As the manufacturing operations mature and support a broad range of services, workflows, and user base, it becomes necessary to up-scale the environments. Similarly, old applications may retire, plants and operations may get consolidated, and the systems used for production may move into a lower tier to support QA and reporting, all of which may require downscaling of those environments. This section covers the considerations for infrastructure updates and data or system migration aspects. Specific tasks may vary based on the environments, but it helps to follow the general guidance provided in this section.

Dell Validated Design for Manufacturing Edge with PTC - Design Guide
Scaling up environments to manage growth
Scaling up environments to manage growth
-
Scale and sizing guidance to meet demand of workflows
The system size and resources required for a given ThingWorx with DPM deployment varies based on the expected load, required performance, and configuration options selected.
The following are parameters to consider when making sizing decisions:
- The number of connected sensors and equipment (referred to as devices or Things)
- The number of tags collected, the data types of the tags, and frequency of data collection
- The number of factories or facilities
Deploying the ThingWorx with DPM solution on VMware comes with the significant benefit that—if your load or performance requirements should change in the future—CPU, storage, and memory configuration changes can be made easily in the VM’s settings. Some of these changes can even be made on the fly, with no production downtime.
WPS and RPS calculations
When planning the size of your system and determining how to scale, the data processing and exchange must be quantified. PTC provides two metrics to establish this. One metric considers data acquisition and storage (writes per second, or WPS), and the other considers data retrieval and visualization (requests per second, or RPS).
When determining ThingWorx system requirements, it is important to consider how much data the platform will be expected to receive from edge devices.
The WPS calculation is mapped to IOPS and Bandwidth/Throughput numbers. The calculation for WPS is as follows:
WPS = T × [(P1 × F1) + (P2 × F2) + …..],
where T is the number of Things, Px is the number of properties, with Fx as the update frequency (per seconds).
System requirements for visualization focus on server load generated from user experiences (Mashups) within the business application. Consider expected RPS using PTC’s calculations for Mashups as follows:
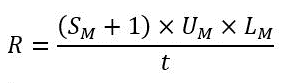
where t is the time period of peak user access,
M is the number of unique Mashups,
SM is the number of services per Mashup,
UM is the number of concurrent users, and
LM is the number of times the user loads each Mashup.
Use the WPS and RPS calculations from above to select a baseline. For each combination listed, the WPS and RPS values were obtained during the same sizing test run.
Figure 19. Sizing table 
Collect VxRail and application performance data and tune the environment
The VxRail system monitoring dashboard provides detailed insights into compute, network, and storage consumption at the VM level. PowerCLI, which is tightly integrated with Windows PowerShell, can be used to collect such monitoring data at various granularity and frequency. CSV files can be generated from the PowerCLI-collected dataset, and it can be used for further analytics and charting for identifying bottlenecks and tuning the environment. Application and VM-level performance data can also be collected, using tools like Perfmon, IOstat, and others, to compare VxRail-reported data with application-level performance for further application-level guidance and tuning.
Create on-VM and external-VM model and persistence database providers
Once the user has determined the ideal operating system, ThingWorx model-provider, and persistence provider best suited for their application, the setup may benefit from further configuration to enhance performance. Consider hosting the ThingWorx application and the persistence provider(s) on separate VMs. This allows for appropriate resources to be assigned based on the expected workloads of each, without degrading the performance of each other.
There is some additional flexibility in OS and database configurations that can be achieved. For example, a Windows-based deployment of ThingWorx can utilize Linux-only InfluxDB as a persistence provider, which would be impossible on the same machine. This allows for better-customized policies on high availability, updates, upgrades, and backups of the separated machines.
Telemetry data and accompanying database administration responsibilities can be brought together in one location or combined with other data, separate from the application administration and configuration.
For more details on persistence providers, see Data Storage Options.
Configure ThingWorx to use external Persistence Provider
This section describes how to configure a new persistence provider located on a remote machine. Here, three persistence providers are addressed: SQL Server, PostgreSQL, and InfluxDB. Once configured, the next step is to configure your value stream or other data source to use the persistence provider. - In the Browse menu, click Persistence Provider. Click the New button at the top of the page.
Figure 20. Create new Persistence Provider 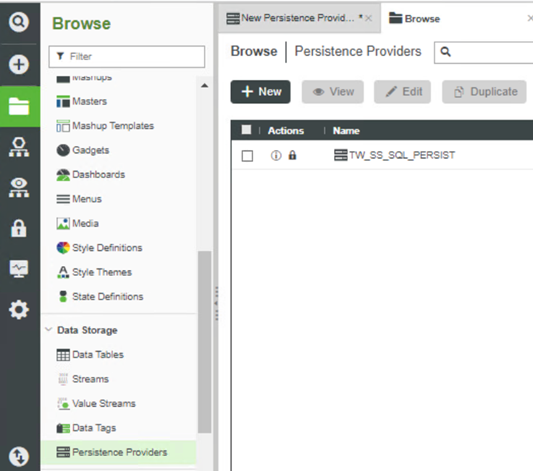
- On the New Persistence Provider page, enter the following details:
- Name – give the provider a name.
- Project – select the appropriate project from the list.
- Persistence Provider Package – dependent on database type, as detailed in the following table.
Figure 21. New Persistence Provider page 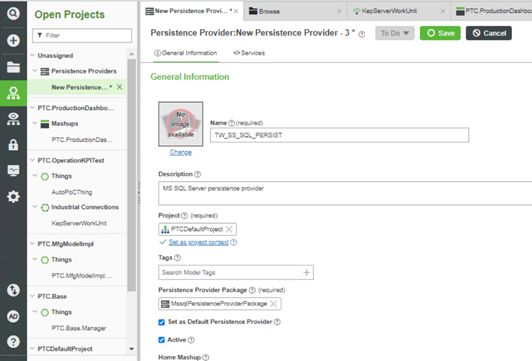
Table 5. Persistent Provider database types Database type Persistence Provider Package SQL Server MssqlPersistenceProviderPackage PostgreSQL PostgresPersistenceProviderPackage InfluxDB InfluxPersistenceProviderPackage - On the Configuration tab, enter the following information:
- URL (Connection/JDBC) and other options – dependent on database type. See the following table.
- Username and Password – user credentials for ThingWorx access to the database.
Figure 22. Persistence Provider Configuration 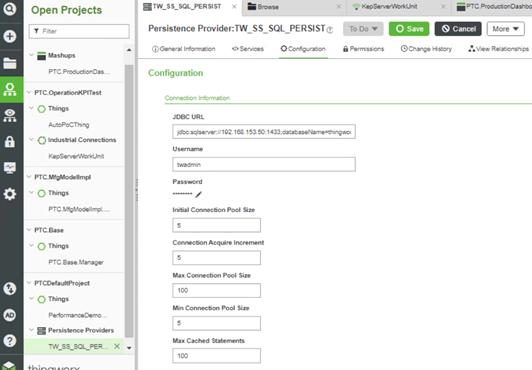
Table 6. Configuration details Database type URL string Database schema Driver class SQL Server jdbc:sqlserver://<IPaddress>:<port>;databaseName=thingworx — — PostgreSQL jdbc:postgresql://<IPaddress>:<port>/thingworx — org.postgresql.Driver InfluxDB http://<IPaddress>:<port> thingworx
Your persistence provider is now ready to store data. Infrastructure requirements for scaling
Evaluation of the performance of the system and future operational needs may require pro-actively updating the environments to meet the changing demands. These are the key points for consideration for infrastructure changes. The points below are based on the service level priorities of the target environments, and not all of the points have the same impact for all the environments.
- Consider the service level changes needed with the new scale and plan the environment as per the guidance from earlier section.
- Based on the expected data growth rate, plan for some extra capacity.
- Consider the data services requirements. Some of the factors include writes per second and reads per second rates, number of connected users, size, and type of the data set to estimate the throughput requirements, desired latency based on the service levels of the environment, and data retention period.
- Add a sufficient number of data and log devices and increase their count for scaling up for performance as well as concurrency.
- Use separate VMware paravirtualized SCSI controller for each device to minimize contention for IO operations.
- Databases coalesce writes and many sequential reads and log writes are generally 256 KB or larger. When formatting the devices for the file system use, apply proper allocation unit sizes for higher performance. Allocation unit size of 1 MB and higher are available on Linux and Windows Server 2019 and higher versions. An allocation unit of 1 MB minimizes the storage requests, offers better alignment with underlying disk technology, and offers higher performance.
- Analytics tools require heavy reads and may span various database tables making them very memory and I/O intensive. Such operations also feed the results to other tiered services to augment the decisions or provide additional capabilities. Consider the type of analytics operations to run on the data and the locality of that on edge, core, and cloud with the data exchange and security requirements.
- Identify the data protection needs, high availability, and mechanisms to recover the environments in the event of failures and corruption.
Migration requirements for scaling
- Use a pre-tested clone from the source environment to seed the new target environment. Once that is complete, all industrial connection and network configurations can be updated to confirm the data flow onto the target environment. These are the steps to adhere to new scale requirements:
- Configure the appropriate directory structure and files as per the desired scale. New data files and log files can be added as necessary to support data growth requirements at the application, databases, and support file levels.
- Introduce these new files to application ecosystem using application mechanisms.
- Make sure that you have fully tested the backup or clone available from the source environment, which can be used to revert the changes, if necessary.