




Scaling Deep Learning Workloads in a GPU Accelerated Virtualized Environment
Introduction
Demand for compute, parallel, and distributed training is ever increasing in the field of deep learning (DL). The introduction of large-scale language models such as Megatron-Turing NLG (530 billion parameters; see References 1 below) highlights the need for newer techniques to handle parallelism in large-scale model training. Impressive results from transformer models in natural language have paved a way for researchers to apply transformer-based models in computer vision. The ViT-Huge (632 million parameters; see References 2 below) model, which uses a pure transformer applied to image patches, achieves amazing results in image classification tasks compared to state-of-the-art convolutional neural networks.
Larger DL models require more training time to achieve convergence. Even smaller models such as EfficientNet (43 million parameters; see References 3 below) and EfficientNetV2 (24 million parameters; see References 3 below) can take several days to train depending on the size of data and the compute used. These results clearly show the need to train models across multiple compute nodes with GPUs to reduce the training time. Data scientists and machine learning engineers can benefit by distributing the training of a DL model across multiple nodes. The Dell Validated Design for AI shows how software-defined infrastructure with virtualized GPUs is highly performant and suitable for AI (Artificial Intelligence) workloads. Different AI workloads require different resources sizing, isolation of resources, use of GPUs, and a better way to scale across multiple nodes to handle the compute-intensive DL workloads.
This blog demonstrates the use and performance across various settings such as multinode and multi-GPU workloads on Dell PowerEdge servers with NVIDIA GPUs and VMware vSphere.
System Details
The following table provides the system details:
Table 1: System details
Component | Details |
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe |
Network Adapter | Mellanox ConnectX-6 Dual port 100 GbE |
Storage | Dell PowerScale |
ESXi Version | 7.0.3 |
BIOS Version | 1.1.3 |
GPU Driver Version | 470.82.01 |
CUDA Version | 11.4 |
Setup for multinode experiments
To achieve the best performance for distributed training, we need to perform the following high-level steps when the ESXi server and virtual machines (VMs) are created:
- Enable Address Translation Services (ATS) on VMware ESXi and VMs to enable peer to peer (P2P) transfers with high performance.
- Enable ATS on the ConnectX-6 NIC.
- Use the ibdev2netdev utility to display the installed Mellanox ConnectX-6 card and mapping between logical and physical ports, and enable the required ports.
- Create a Docker container with Mellanox OFED drivers, Open MPI Library, and NVIDIA optimized TensorFlow (the DL framework that is used in the following performance tests).
- Set up a keyless SSH login between VMs.
- When configuring multiple GPUs in the VM, connect the GPUs with NVLINK.
Performance evaluation
For the evaluation, we used VMs with 32 CPUs, 64 GB of memory, and GPUs (depending on the experiment). The evaluation of the training performance (throughput) is based on the following scenarios:
- Scenario 1—Single node with multiple VMs and multi-GPU model training
- Scenario 2—Multinode model training (distributed training)
Scenario 1
Imagine the case in which there are multiple data scientists working on building and training different models. It is vital to strictly isolate resources that are shared between the data scientists to run their respective experiments. How effectively can the data scientists use the resources available?
The following figure shows several experiments on a single node with four GPUs and the performance results. For each of these experiments, we run tf_cnn_benchmarks with the ResNet50 model with a batch size of 1024 using synthetic data.
Note: The NVIDIA A100 GPU supports a NVLink bridge connection with a single adjacent NVIDIA A100 GPU. Therefore, the maximum number of GPUs added to a single VM for multi-GPU experiments on a Dell PowerEdge R750xa server is two.
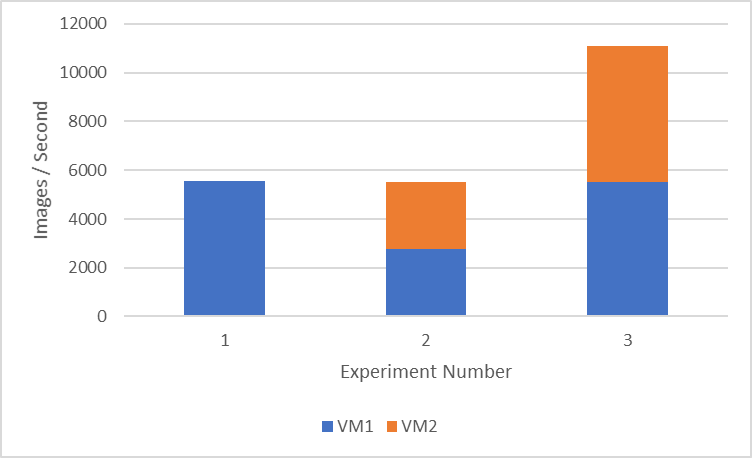
Figure 1: Performance comparison of multi-VMs and multi-GPUs on a single node
Figure 1 shows the throughput (the average on three runs) of three different experiment setups:
- Setup 1 consists of a single VM with two GPUs. This setup might be beneficial to run a machine learning workload, which needs more GPUs for faster training (5500 images/second) but still allows the remaining resources in the available node for other data scientists to use.
- Setup 2 consists of two VMs with one GPU each. We get approximately 2700 images/second on each VM, which can be useful to run multiple hyper-parameter search experiments to fine-tune the model.
- Setup 3 consists of two VMs with two GPUs each. We use all the GPUs available in the node and show the maximum cumulative throughput of approximately 11000 images/second between two VMs.
Scenario 2
Training large DL models requires a large amount of compute. We also need to ensure that the training is completed in an acceptable amount of time. Efficient parallelization of deep neural networks across multiple servers is important to achieve this requirement. There are two main algorithms when we address distributed training, data parallelism, and model parallelism. Data parallelism allows the same model to be replicated in all nodes, and we feed different batches of input data to each node. In model parallelism, we divide the model weights to each node and the same minibatch data is trained across the nodes.
In this scenario, we look at the performance of data parallelism while training the model using multiple nodes. Each node receives different minibatch data. In our experiments, we scale to four nodes with one VM and one GPU each.
To help with scaling models to multiple nodes, we use Horovod (see References 6 below ), which is a distributed DL training framework. Horovod uses the Message Passing Interface (MPI) to effectively communicate between the processes.
MPI concepts include:
- Size indicates the total number of processes. In our case, the size is four processes.
- Rank is the unique ID for each process.
- Local rank indicates the unique process ID in a node. In our case, there is only one GPU in each node.
- The Allreduce operation aggregates data among multiple processes and redistributes them back to the process.
- The Allgather operation is used to gather data from all the processes.
- The Broadcast operation is used to broadcast data from one process identified by root to other processes.
The following table provides the scaling experiment results:
Table 2: Scaling experiments results
Number of nodes | VM Throughput (images/second) |
1 | 2757.21 |
2 | 5391.751667 |
4 | 10675.0925 |
For the scaling experiment results in the table, we run tf_cnn_benchmarks with the ResNet50 model with a batch size of 1024 using synthetic data. This experiment is a weak scaling-based experiment; therefore, the same local batch size of 1024 is used as we scale across nodes.
The following figure shows the plot of speedup analysis of scaling experiment:
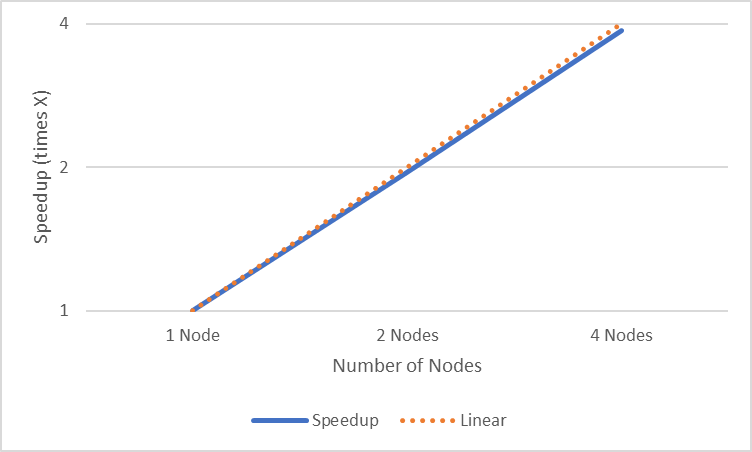
Figure 2: Speedup analysis of scaling experiment
The speedup analysis in Figure 2 shows the speedup (times X) when scaling up to four nodes. We can clearly see that it is almost linear scaling as we increase the number of nodes.
The following figure shows how multinode distributed training on VMs compares to running the same experiments on bare metal (BM) servers:
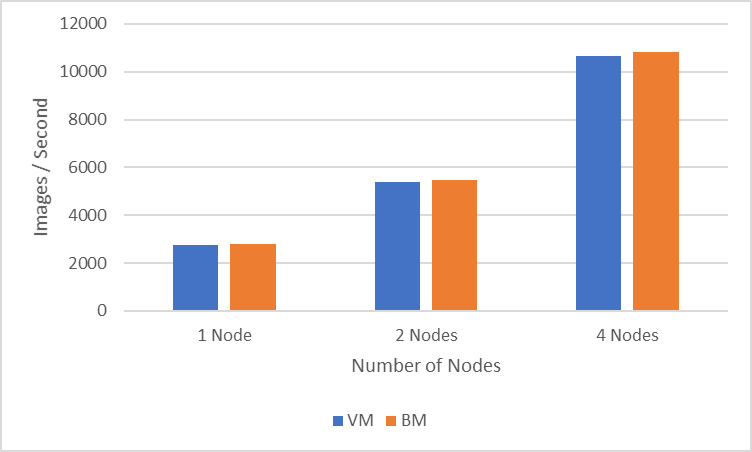
Figure 3: Performance comparison between VMs and BM servers
The four-nodes experiment (one GPU per node) achieves a throughput of 10675 images/second in the VM environment while the similarly configured BM run achieves a throughput of 10818 images/second. One-, two-, and four-node experiments show a percentage difference of less than two percent between BM experiments and VM experiments.
Conclusion
In this blog, we described how to set up the ESXi server and VMs to be able to run multinode experiments. We examined various scenarios in which data scientists can benefit from multi-GPU experiments and their corresponding performance. The multinode scaling experiments showed how the speedup is closer to linear scaling. We also examined how VM-based distributed training compares to BM-server based distributed training. In upcoming blogs, we will look at best practices for multinode vGPU training, and the use and performance of NVIDIA Multi-Instance GPU (MIG) for various deep learning workloads.
References
- Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- EfficientNetV2: Smaller Models and Faster Training
- Virtualizing GPUs for AI with VMware and NVIDIA Based on Dell Infrastructure Design Guide
- https://github.com/horovod/horovod
Contributors
Contributors to this blog: Prem Pradeep Motgi and Sarvani Vemulapalli