
Scale-out instances
Scale-out instances
-
Another common method of accommodating business growth in data architectures is to deploy a scale-out architecture where the number of instances can be increased over time for additional power and capacity. These architectures are becoming increasingly popular as cloud-enabled architectures, such as this one, allow workloads to be “spun up” and “spun down” easily. To demonstrate this, a fixed workload was deployed using the same HammerDB TPROC-C test to start or “spin-up” the same user workload (15 users) every 10 minutes on a new Arc-enabled SQL MI GP Instance, up to 12 instances. Each workload executed for 150 minutes and completed or “spun-down”.
Again, the following Grafana chart demonstrates the scalability of the environment. Each layer in the chart represents the compute resources consumed by each Arc-enabled SQL MI GP instance. The instances are balanced, consuming roughly the same amount of compute resources, and starting and stopping in a non-disruptive fashion.
We also monitored with the Azure portal using the Azure Monitor for Containers extension. This extension was deployed into an Azure Arc namespace within our Kubernetes cluster.
CPU usage while increasing Azure Arc-enabled SQL Managed Instances
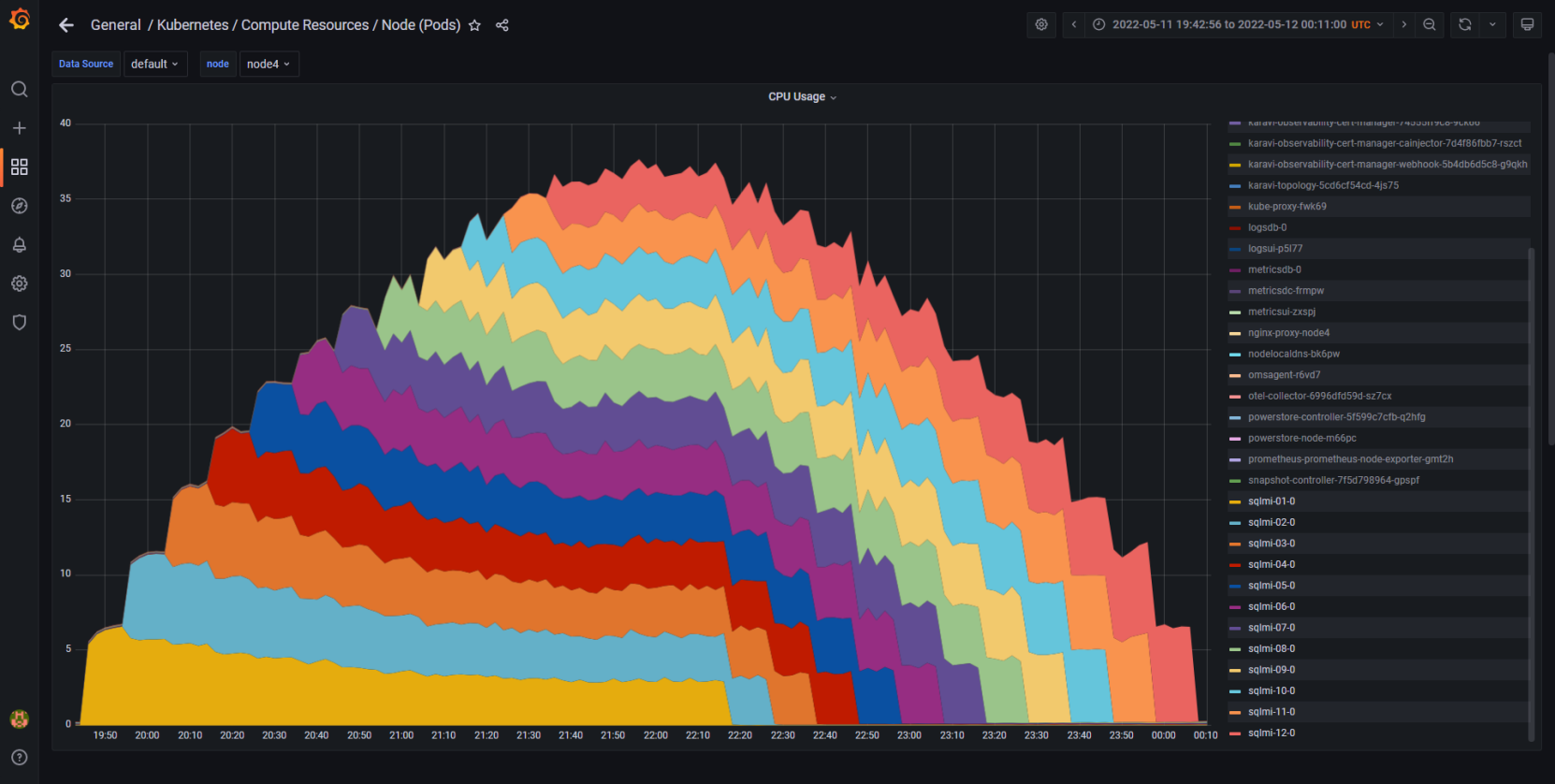
Figure 9. Equal CPU resources consumed by each of the 12 Azure Arc-enabled SQL MIs
Node CPU Utilization – Azure Arc for Kubernetes | Insights
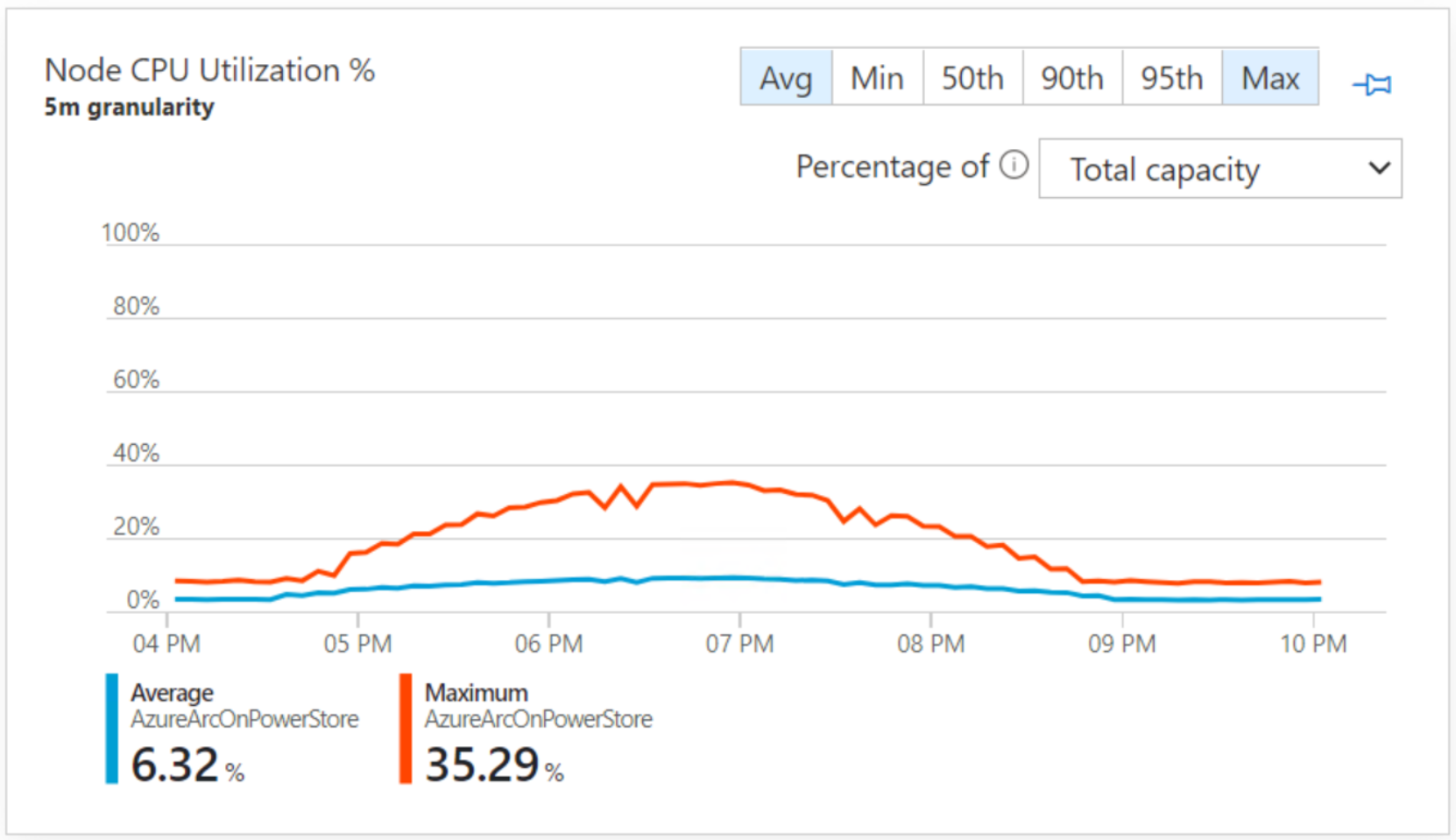
There are robust options for full observability into the environment. In Figure 9 we have Grafana from the data controller; in Figure 10 we have Azure Monitor from the Azure portal. Both observe the same workload at the same time, node CPU, through two different perspectives.Figure 10. Azure Monitor
The following graph for the staggered start metrics displays a ramp-up and ramp-down performance test. This demonstrates predictive performance and scale which would be required to support stringent SLAs, when the workload was at its most dense, in the middle of the graph.
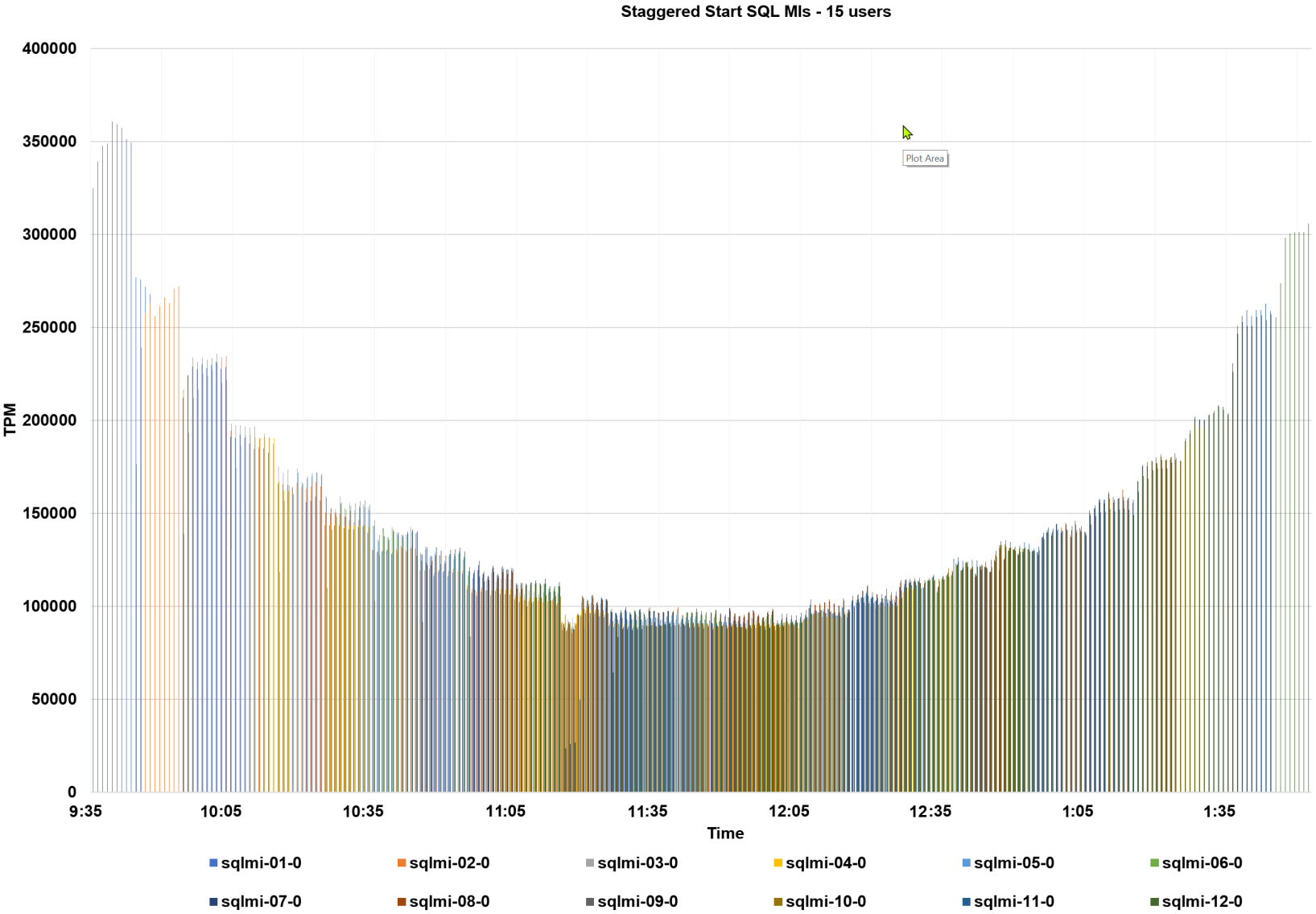
Figure 11. Staggered start Arc-enabled SQL MIs
Throughout all of our tests there was ample performance headroom on the PowerStore and PowerEdge hardware.