
OpenShift Data Foundation
OpenShift Data Foundation
-
Introduction
OpenShift Data Foundation delivers a persistent data foundation that is integrated with, and optimized for, OpenShift Container Platform. OpenShift Data Foundation provides file, block, and object storage classes that enable workloads for data at rest (such as databases and warehouses), data in motion, automated data pipelines, and data in action.
OpenShift Data Foundation also provides services for continuous deployment models, analytics, and artificial intelligence and machine learning (AI/ML). Deployed, consumed, and managed through the OpenShift administrator console, the OpenShift Data Foundation platform is built on Red Hat Ceph storage, offering tightly integrated, persistent data services for OpenShift and hybrid and multicloud environments.
Why OpenShift Data Foundation?
Cloud providers and system providers can offer storage for diverse workloads. Often, these storage layers are delivered using different storage interface technologies, depending on the storage protocol that is addressed by an application. These storage solutions lack a service-level interface that provides a consistent experience for users regardless of the underlying storage infrastructure. OpenShift Data Foundation provides the following data services for applications in Kubernetes that support multiple workload types across multiple cloud platforms:
- Accelerated application development: Developer productivity depends on agile continuous integration and continuous delivery (CI/CD) pipelines and responsive infrastructure. With comprehensive support for Kubernetes, OpenShift Data Foundation automates storage provisioning alongside the provisioning of application resources, all of which are available from the OpenShift administrator console.
- Deterministic database performance: As databases have moved to container-based environments, the amount of stored data has grown, creating an urgent need for high-performing container-based storage. OpenShift Data Foundation provides persistent block storage for databases and supports database availability needs while providing consistency across multiple cloud platforms.
- Simplified storage for data analytics: Methods for analyzing data are evolving, with implications for both static data analysis and dynamic AI/ML environments. OpenShift Data Foundation lets data scientists and those who support them deploy and manage cloud-portable storage on demand, without requiring details about how data is stored or how to move datasets to other platforms.
- Data resilience for Kubernetes: OpenShift Data Foundation delivers container-aware backup capabilities using open standards for both persistent volume-level backup for applications and cluster protection at the namespace level. Because data protection services work with existing solutions, organizations can easily extend their backup software to container-based environments without having to invest in new methodologies and knowledge.
OpenShift Data Foundation architecture
Earlier releases of OpenShift Data Foundation were focused on a fully containerized Ceph cluster that is run with an OpenShift Container Platform cluster, optimized as necessary to provide block, file, or object storage with standard 3x replication. While this approach made it easy to deploy a fully integrated Ceph cluster within an OpenShift environment, it presented the following limitations:
- External Ceph clusters could not be accessed, potentially leading to a requirement for redundant storage.
- A single OpenShift Data Foundation cluster was deployed per OpenShift Container Platform instance, so the storage layer could not be mutualized across multiple clusters.
- Internal mode storage had to respect limits of total capacity and number of drives, keeping organizations from exploiting Ceph’s petabyte-scale capacity.
OpenShift Data Foundation overcomes these issues in external mode by allowing OpenShift Container Platform to access a separate and independent Ceph storage cluster, as shown in the following figure.
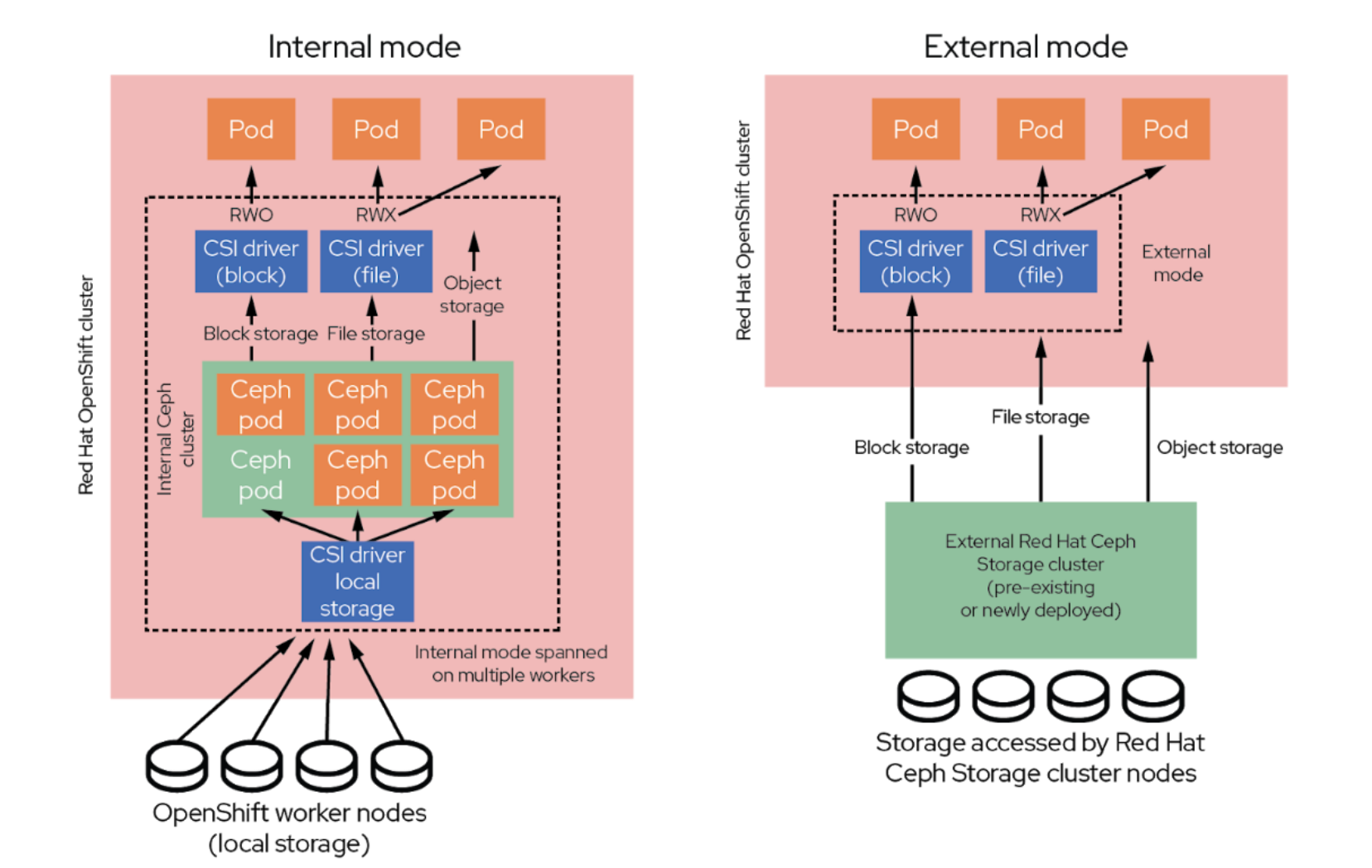
Figure 9. OpenShift Data Foundation accessing an external Ceph storage cluster
Alongside traditional internal-mode storage, this option gives solution architects multiple deployment options to address their specific workload needs. These options preserve a common, consistent storage services interface to applications and workloads while providing distinct benefits, as follows:
- Internal mode schedules applications and OpenShift Data Foundation pods on the same OpenShift cluster, offering simplified management, deployment, speed, and agility. OpenShift Data Foundation pods can either be converged onto the same node or disaggregated on different nodes, enabling organizations to balance OpenShift compute and storage resources as they like.
- External mode decouples storage from OpenShift clusters, allowing multiple OpenShift clusters to consume storage from a single, external Ceph storage cluster that can be scaled and optimized as needed.
OpenShift Data Foundation recommended hardware
The PowerEdge R7525 server is optimized for storage and provides an ideal combination of performance and flexibility for software-defined storage applications. The server can accommodate various storage device configurations including 2.5-inch or 3.5-inch hard disk drives (HDDs), solid state drives (SSDs), and nonvolatile memory express (NVMe) devices. See OpenShift Data Foundation data node PowerEdge R7525 BOM.