
Evaluation of oneAPI compatible ETL libraries
Evaluation of oneAPI compatible ETL libraries
-
As stated, the ETL stage is the most time-consuming stage in the ML Pipeline and thus, it is essential to optimize this stage. In this section, we compare the ETL performance when implemented using Modin ([8] (with Ray, Dask, and Omnisci backends) against the native pandas library. Because the performance of the ETL stage depends mainly on the size of the dataset, the evaluation for the ETL stage was performed using the NYC Taxi dataset at 64GB. Also, we determined experimentally that the best performance occurs when the maximum number of CPU cores (96) are used to process the 64 GB dataset. Thus, all 96 CPU cores are used when studying the NYC dataset.
As shown in Figure 2, for the ETL stage of the ML pipeline, all three Modin backends performed better than the baseline serial panda library. Modin-Dask was the best performing, with a ~5x speedup vs. the serial pandas library. These results are as expected because the Modin API can efficiently use all available CPU cores to process data in parallel. Additionally, Modin promotes parallelism by supporting both row and column cell-oriented partitioning of a dataframe. The Modin API transparently reshapes the partitioning of the dataframe based on the operation being performed. This allows Modin to support the pandas API efficiently. Modin’s fine-grained control over partitioning allows it to support various pandas operations that are otherwise very challenging to parallelize. Also, Modin with Dask as backend is the fastest because it supports more of the pandas API as compared to the Ray and OmniSci and hence minimal operations must be defaulted to its original pandas implementations.
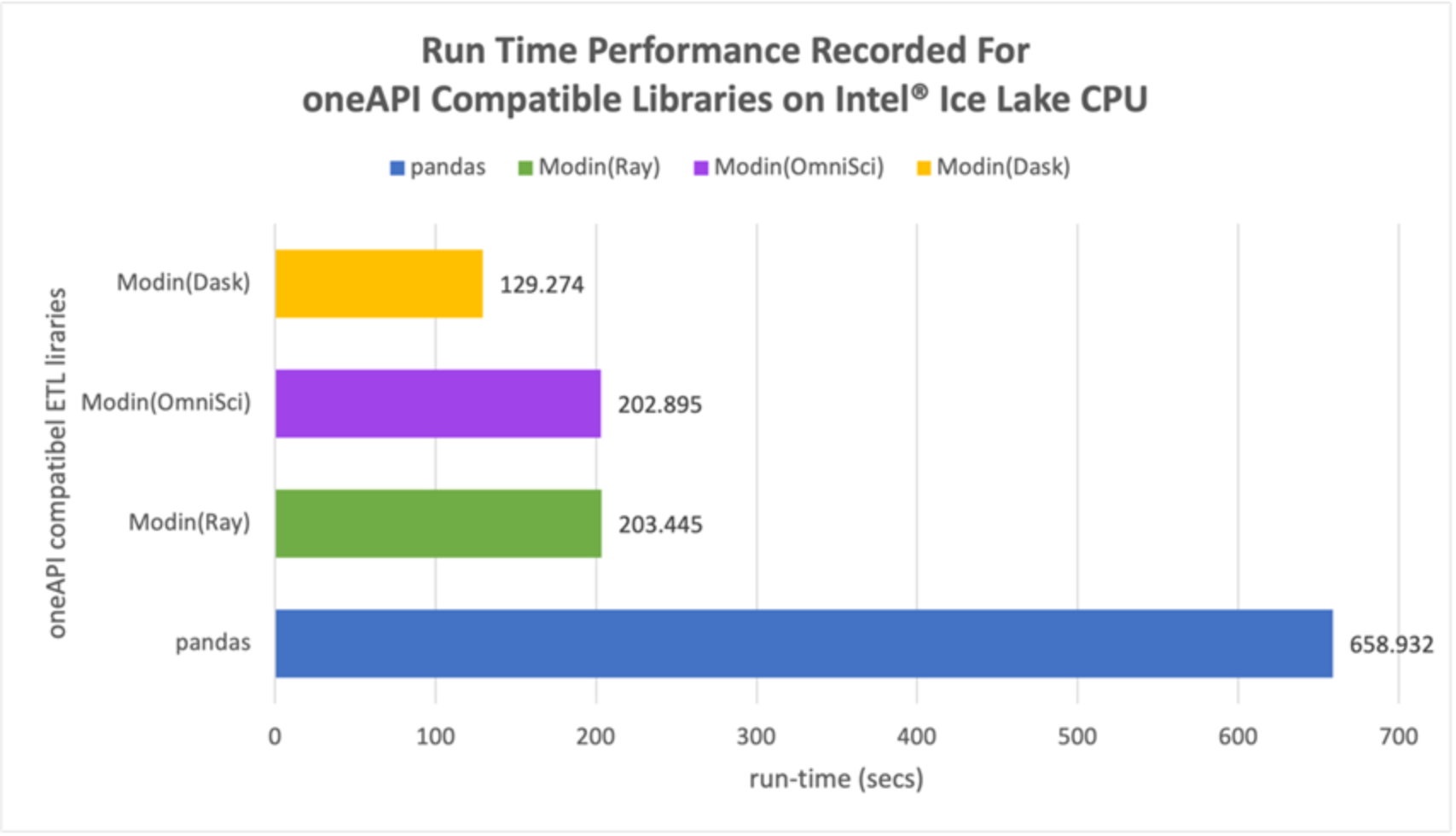
Figure 2. Performance comparison of Modin libraries and native pandas library
The performance comparison is further broken down into the most commonly used ETL functions: df.read_csv, df.rename, df.drop, df.fillna, and df.concat [8]. The results are shown in Figure 3 and Figure 4. Figure 3 shows the run time (in secs) of each ETL function for the serial pandas library vs. Modin-Dask. The corresponding speedups can be observed in Figure 4. Note that df.drop (~110x) and df.rename (~75x) have tremendous speedups, however, their corresponding run times are very small, thus contributing very little to the overall speedup. The most time consuming ETL functions shown in Figure 3 are df.read.csv and df.concat, which have speedups of ~4.6x and ~9.4x, respectively. Finally, the performance of the overall ETL stage (~5x shown in Figure 2) is limited by the serial performance of another ETL function df.query, which is used to divide the dataframe into train and test samples. Because this function is not completely supported by Modin, there is a computational penalty involved to convert Modin’s partitioned dataframe to serial pandas.
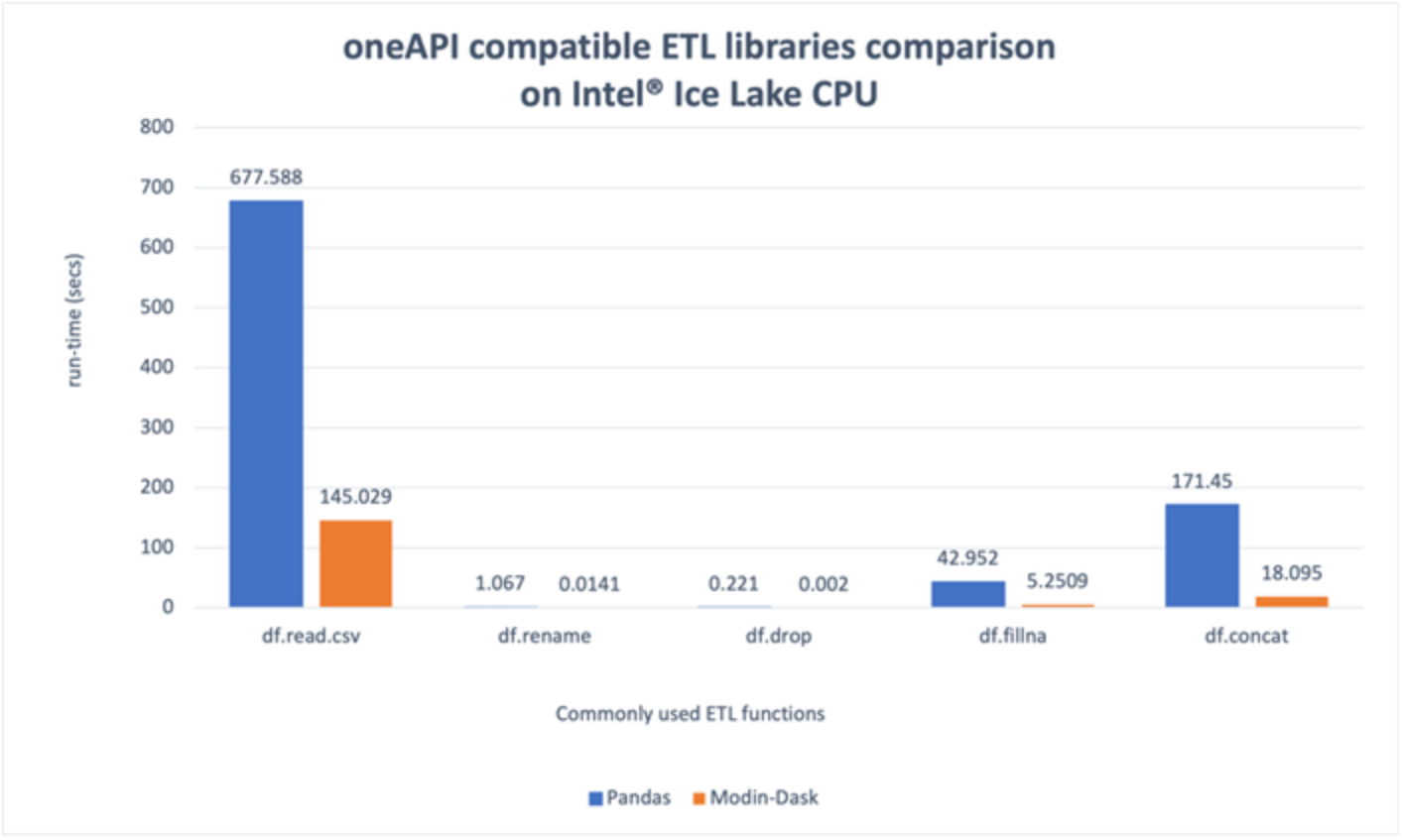
Figure 3. Run time of ETL functions: Modin-Dask vs. native pandas
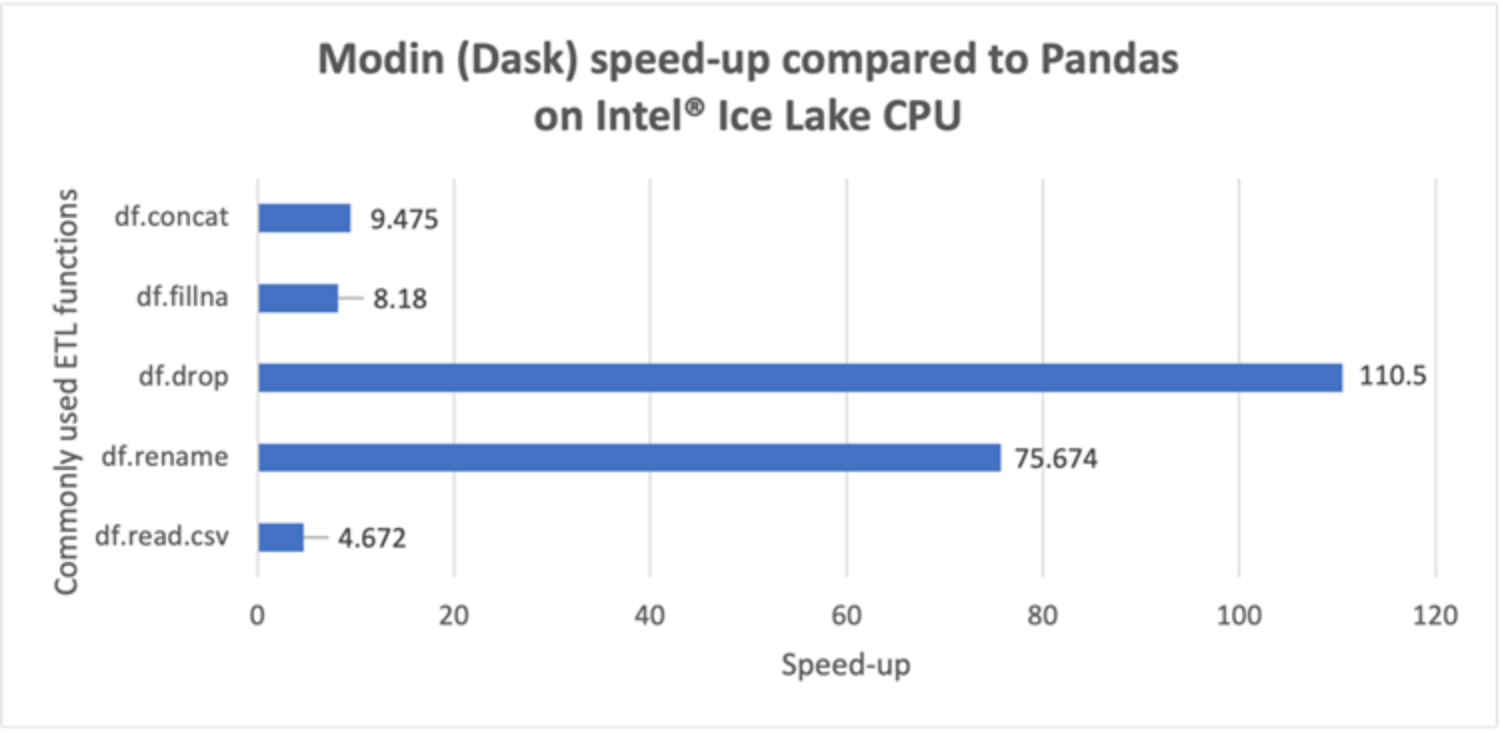
Figure 4. Speedup using Modin-Dask vs. native pandas
Based on these results, we optimized the ETL stage of our ML pipeline by using Modin-Dask. In the next section, the optimized implementation of the ML pipeline is compared to the performance of a serial baseline pandas implementation on an Intel® DevCloud node.