We ran the VMFleet tests under the following conditions:
- Healthy cluster running 64 VMs per node
- Healthy cluster running 32 VMs per node
- Degraded cluster with one node failed
- Degraded cluster with two nodes failed
Healthy cluster running 64 VMs per node
The following table presents the range of VMFleet and DISKSPD parameters that were used during our testing of the cluster in optimal health and running 64 VMFleet VMs per node.
| VMFleet and DISKSPD parameters | Values |
| Number of VMs running per node | 64 |
| vCPUs per VM | 2 |
| Memory per VM | 4 GB |
| VHDX size per VM | 40 GB |
| VM operating system | Windows Server 2019 |
| Data file size used in DISKSPD | 10 GB |
| Cluster Shared Volume (CSV) in-memory read cache size | 0 |
| Block sizes | 4-512 KB |
| Thread counts | 1-2 |
| Outstanding I/Os | 2-32 |
| Write percentages | 0-100 |
| I/O patterns | Random, Sequential |
We first selected DISKSPD I/O profiles that are aimed at identifying the maximum IOPS and throughput thresholds of the cluster. By pushing the limits of the storage subsystem, we confirmed that the networking, compute, operating systems, and virtualization layer were configured correctly according to our Deployment Guide and Network Integration and Host Network Configuration Options guide. This also ensured that no misconfiguration occurred during initial deployment that could skew the results of I/O profiles that are more representative of real-world workloads. Our results are depicted in the following table.
| I/O profile | Parameter values explained | Performance metrics |
| B4-T2-O32-W0-PR | Block size: 4k Thread count: 2 Write percentage: 0% | IOPS: 5,727,985 Read latency: 1.3 milliseconds |
| B4-T2-O16-W100-PR | Block size: 4k Thread count: 2 | IOPS: 700,256 Write latency: 9 milliseconds |
| B512-T1-O8-W0-PSI | Block size: 512k Thread count: 1 | Throughput: 105 GB/s |
| B512-T1-O1-W100-PSI | Block size: 512k Thread count: 1 | Throughput: 8 GB/s |
Healthy cluster running 32 VMs per node
To prepare for the other three test scenarios, we redeployed VMFleet with 32 VMs running per node. We then stressed the storage subsystem using I/O profiles more reflective of the types of demanding workloads that are found in the modern enterprise. These applications had smaller block sizes, random I/O patterns, and various read/write ratios.
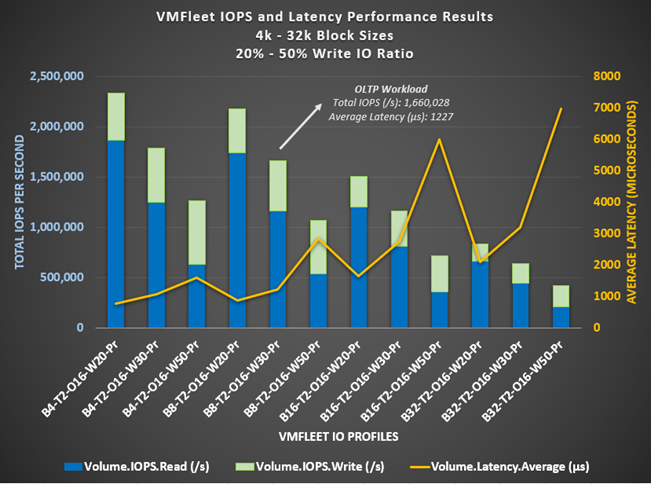
The 8 KB block size and 30 percent random write I/O profile is typical of an Online Transactional Processing (OLTP) workload. We observed VMFleet driving over 1.6 million IOPS at slightly over 1-millisecond average latency with this I/O profile, indicating that the cluster has the potential to accelerate OLTP workloads and improve end-user response time to database applications. Even increasing the block size to 32 KB and increasing the write I/O to 50 percent produces over 400,000 IOPS at under 7-millisecond latency.
The following figure depicts the results of this workload testing.
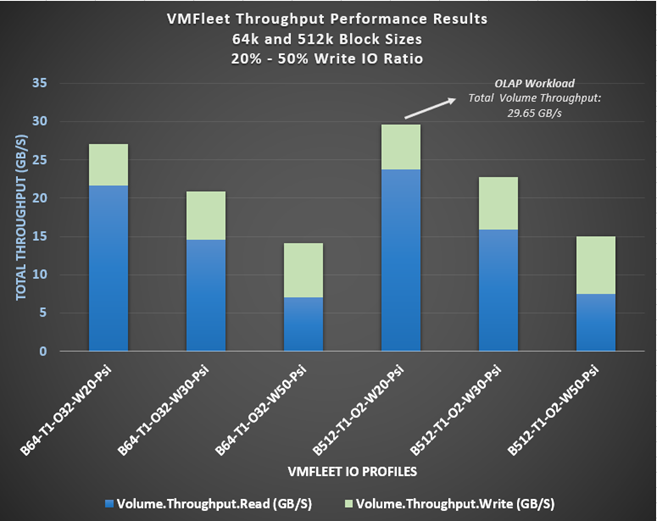
Online Analytical Processing (OLAP) workloads focus on retrieval and analysis of large datasets. We selected larger block sizes and sequential I/O patterns to test workloads in this category. Throughput became the key performance indicator to analyze. The results that are shown in the following figure indicate an impressive sustained throughput that can greatly benefit this category of OLAP workloads. Other types of IT services that could benefit include file and application backups and streaming video.
Testing results on a degraded cluster
We simulated two different failure scenarios on the healthy cluster running 32 VMs per node. In the first scenario, which is depicted in the following figure, we shut down one node, which had the following impact:
- The cluster moved the CSV owned by Node 4 to Node 2. Node 2 became the new owner of that CSV.
- We live-migrated the failed VMs to Node 2 to ensure they were running on the same host that owned the CSV containing their virtual disks.
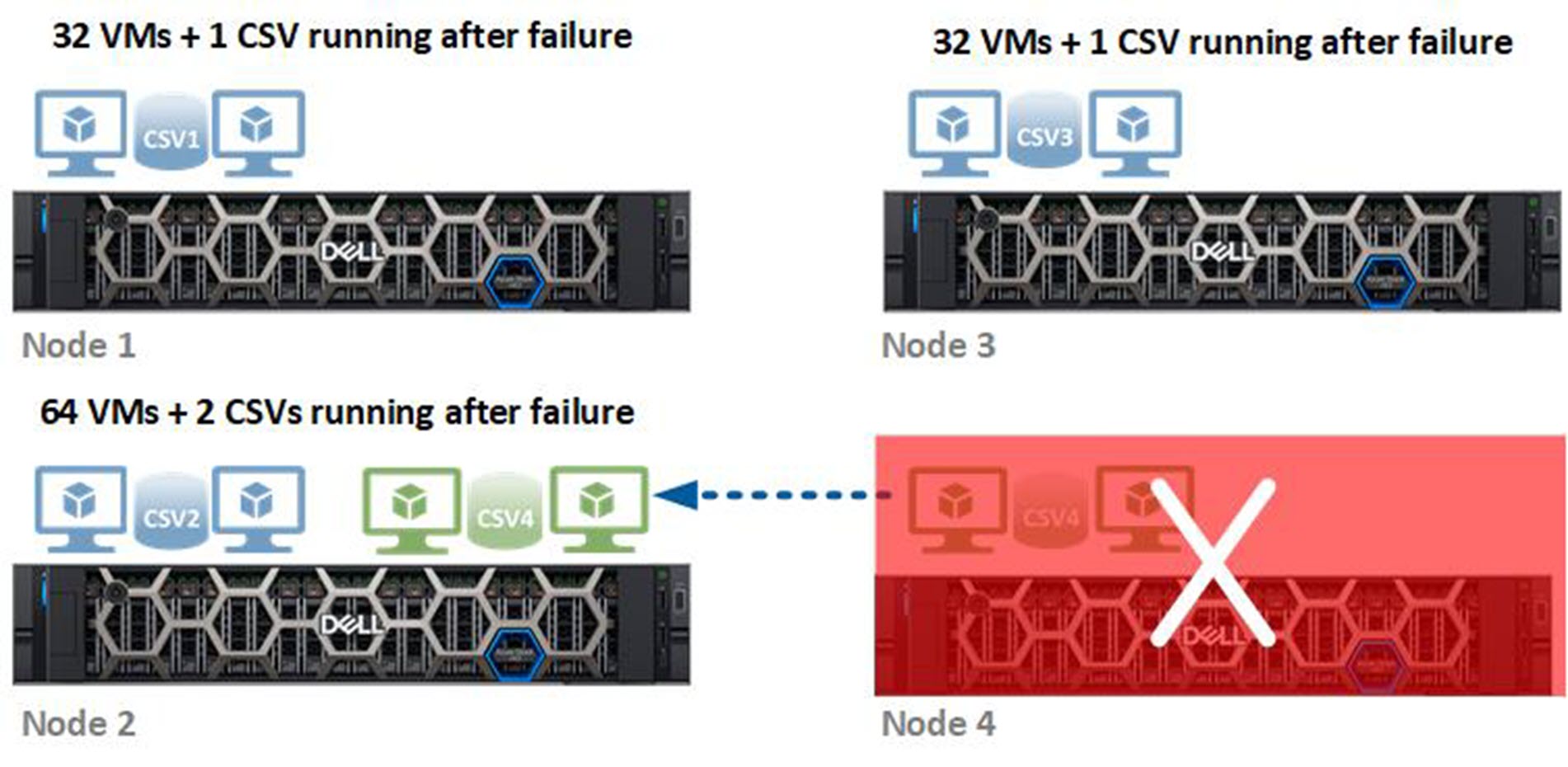
In the second scenario, which is depicted in the following figure, we shut down two nodes, which had the following impact:
- The cluster moved the CSVs owned by Nodes 3 and 4 to Nodes 1 and 2, respectively. Nodes 1 and 2 became the new owners of these volumes.
- We live-migrated the failed VMs to Nodes 1 and 2, ensuring that all VMs were running on the host that owned the CSV containing their virtual disks.

According to the VMFleet test results, we continued to see outstanding performance even with the cluster in a degraded state. This allows system administrators extra time to recover from node failures without negatively impacting the end-user response times of their most critical applications. The following table compares the testing scenarios using the I/O profiles that are aimed at identifying the maximum thresholds.
| I/O profiles | Healthy cluster | One-node failure | Two-node failure |
| B4-T2-O32-W0-PR | IOPS: 4,856,796 Read latency: 378 microseconds | IOPS: 4,390,717 Read latency: 380 microseconds | IOPS: 3,842,997 Read latency: 262 microseconds |
| B4-T2-O16-W100-PR | IOPS: 753,886 Write latency: 3.2 milliseconds | IOPS: 482,715 Write latency: 5.7 milliseconds | IOPS: 330,176 Write latency: 11.4 milliseconds |
| B512-T1-O8-W0-PSI | Throughput: 91 GB/s | Throughput: 113 GB/s | Throughput: 77 GB/s |
| B512-T1-O1-W100-PSI | Throughput: 8 GB/s | Throughput: 6 GB/s | Throughput: 10 GB/s |
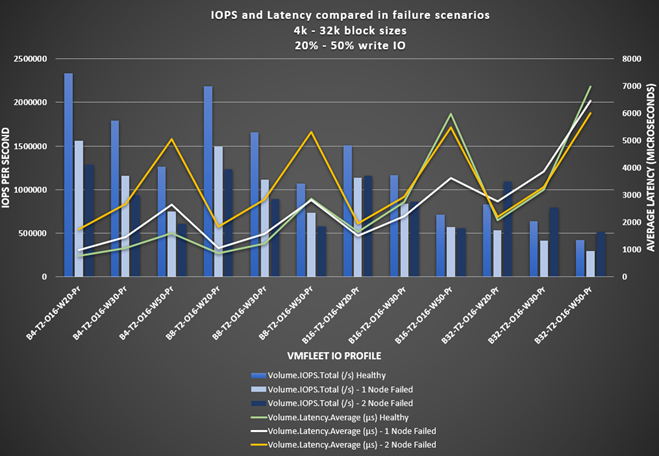
The following figure shows the IOPS and latency results from the VMFleet tests. These tests used I/O profiles that are more representative of real-world applications with smaller block sizes, random I/O patterns, and various read/write ratios. Notice that IOPS decrease and latency increases for the 4k and 8k block sizes, as one would expect. With the 32k block size, we observed the following behavior:
- Latency is less variable across the failure scenarios. We found an 8 percent decrease in latency after the single-node failure and a 14 percent decrease in latency after the two-node failure. This was primarily because write I/O did not need to be committed across as many nodes in the cluster. After the single-node failure, we observed that the network traffic between nodes decreased by more than 3 Gbps per node.
- IOPS increased by 20 to 30 percent after the two-node failure, depending on the percentage of writes in the I/O profile. There were two reasons for this behavior:
- The 3-way mirrored volumes running on the healthy cluster became 2-way mirrored volumes running on the two remaining online nodes. With 33 percent fewer backend drive write IOPS, the overall drive write latency decreased, which drove higher read and write IOPS. However, this is only in cases when CPU was not the bottleneck.
- Each of the two nodes remaining online were running double the VMs for a total of 64 VMs per node. The more VMs running on a virtualized host, the greater the potential for higher IOPS.
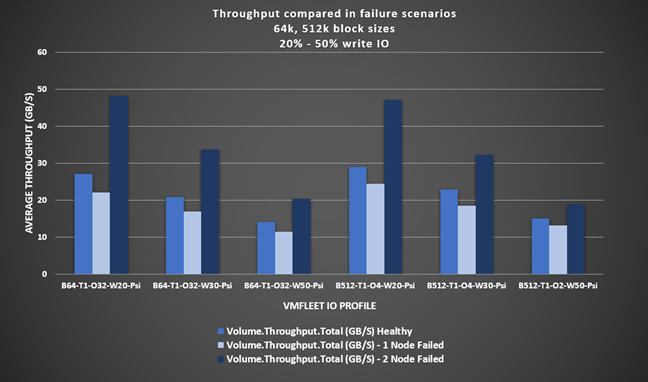
The following figure shows the throughput results from the VMFleet tests using I/O profiles with larger block sizes and sequential I/O patterns. Throughput decreased an average of 17 percent after the single-node failure. However, throughput increased by an average of 52 percent after the two-node failure for the same reasons as applied to Figure 10.
- The 3-way mirrored volumes running on the healthy cluster became 2-way mirrored volumes running on the two remaining online nodes. With 33 percent less backend drive write throughput, the overall drive write latency decreased, which drove higher read and write throughput. However, this is only in cases when CPU was not the bottleneck.
- Each of the two nodes remaining online were running double the VMs for a total of 64 VMs per node. The more VMs running on a virtualized host, the greater the potential for higher throughput.