
Spirit of modularity
Spirit of modularity
-
The cornerstone of this joint architecture is modularity, offering a flexible design that caters to a multitude of use cases, sectors, and computational requirements. A truly modular AI infrastructure is designed to be adaptable and future-proof, with components that can be mixed and matched based on specific project requirements. The Dell-NVIDIA solution uses this approach, enabling businesses to focus on certain aspects of generative AI workloads when building their infrastructure. This modular approach is accomplished through specific use-case designs for training, model tuning, and inference that make efficient use of each compute type. Each design starts with the minimum unit for each use case, with options to expand.
A modular software stack is also critical to allow AI researchers, data scientists, data engineers, and other users to design their infrastructure quickly and achieve rapid time to value. The Dell-NVIDIA solution uses the best of NVIDIA AI software, with partner solutions to build an AI platform that is adaptable and supported at each layer—from the operating system to the scheduler to multiple AI Operations (AIOps) and Machine Learning Operations (MLOps) solutions.
The following figure shows a high-level view of the solution architecture, with emphasis on the software stack, from the infrastructure layer up through the AI application software:
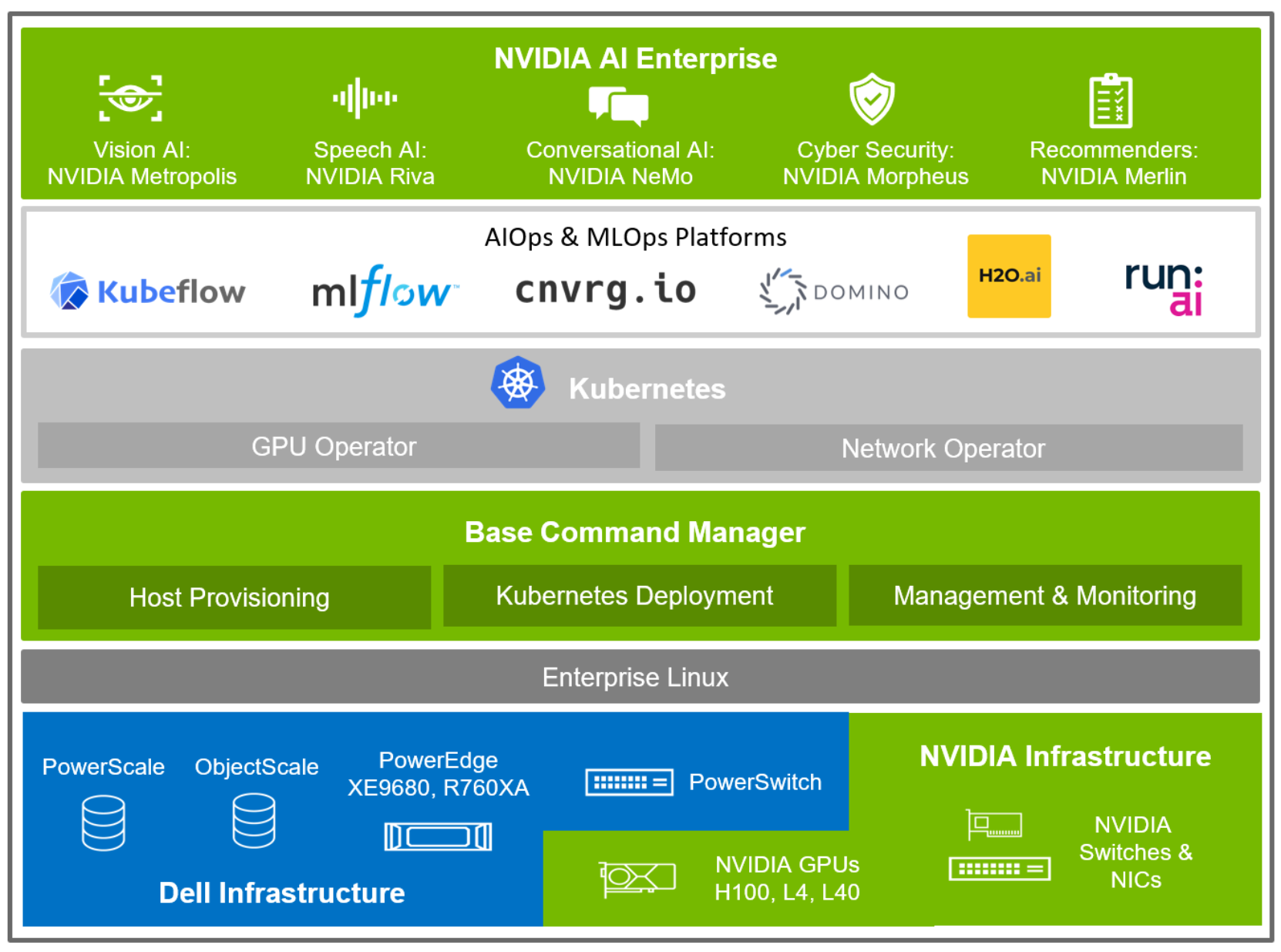
Figure 1. Solution architecture and software stack
At a high level, the solution architecture starts with the base hardware components from Dell Technologies and NVIDIA, which are combined in permutations that focus on specific AI workloads, such as training, fine-tuning, and inferencing. This white paper describes the individual hardware components in a later section.
Each control plane or compute element supports either Red Hat Enterprise Linux or Ubuntu as the operating system, which is preloaded with NVIDIA GPU drivers and Compute Unified Device Architecture (CUDA) for bare metal use.
NVIDIA Base Command Manager (BCM) serves as the cluster manager by installing software on the host systems in the cluster, deploying Kubernetes, and monitoring the cluster state. Host provisioning is core to a well-functioning cluster, with the ability to load the operating system, driver, firmware, and other critical software on each host system. Kubernetes deployment includes GPU Operator and Network Operator installation, a critical part of GPU and network fabric enablement. NVIDIA BCM supports both stateful and stateless host management, tracking each system, its health, and collecting metrics that administrators can view in real time or can be rolled up into reports.
At the top layer of the solution, is the NVIDIA AI Enterprise software that accelerates the data science pipeline and streamlines development and deployment of production AI including generative AI, computer vision, speech AI, and more. Whether developing a new AI model initially or using one of the reference AI workflows as a template to get started, NVIDIA AI Enterprise offers secure, stable, end-to-end software that is rapidly growing and fully supported by NVIDIA.
With Kubernetes deployed in the solution, there are several different MLOps solutions that can be installed, whether open-source solutions like Kubeflow and MLFlow, or featured supported solutions such as cnvrg.io, Domino, H2O.ai, Run:ai, and more. Each of these solutions can be deployed to work in a multicluster and hybrid cloud scenario.