
AutoML workflow with H2O Driverless AI
AutoML workflow with H2O Driverless AI
-
The following figure shows the steps in a typical AutoML workflow and how H2O Driverless AI enables these steps:
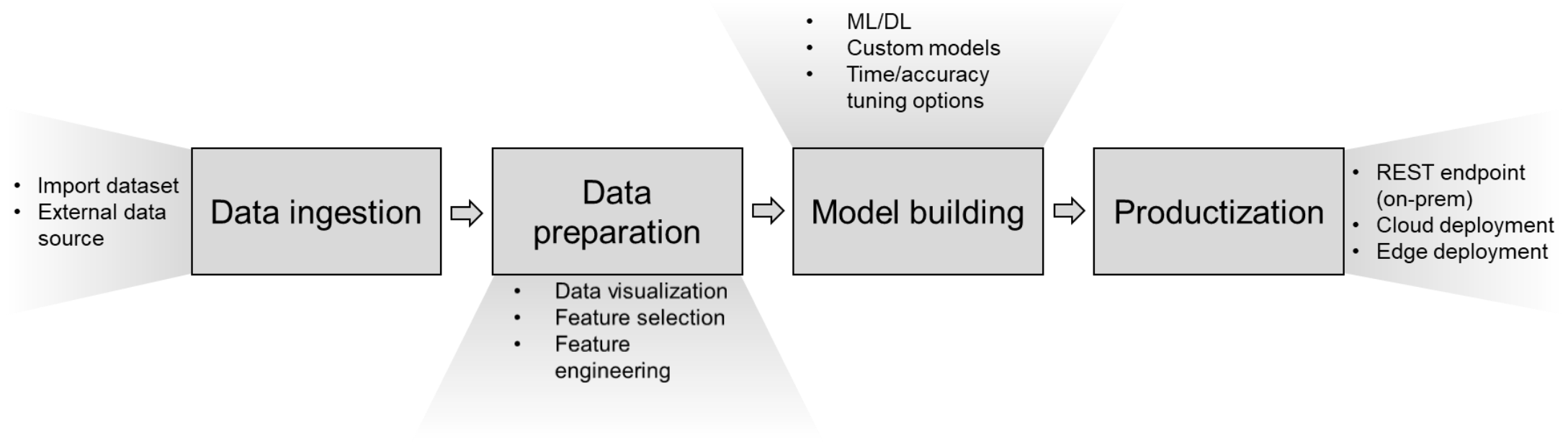
Figure 1. AutoML workflow in H2O Driverless AI
Data ingestion—The workflow begins with the data. Data ingestion consists of importing and obtaining data to perform analysis and training.
H2O Driverless AI can ingest data from datasets in various formats and file systems including Hadoop HDFS, Amazon S3 compatible storage, Azure Blob Storage, Google BigQuery, Google Cloud Storage, Apache Hive, JDBC, kdb+, MinIO, Snowflake, Data Recipe, Data Recipe File, and NFS. For larger datasets that are already available in PowerScale storage, H2O Driverless AI provides data connectors for accessing and ingesting data.
Data preparation—When the data is defined, the next step is data preparation. The dataset can be divided into training, test, and validation datasets. Data scientists can interactively model the data for exploration, analysis, and visualization using data plots and statistics. AutoML tools automatically perform feature engineering by extracting features (domain-specific attributes) from raw data and data transformations to suite ML algorithms.
H2O Driverless AI determines the best pipeline for a dataset, including automatic data transformation and feature engineering. Data scientists can control the number of original features used in model building by selecting or excluding columns in the dataset. H2O Driverless AI uses a unique genetic algorithm to automatically find new, high-value features and feature combinations for a specific dataset that are virtually impossible to find manually. The interface includes an easy-to-read variable importance chart that shows the significance of original and newly engineered features.
Automatic visualizations (AutoViz) in H2O Driverless AI provide robust exploratory data analysis capabilities by automatically selecting data plots based on the most relevant data statistics that are based on the data shape. In specific cases, AutoViz can suggest statistical transformation for some data. Experienced users can also customize visualizations to meet their needs. AutoViz helps users discover trends and issues such as large numbers of missing values or significant outliers that can impact modeling results.
Model building—When the data is prepared, the next step is model building. Automatic model building includes data transformations and hyperparameter tuning for the various models available in the AutoML product. It automatically trains several in-built models and selects the best model or a final ensemble of models based on user-defined parameters such as model accuracy.
Automatic model development in H2O Driverless AI is accomplished by running experiments. H2O Driverless AI trains multiple models and incorporates model hyperparameter tuning, scoring, and ensembling. Data scientists can configure parameters such as the accuracy, time, loss function, and interpretability for a specific experiment. This preview is automatically updated when any of the experiment’s settings change (including the knobs). Users can also run multiple diverse experiments that provide an overview of the dataset. This feature provides data scientists with relevant information for determining complexity, accuracy, size, and time tradeoffs when putting models into production. H2O Driverless AI uses a genetic algorithm that incorporates a ‘survival of the fittest’ concept to determine the best model for specific dataset and configured options automatically.
Productization—When the experiment is completed, you can make new predictions and push the model for production, either in the cloud, on-premises, or at the edge.
H2O Driverless AI offers convenient options for deploying machine learning models, depending on where the AI application is run:
- Download the model and build your own container.
- Download a scoring pipeline.
When the experiment (model building step) is complete, H2O Driverless AI can build a scoring pipeline that can be deployed to production. A scoring pipeline is a packaged experiment which includes artifacts necessary for model deployment, including model binary, runtime, readme, example, scripts, and so on. You can download two different types of scoring pipelines:
- Python Scoring Pipeline
- MOJO Scoring Pipeline, which is available with both Java and C++ backends
The decision about which type of pipeline to use comes from various factors including the type of model being built in the experiment, use case, latency requirements, and so on. In general, MOJO Scoring Pipelines are faster but might require additional setup, while Python Scoring Pipelines are built into a .whl file, which easily installable in Python. H2O Driverless AI also allows you to visualize the scoring pipeline as a directional graph, as shown in the following figure:
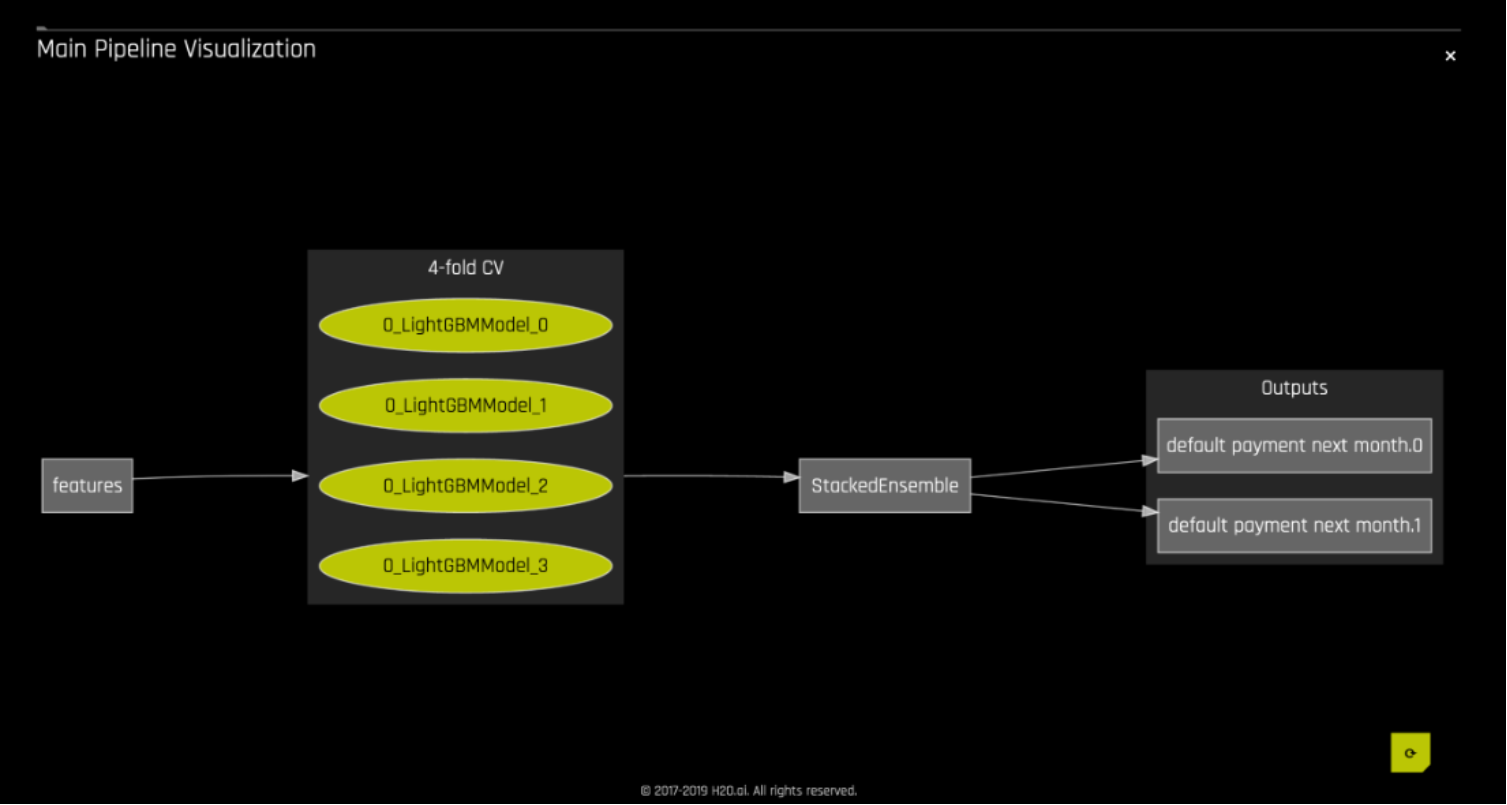
Figure 2. Visualization of H2O Driverless AI scoring pipeline
- Deploy the model directly in a cloud service.
- Configure the model to run on a local REST server with a couple of clicks.