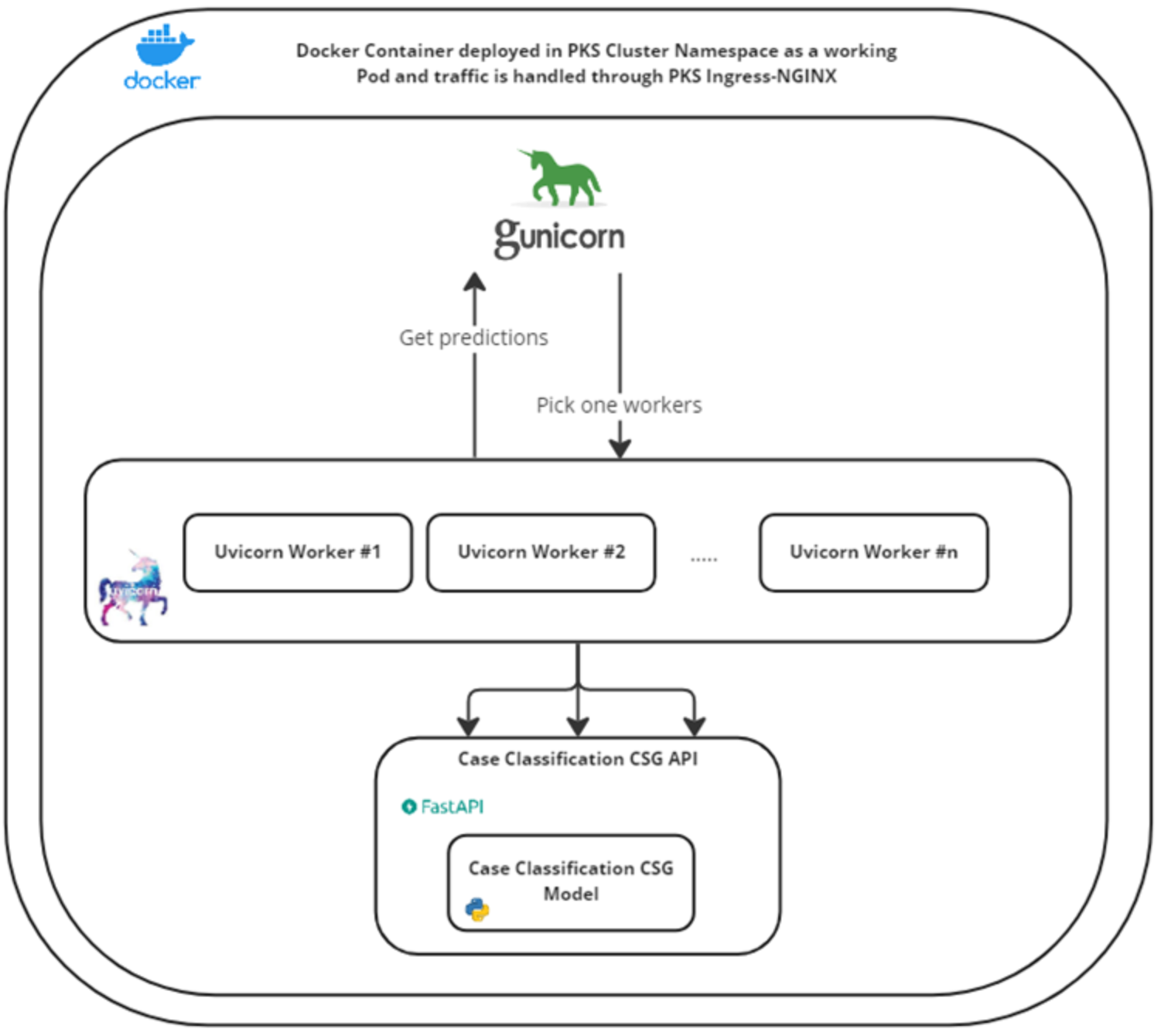
Figure 4. Model Service Architecture
The model service is called through the CRM UI by triggering the model by sending API requests that contain the textual case logs. Next, the steps a Batch Prediction Pipeline are run and classification is obtained. The classification will then be displayed through the CRM, where support agents may alter the classification to provide additional feedback for model retraining which is leveraged in combination of validation data obtained through Elixir.