
ML Pipeline Performance: NYC Dataset, Varying Dataset Sizes
ML Pipeline Performance: NYC Dataset, Varying Dataset Sizes
-
In this section, the optimized code is used to study the pipeline performance based on the varying dataset size of the NYC dataset. The performance comparison is broken down for each of the three stages of the ML pipeline. Figure 7, Figure 8, and Figure 9 show the performance comparison of the ETL, Training, and Inference stages, respectively, for varying the dataset size of the NYC dataset. Figure 10 presents the composite performance (all three pipeline stages) of the E2E ML pipeline for the NYC dataset, summarizing the data from Figure 7, Figure 8, and Figure 9. The dataset is varied from 2 GB to 64 GB (increment of power of 2).
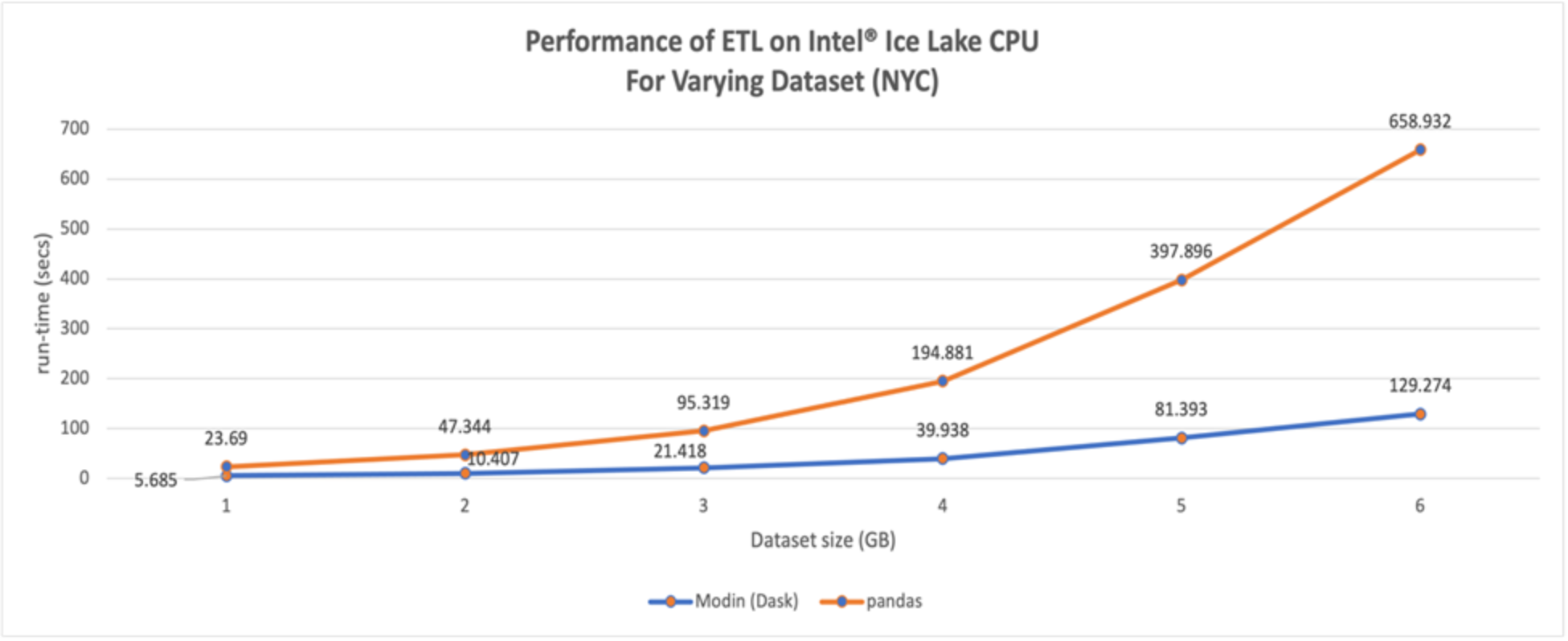
Figure 7. Performance of ML Pipeline ETL, varying NYC dataset size
Figure 7 shows a slight increase in speedup in the ETL stage of the ML pipeline as the size of the NYC dataset increases, ranging from ~4x at 2GB to ~4.8x at 16GB to ~5x at 64GB. As stated previously, the performance increase is due to Intel® AI Analytics toolkit’s distribution of Modin with Dask which uses all the CPU cores efficiently.
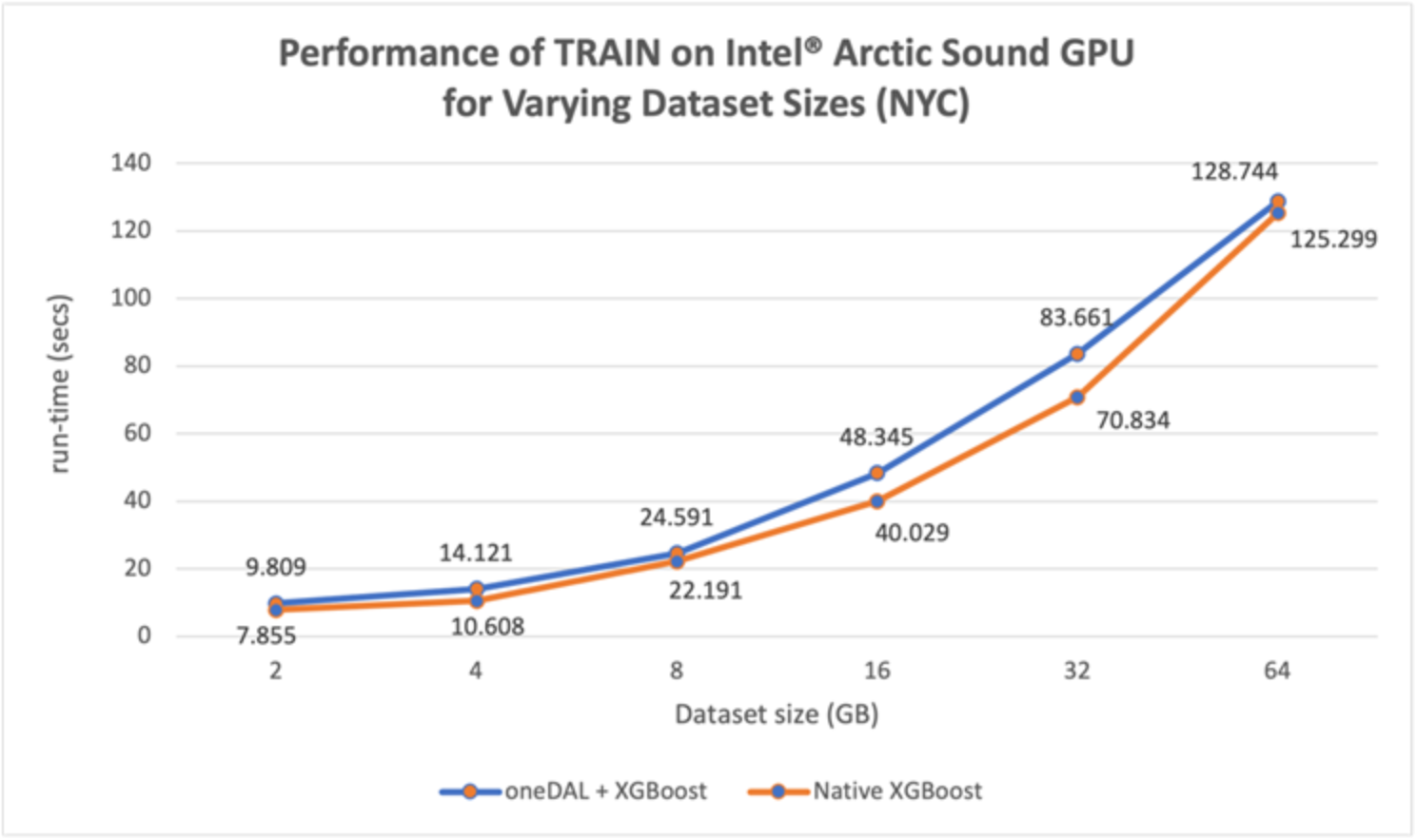
Figure 8. Performance of ML Pipeline Training, varying the NYC dataset size
Figure 8 shows the performance of the Training stage of the ML pipeline. As stated in Optimized End-to-End ML Pipeline vs. Serial Pipeline, in the Training stage, XGBoost model training is converted to oneDAL using daal4py (overhead). Hence, as confirmed in this figure, training in the optimized version takes slightly more time than the native pandas and XGBoost throughout the sizes of the NYC dataset. However, because the data size for the NYC dataset is large (64GB), the overhead is proportionally negligible by comparison.
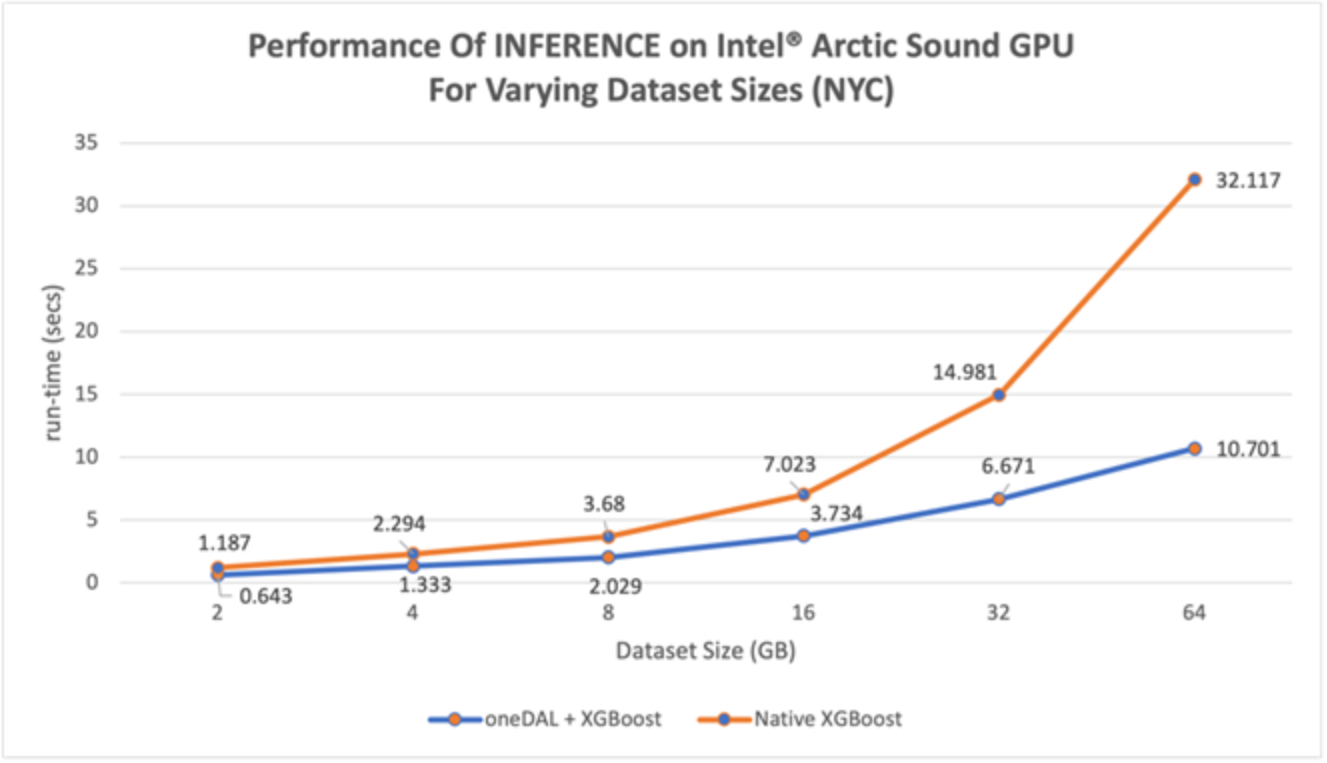
Figure 9. Performance of ML Pipeline Inference, varying NYC dataset size
For the Inference stage, shown in Figure 9, there is an increase in speedup as the dataset size increases, from ~1.8x at 2GB to the largest speedup of ~3x at 64GB. As stated previously, the performance boost is due to the Intel® Advanced Vector Extensions 512 (Intel® AVX-512) vector instruction set which maximizes the utilization of the Intel® Xeon® processors.
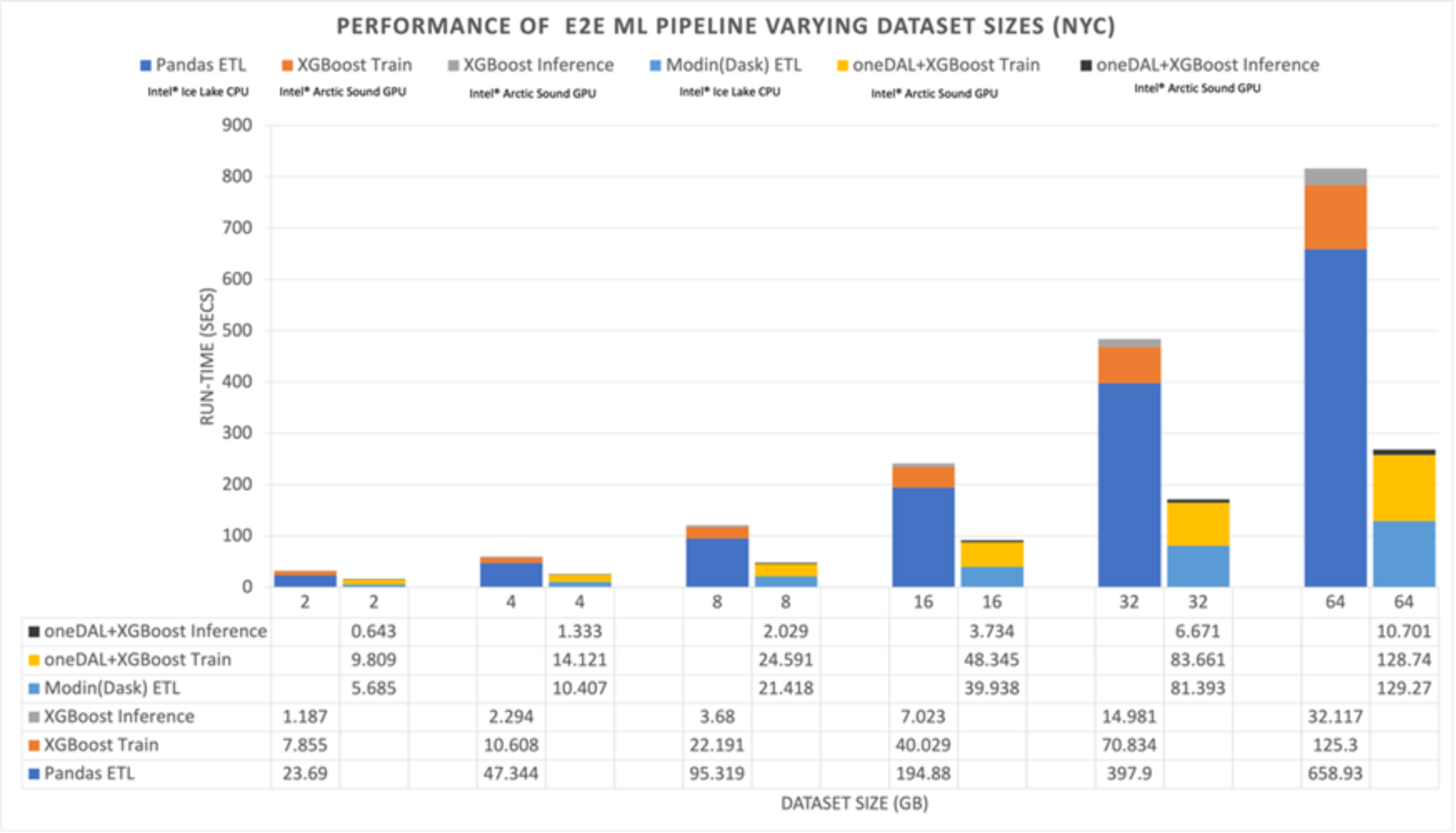
Figure 10. Composite E2E ML pipeline performance, varying NYC dataset size
Figure 10 shows the composite performance (all three pipeline stages) of the E2E ML pipeline for the NYC dataset, summarizing the data from Figure 7, Figure 8, and Figure 9. We can see (confirmed) that the ETL stage is the most time-consuming stage in the pipeline, for all dataset sizes. The Training stage cannot be accelerated at all by the AI Analytics Toolkit. In fact, at small dataset sizes, the overhead of the Training stage is especially noticeable. The overall speedup of the E2E pipeline increases steadily from ~2x at 2GB to ~2.6x at 16GB to the maximum speedup of ~3x for 64G.