
Test methodology
Test methodology
-
Rally
Rally is a benchmarking framework designed to measure the performance of Elasticsearch in very small and specific pieces. It also can be used to perform the following tasks:
- Set up an Elasticsearch cluster for benchmarking, and tear it down afterward
- Manage benchmark data and specifications across Elasticsearch versions
- Run benchmarks and record results
- Find performance problems by attaching telemetry devices
- Compare performance results
For more information about Rally, see Getting Started with Rally.
Modifications made to the track JSON file:
We modified the Rally configuration as follows, as part of the setup:
Applied a number to each IP conversion as suggested in the original readme file.
- Removed illegal characters from the "object_mappings.sort"
- Transformed the source data to a bulk-friendly JSON format (ignoring all entries that contained unrecognized/problematic characters and invalid IP addresses like "0". Approximately 0.001% of the source data was lost due to this modification.)
Rally-Tracks
Tracks are repositories that contain the default track specifications for the Elasticsearch benchmarking for the Rally tool. Tracks are used to describe benchmarks for Rally and to provide a consistent and repeatable test.
Rally has created a tutorial on how to create your tracks.
For this paper the NYC Yellow cab data was used for the track.
This dataset includes trip records from all trips completed in yellow taxis from in NYC from January to June in 2015. Records include fields capturing pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. The data used in the attached datasets were collected and provided to the NYC Taxi and Limousine Commission (TLC) by technology providers authorized under the Taxicab Passenger Enhancement Program (TPEP). The TLC did not create the trip data, and TLC makes no representations as to the accuracy of these data.
The dataset can be found here:
http://www.nyc.gov/html/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf[2]
HTTP Logs Track
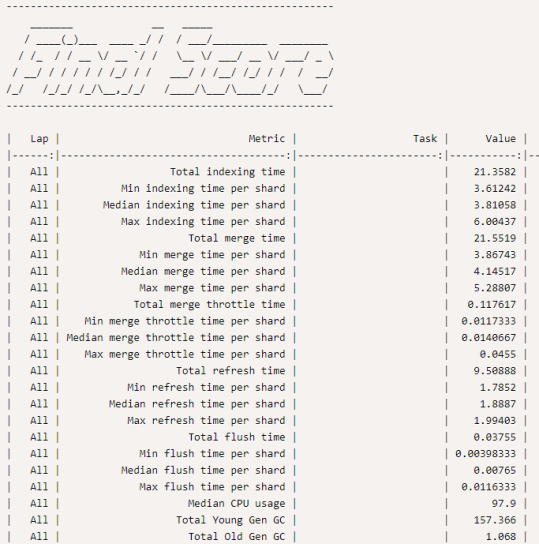
At the end of each Rally race, Rally will produce metric, task and score values, so that an administrator can tune and maintain consistency.
The final score result of the NYC yellow taxi cab Rally with the complete values are shown in Appendix A: Detailed results.
Test scenarios
We implemented the following test scenarios during our solution testing:
- We first tested a single Elastic node with the benchmarking tool to reveal baseline numbers.
- We then tested a five-node Elastic node cluster with the benchmarking tool to reveal performance results.