
Introduction
Introduction
-

Figure 1. Real-world examples of spelling and grammar issues
Spelling and grammar mistakes are problematic for NLP tasks. Some mistakes also have a negative impact beyond the world of computing, and spelling issues may even end up costing business millions of dollars in lost revenue. The following figure shows real-world examples of spelling and grammar issues.
An analysis of a random sample of 1,000 textual symptom entries by the customer support agents revealed that a staggering 15% of all entries have one or more spelling mistakes in them, which means about two out of every 10 entries have one or more spelling errors.
Noisy and erroneous text make the automated processing of textual data difficult. Noisy text is text with any difference in the surface form from the intended text, including abbreviations, acronyms, and more. It has been proven to reduce the performance of various automated text processing applications and algorithms including the following:
- Semantic and syntactic parsing
- Information retrieval
- Machine translation
- Text classification
Research indicates that addressing these issues by pre-processing text help improve the accuracy of many NLP applications.
Text pre-processing is usually a prerequisite for NLP tasks such as speech processing, information retrieval, and text classification, as shown in the following figure.
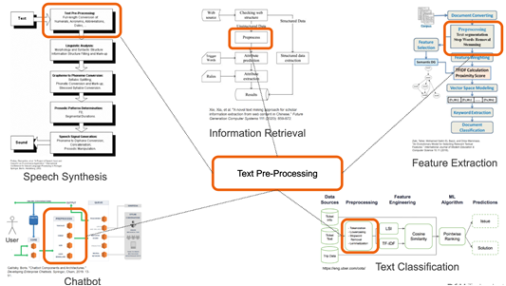
Figure 2. Text pre-processing: A common step in NLP applications
Automated processing of textual data is increasingly important within Dell Technologies. Tools employ various ML and Deep Learning (DL) techniques to extract useful information that inform and streamline business operations. NLP applications implement their own bespoke text cleaning and pre-processing techniques in various levels of maturity.
Still, most of these applications employ primitive key-value based mapping techniques for spelling corrections, which can only deal with a limited number of vocabulary items contained in a database. Moreover, different teams working on similar applications can duplicate the same text-preprocessing functionality, as shown in left-hand side of the Figure 3 in the Methodology section.
This issue of different teams having to develop same text-processing solutions over and over again highlights the need for a central, robust, high-performance automated query correction and text pre-processing API for processing textual data logged within Dell Technologies.