
Optimized End-to-End ML Pipeline vs. Serial Pipeline
Optimized End-to-End ML Pipeline vs. Serial Pipeline
-
In this section, the performance of the optimized implementation (using Modin-Dask and oneDAL) is compared against the unoptimized version (using native panda and XGBoost [9] libraries), with a performance breakdown by the three stages in the pipeline. The comparison is performed for both the New York City (NYC) Taxi dataset and the Higgs dataset. The NYC dataset is used to study the performance of the regression function; the Higgs dataset is used to study the classification problem.
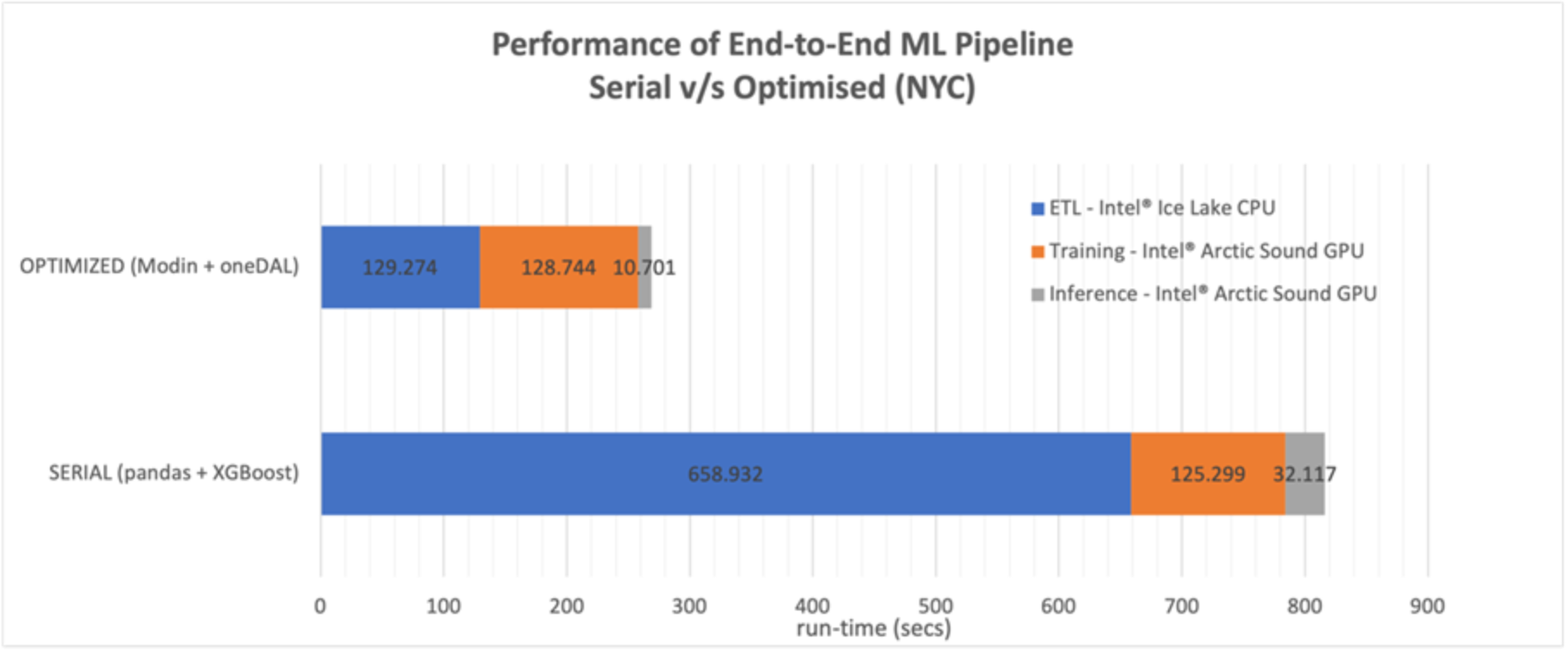
Figure 5. Performance of end-to-end ML Pipeline using the NYC Taxi dataset
The comparison results for the NYC dataset are shown in Figure 5. The overall speedup of the optimized pipeline is ~3x, with the following breakdown:
- The ETL stage shows a speedup of ~5x using Intel® oneAPI AI Analytics toolkit’s distribution of Modin with Dask due to efficient use of CPU cores.
- For the Inference stage, a speedup of ~3x is seen as it uses oneDAL with XGBoost [10] to utilize all the capabilities of the Intel hardware by using Intel® Advanced Vector Extensions 512 (AVX-512) [11] vector instruction set to maximize the utilization of the Intel® Xeon® processors.
- In the Training stage, XGBoost model training is converted to oneDAL using daal4py (overhead), hence taking slightly more time than the native pandas and XGBoost. However, because the data size for the NYC dataset is large (64GB), the overhead is proportionally negligible by comparison. But still, there is a slight slowdown in this stage.
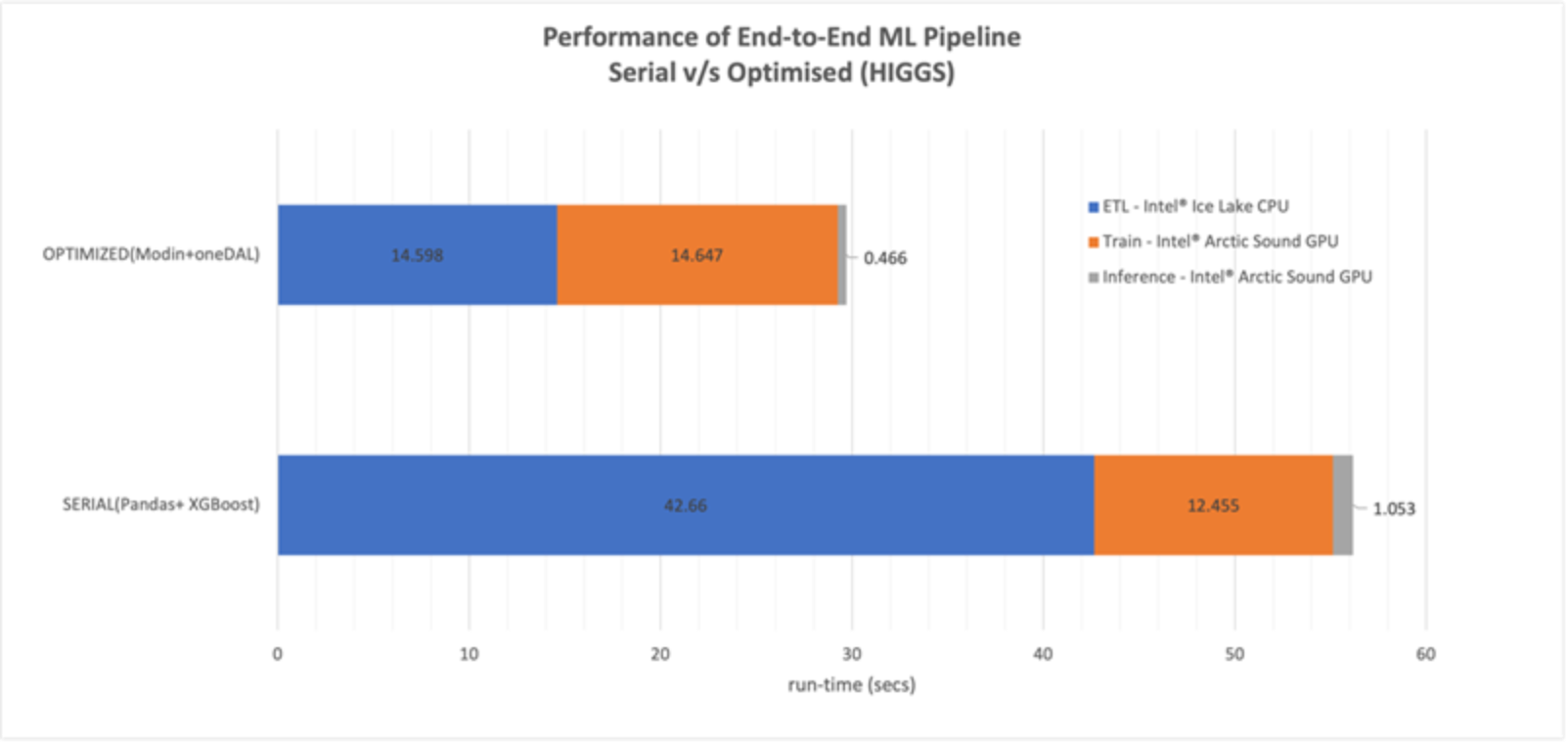
Figure 6. Performance of end-to-end ML Pipeline using the Higgs dataset
Shown in Figure 6 is the performance of the ML pipeline using the Higgs dataset. Again, the optimized implementation (using Modin-Dask and oneDAL) is compared against the native panda and XGBoost libraries, and the performance is also broken down by the three stages in the ML pipeline. Note that only 20 computing cores were used for processing the Higgs dataset. Because the Higgs dataset is relatively small (7.5 GB vs 64GB for the NYC dataset), it was not large enough to be effectively partitioned beyond 20 cores. The results show a speedup of ~3x for the ETL stage and a speedup of ~2.25x for the Inference stage. Again, the XGBoost model training is converted to oneDAL using daal4py, and because the Higgs dataset size is smaller than the NYC dataset, the overhead becomes more of a factor, that is, the Training stage for the optimized version is taking more time than native pandas and XGBoost in the Training stage. As a result, the overall speedup of the optimized pipeline is ~1.9x.