
Dell EMC SRDF/Metro simplifies Microsoft failover cluster deployment
Dell EMC SRDF/Metro simplifies Microsoft failover cluster deployment
-
SRDF/Metro is based on synchronous storage replication. It does not compete with the database for I/Os or CPU resources. It can leverage optional “cross-links” in the deployment. Cross-links allow each cluster node to have visibility to both storage systems. If a node loses connectivity to its nearest storage system, it can continue processing transactions using the remote storage system.
With SRDF/Metro, both source (R1) and target (R2) devices have full read/write data access while synchronized. To accomplish this, the storage replicates—meaning that it writes in both directions and services reads from the storage closest to the requesting node.
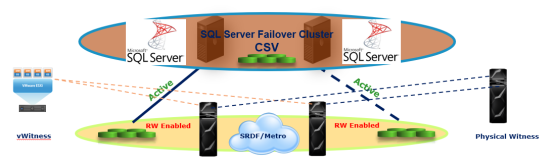
Figure 1. Dell EMC SRDF/Metro with extended distance Microsoft Failover cluster
SRDF/Metro achieves this true active/active storage replication in the following way. Each PowerMax storage device has two SCSI personalities — internal (their initial WWN and geometry), and external (which usually matches the internal, but can be ‘spoofed’ to match another device). When SRDF/Metro paired devices are synchronized, the R2 devices’ external SCSI personality is set to match the R1 devices’ SCSI personality. As a result, to the Windows failover cluster, each synchronized R1 and R2 device appears as multiple paths to a single local storage device. Shared storage devices or distributed and stretched CSVs that can be actively read/written by any cluster node can be presented to the Windows failover cluster.
All local and remote paths to the shared storage can be managed by multipathing software (such as Windows MPIO or Dell EMC PowerPath). If the optional cross-links are used, Dell EMC PowerPath software can set them to ‘auto-standby’ so they are used only if all the main paths to the nearest storage system have failed. The server I/Os will not be doubled and I/O latencies will remain minimal as I/Os are directed to the nearest storage system while it is available.
The overall management of the solution is simplified because you only need to monitor the replication health across the two storage systems. Also, by making the R1 and R2 devices seem identical to the Windows failover cluster, the cluster software is not aware that the storage is extended or stretched. As a result, no additional configuration is necessary on the Windows failover cluster to support stretched clusters using SRDF/Metro.
SCSI-3 persistent reservation (SCSI-3 PER) is another important concept for the clustered environment. SCSI-3 PER is used for I/O fencing and to resolve issues using SCSI reservations when multiple nodes try to access the SCSI device. PowerMax and several previous families of Dell EMC storage systems have supported SCSI-3 PER; therefore, most operating systems and clusters running on both physical and virtual machines are supported by PowerMax. Although VMware Metro cluster has supported Microsoft failover cluster using Raw Device Mapping (RDM) for several releases, with vSphere 6.5 and higher, SCSI-3 PER is supported by VMware metro clusters on Microsoft failover cluster using CSVs as well. Currently, SRDF/Metro can also be used on VMware metro cluster environments supporting Microsoft failover cluster using CSVs.
Another challenge of any cluster is to prevent “split-brain” and to determine the surviving site in the case of a failure. When two or more nodes in a cluster can not communicate with their peers, and yet continue to write to the storage, they can cause data corruption. This situation is called a “split-brain”. SRDF/Metro takes a deterministic approach to protect against a “split-brain” and determines the surviving site based on two complimentary methods: Bias rules, and Witness rules. These methods are discussed in more detail in the section SRDF/Metro protection from a “split-brain” situation.