
ML Pipeline Performance: Higgs Dataset, Varying Dataset Sizes
ML Pipeline Performance: Higgs Dataset, Varying Dataset Sizes
-
In this section, the optimized code is used to study the pipeline performance based on the varying size of the Higgs dataset. The performance comparison is broken down for each of the three stages of the ML pipeline. Figure 11, Figure 12, and Figure 13 show the performance comparison of the ETL, Training, and Inference stages, respectively, for varying the size of the Higgs dataset. Figure 14 presents the composite performance (all three pipeline stages) of the E2E ML pipeline for the Higgs dataset, summarizing the data from Figure 11, Figure 12, and Figure 13.
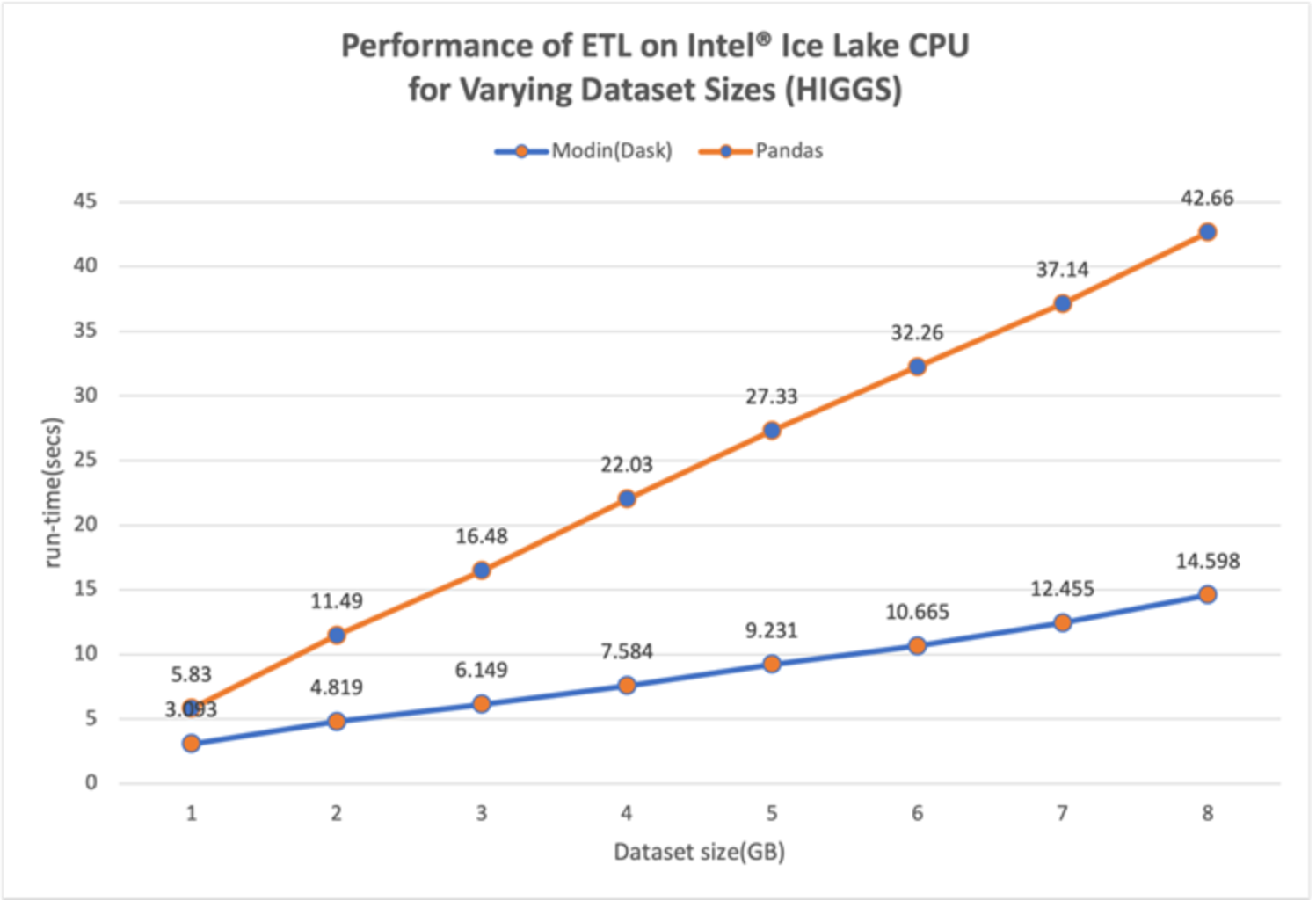
Figure 11. Performance of ML Pipeline ETL, varying Higgs dataset size
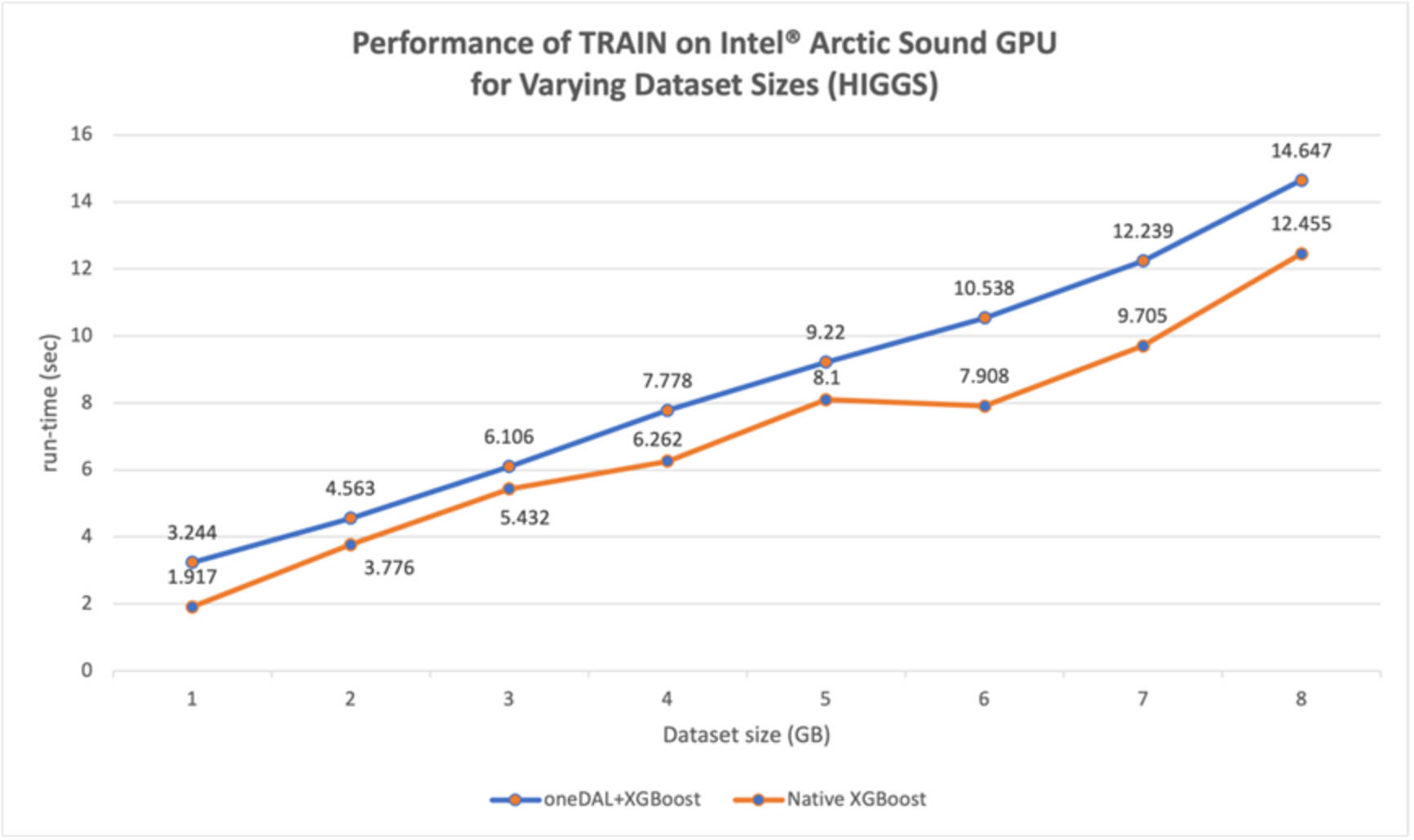
Figure 12. Performance of ML Pipeline Training, varying Higgs dataset size
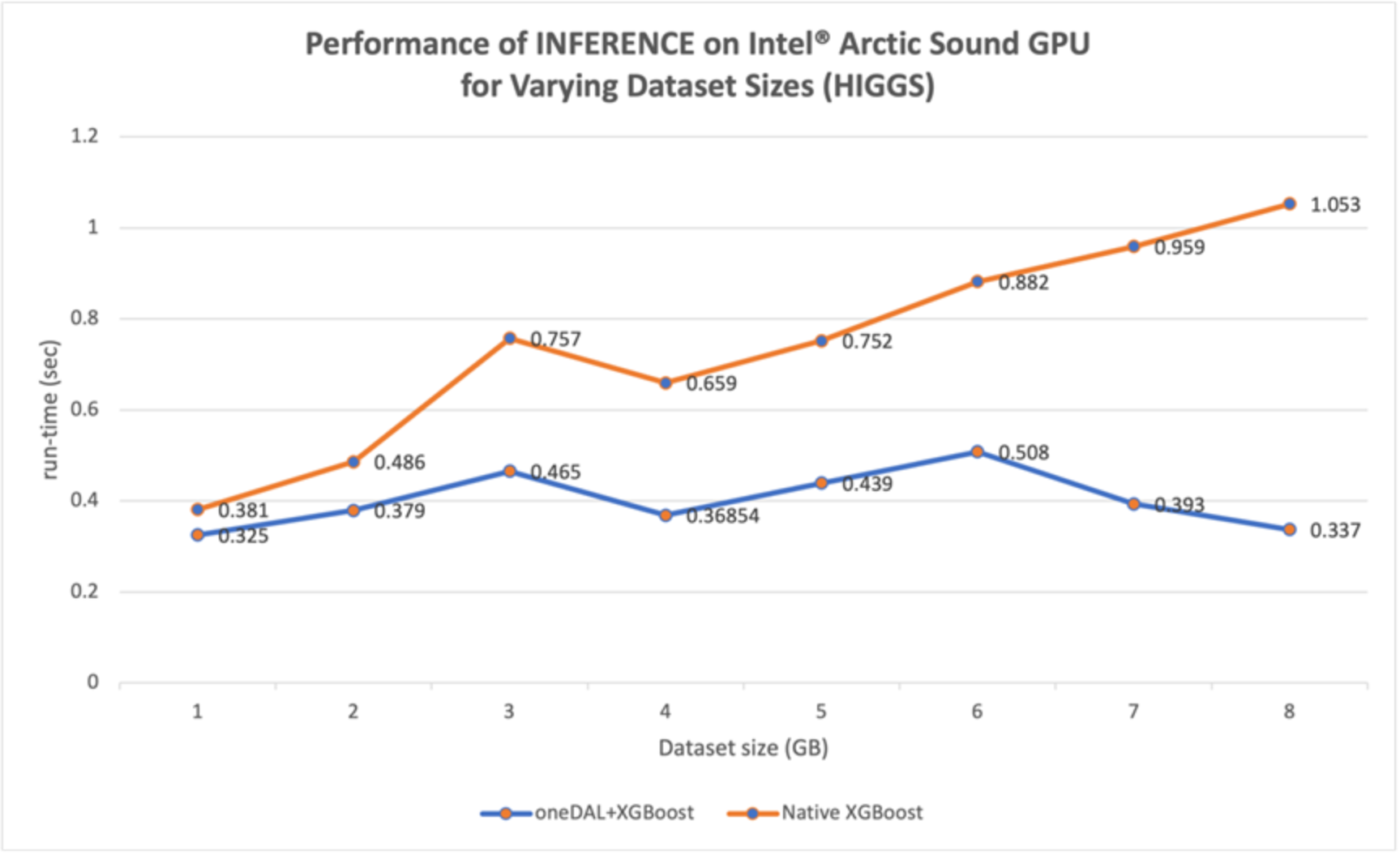
Figure 13. Performance of ML Pipeline Inference, varying Higgs dataset size
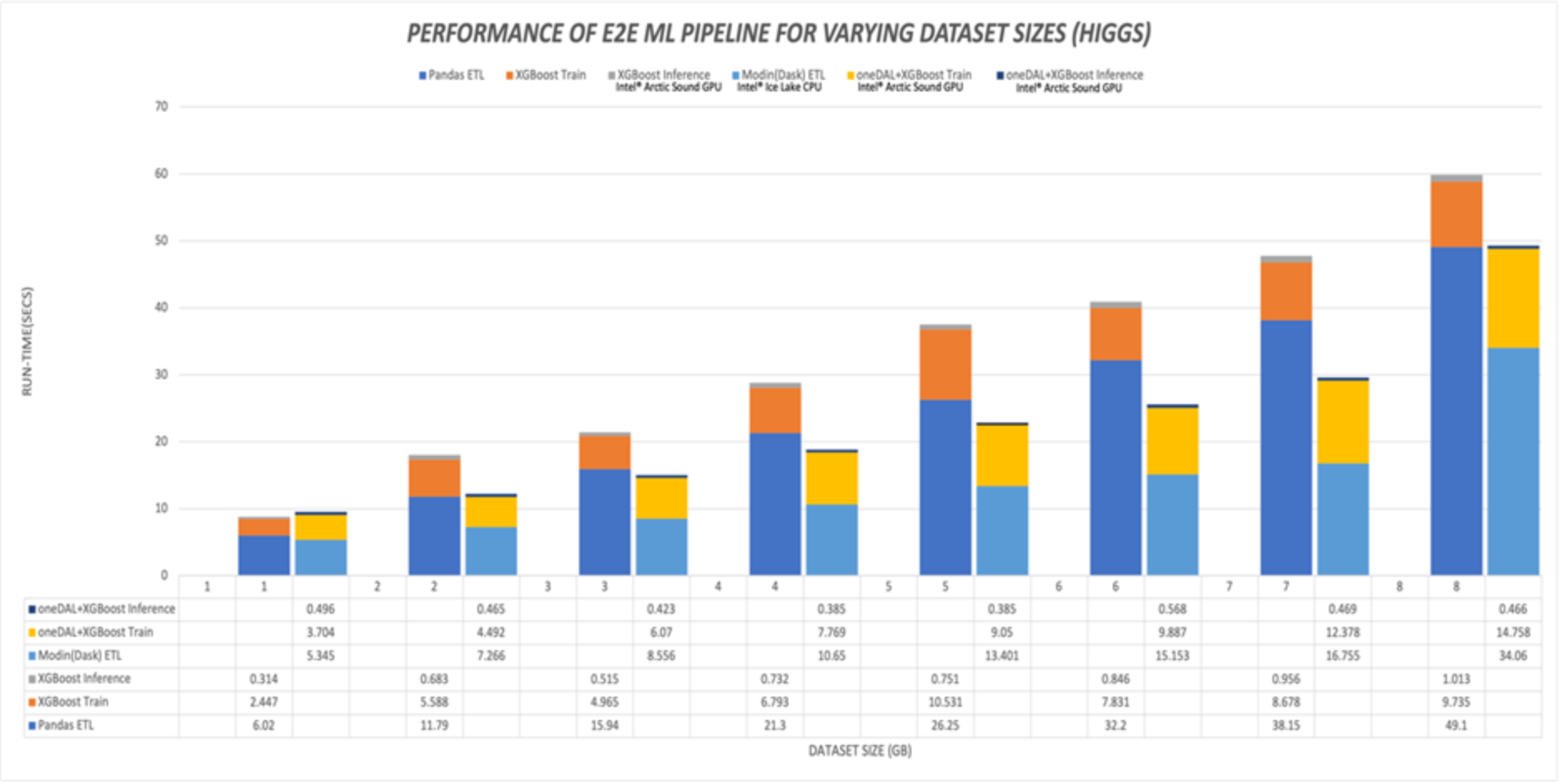
Figure 14. Composite E2E ML pipeline performance, varying Higgs dataset size
The Higgs dataset was varied from 1 GB to 7.5 GB (increment of 1 GB). The following is a summary of the observations:
- For the ETL stage (Figure 11), there is a steady increase in speedup, ranging from ~1.9x at 1GB to ~2.9x at 4GB to ~3x at 7.5GB. The performance boost is again because of Intel® AI Analytics toolkit’s distribution of Modin with Dask which uses all the CPU cores efficiently.
- For the Training stage (Figure 12), the baseline pandas performed better (confirming this observation made in Figure 6). As stated previously, the XGBoost model training is converted to oneDAL using daal4py, which added the overhead. Because the Higgs dataset size is smaller than the NYC dataset, the overhead becomes more of a factor.
- Finally, for the Inference stage (Figure 13), there is an increase in speedup as the dataset size increases (similar to the NYC dataset), from slightly >1x at 1GB to ~1.8x at 4GB to the largest speedup of >3x at 7.5GB. The performance boost is again due to the Intel® Advanced Vector Extensions 512 (Intel® AVX-512) vector instruction set which maximizes the utilization of the Intel® Xeon® processors.
- Figure 14 shows the composite performance (all three pipeline stages) of the E2E ML pipeline for the Higgs dataset, summarizing the data from Figure 11, Figure 12, and Figure 13. Similar to the observation of the NYC dataset, we can see that the ETL stage is the most time-consuming stage in the pipeline, for all dataset sizes and the Training cannot be accelerated at all by the AI Analytics Toolkit. At very small dataset sizes (1GB, 2GB), the overall E2E pipeline speedup is very modest. Beyond 2GB, the speedup stayed fairly constant at <2x, with a speedup of ~1.9x at 7.5GB. In summary, the Higgs dataset is too small to take full advantage of the parallel benefits offered by the AI Analytics Toolkit.