
Design Guide—Data Analytics with SQL Server 2022 on Red Hat OpenShift and Dell ObjectScale
Apache Spark deployment
Apache Spark deployment
-
Overview
To convert data files to the Delta Lake format, we must create an Apache Spark image with Delta Lake drivers.
- The deployment of a Spark pod in OpenShift is facilitated through the utilization of a yaml manifest file. In this scenario, a custom Spark image is used, which is stored within a private image registry.
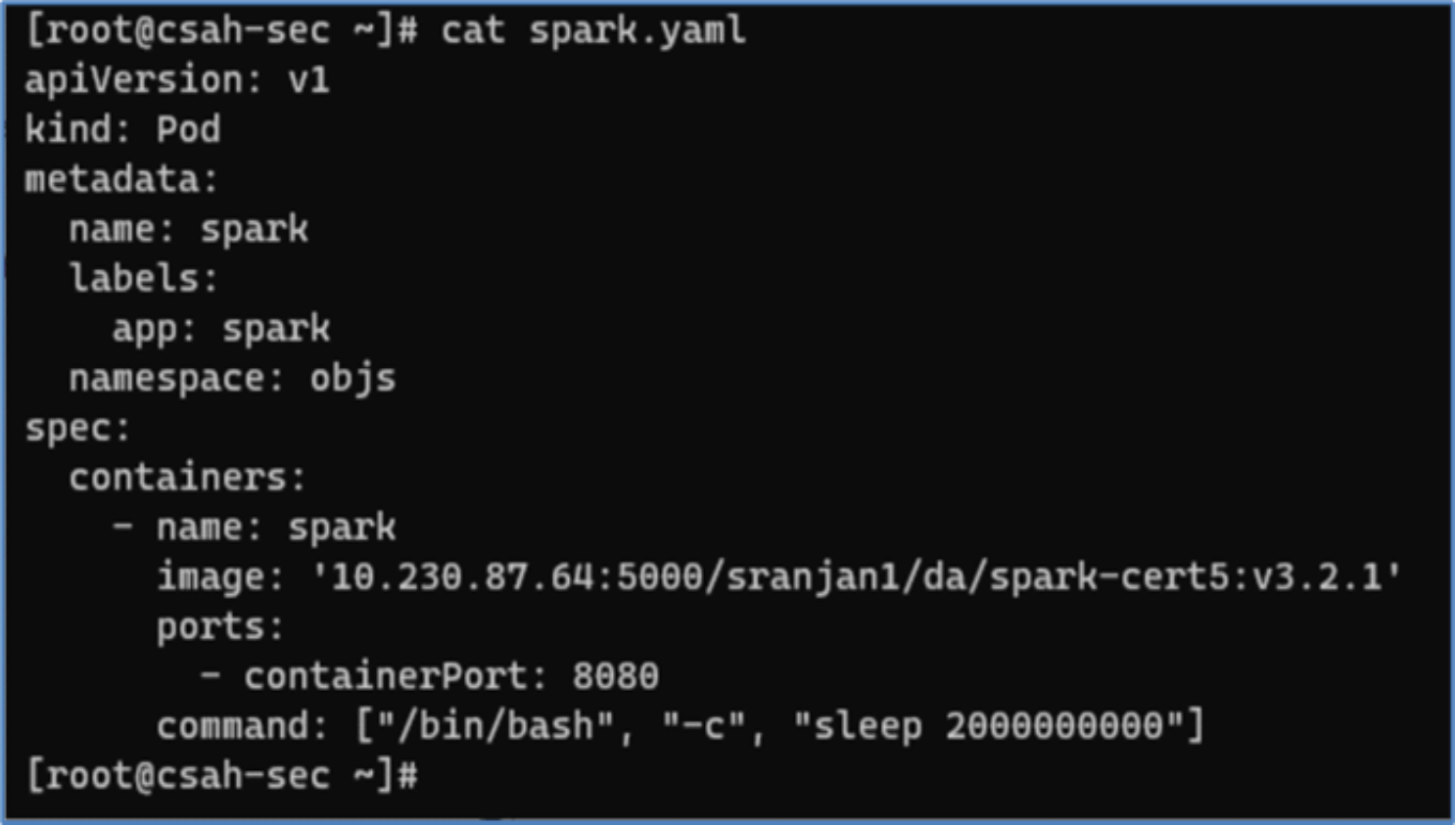
Figure 19. Spark pod yaml manifest
- After the pod has been deployed, it can be verified by using the following oc command.
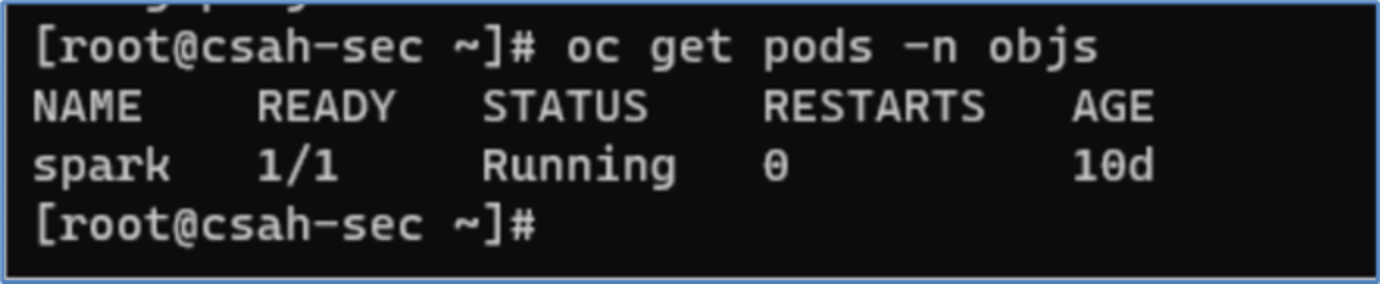 Figure 20. Spark pod status
Figure 20. Spark pod status
We can now establish a connection to the Spark pod and commence a PySpark shell by running the pyspark command. In this process, we provide the relevant ObjectScale S3 API endpoints, as well as the access and secret keys.
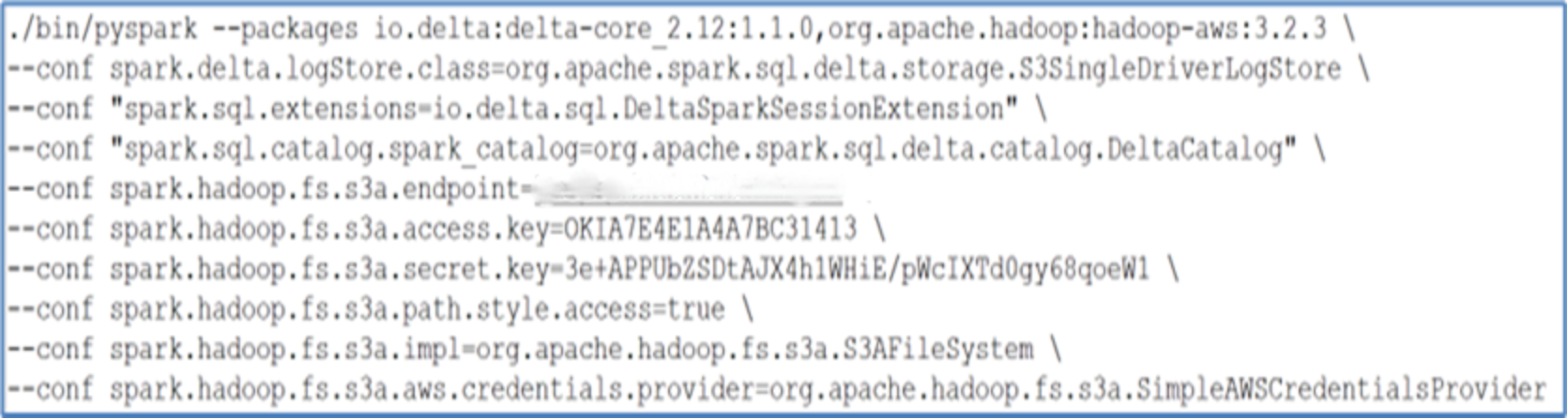 Figure 21. Spark running pyspark commands
Figure 21. Spark running pyspark commandsWhen the command is successfully run, the Spark login screen will appear, as depicted in the following image.
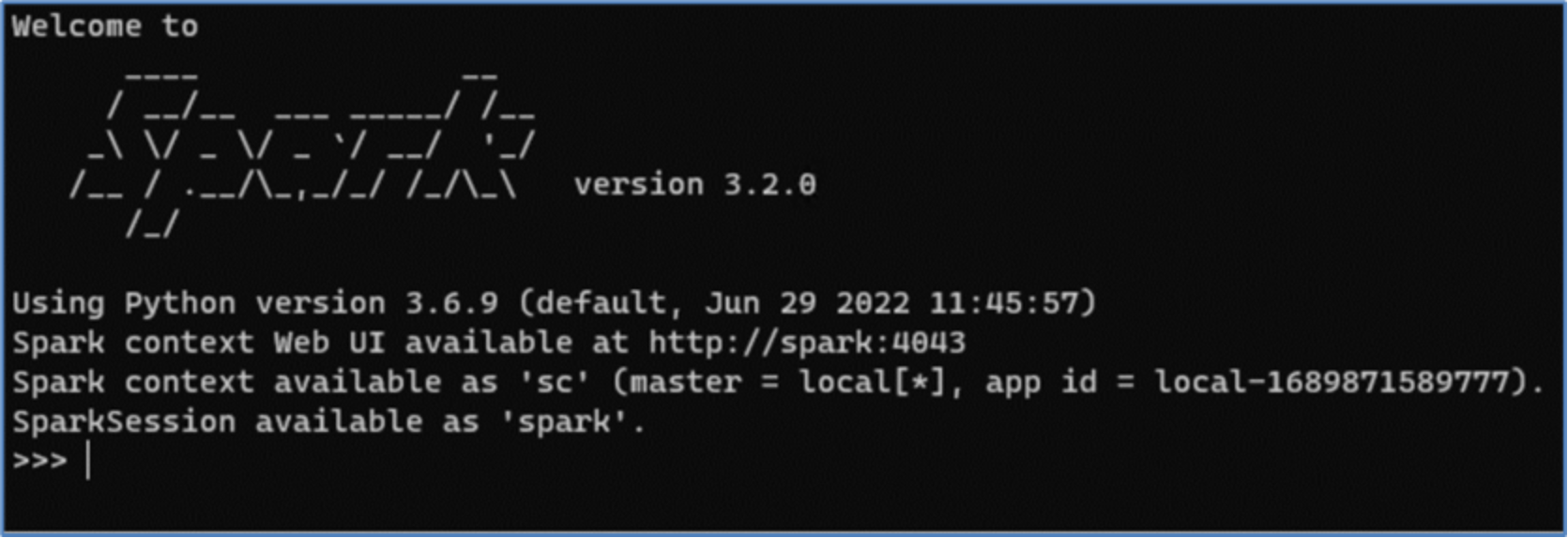 Figure 22. Spark shell
Figure 22. Spark shell