
Elixir – a novel data labelling and prediction validation tool
Elixir – a novel data labelling and prediction validation tool
-
Due to the large number of labels from which to choose, it is extremely difficult, even for experts, to choose an optimum label in certain situations. Therefore, we investigated open-source data labeling/validation tools to accelerate and facilitate the validation process. This analysis revealed that most existing solutions do not satisfy the requirements, in particular, support for a large number of labels (over 500), the ability to search and insert labels, and embedding of a model. Therefore, the authors implemented our own active learning-enabled data labeling and validation tool known as Elixir, also considering future data annotation/validation requirements in mind. The following figure shows Elixir’s UI Main User Interface of Elixir
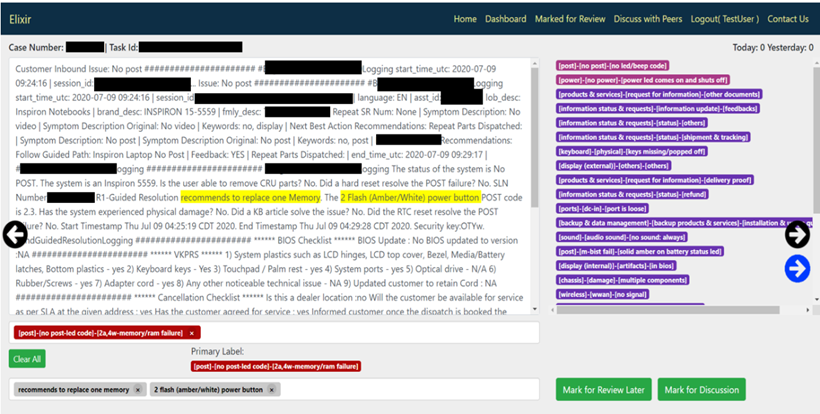 Figure 2. Main user interface of Elixir
Figure 2. Main user interface of ElixirModel prediction records require manual validations to be automatically distributed and allocated to a group of experts using Elixir. Case logs are shown in the main text area where the experts can highlight relevant keywords indicating the correct classification. Elixir uses the same SVC model and generates the top 20 predictions. These predictions are shown in the right side of the UI (purple labels in the preceding figure). The top three predictions are highlighted in red and pink. We noticed that 90% of the time, the accurate label can be found within these top 20 labels. Therefore, experts do not have to scroll through a large number of labels to find the most relevant classification. Experts can choose the best matching labels from the labels on the right side and move to the next case log. If a suitable label is not found in the right side, they can enter some keywords in the label area where a list of matching labels (out of entire list of labels) is shown. Experts can then choose the relevant label from the retrieved label. Finally, if a novel issue is noticed, experts can type the new issue classification.
model predictions are consistently validated by experts and validated records are being used for incremental training of the model. This architecture ensures model accuracy keeps improving while learning new records. The following figure shows the implementation architecture for Elixir:
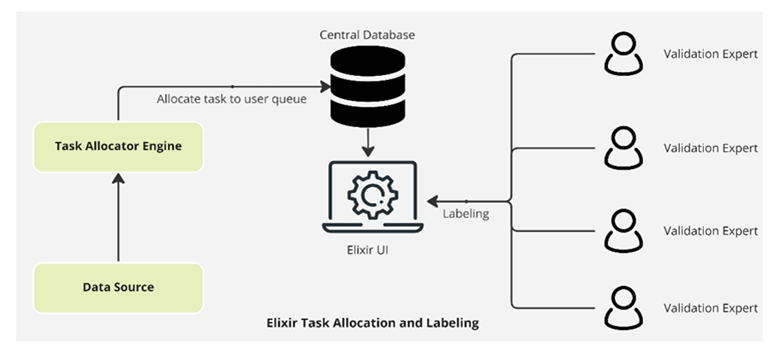
Figure 3. Implementation of Elixir for Data Labeling and Validation
The main components of Elixir include a task allocator engine, a central database, and the UI. Validation experts register on the tool by placing a registration request. As soon as the request is placed, an approval link is sent to the administrator through automated instant messaging notification. Once approved, the user is onboarded to the tool, followed by automated assignment of prediction validation tasks for the user by the task allocator engine. The engine runs at scheduled intervals, continuously keeping track of task queues for each user and allocates validation tasks from a common pool (data source) to each user queue assuring that each user has no more than 100 pending tasks in queue. Elixir also provides daily statistics to the user such as the total tasks allocated to them and number of tasks completed per day, week, and so on. These statistics help them track their validation progress. In addition, a weekly report containing a summary of all validation statistics by the entire team is generated and shared with the team leaders. Furthermore, additional useful features were implemented for validation experts: for example, the ability to mark certain difficult tasks for reviewing later. Such tasks will be moved to separate queues where subsequently users can mark them as reviewed once completed the validation. This feature was useful especially for newly registered experts to quickly complete easy validation tasks first but once they gain some experience with the tool and case logs, they can revisit more difficult tasks for validation. Another useful feature is the “mark to discuss” feature where users can mark certain tasks and access these tasks later in a separate dashboard to discuss them with peers and validate together.