




Running Grok-1 on JAX with Multiple GPUs on the Dell PowerEdge XE9680 Server
Mon, 19 Aug 2024 17:48:10 -0000
|Read Time: 0 minutes
Overview
The PowerEdge XE9680 server featuring the AMD MI300x GPU offers competitive support for AI workloads. The AMD Instinct MI300X GPU boasts impressive capabilities for running deep learning workloads. The upstream convergence of optimizations to different deep learning frameworks is not trivial. AMD has been successful in integrating their GPUs to function well in major deep learning frameworks such as PyTorch, JAX, and TensorFlow. In this blog, we explore why it is nontrivial to upstream (allow support for) new GPU hardware into deep learning frameworks like JAX. Additionally, we demonstrate how to run the Grok mixture of experts (MoE) model by xAI with JAX. This blog provides additional information for the recently released Generative AI with AMD Accelerators design guide.
The following figure shows the PowerEdge XE9680 server:

Figure 1: PowerEdge XE9680 server front view
The following figure shows the AMD MI300x GPU:

Figure 2: Eight AMD MI300x GPUs
Benefits
The PowerEdge XE9680 server with AMD MI300x GPUs for deep learning workloads offers many benefits to customers.
The PowerEdge XE9680 server, equipped with the AMD Instinct MI300X GPU, delivers high-performance capabilities for enterprises aiming to unlock the value of their data and differentiate their business with customized large language models (LLMs), as shown in the following figure:
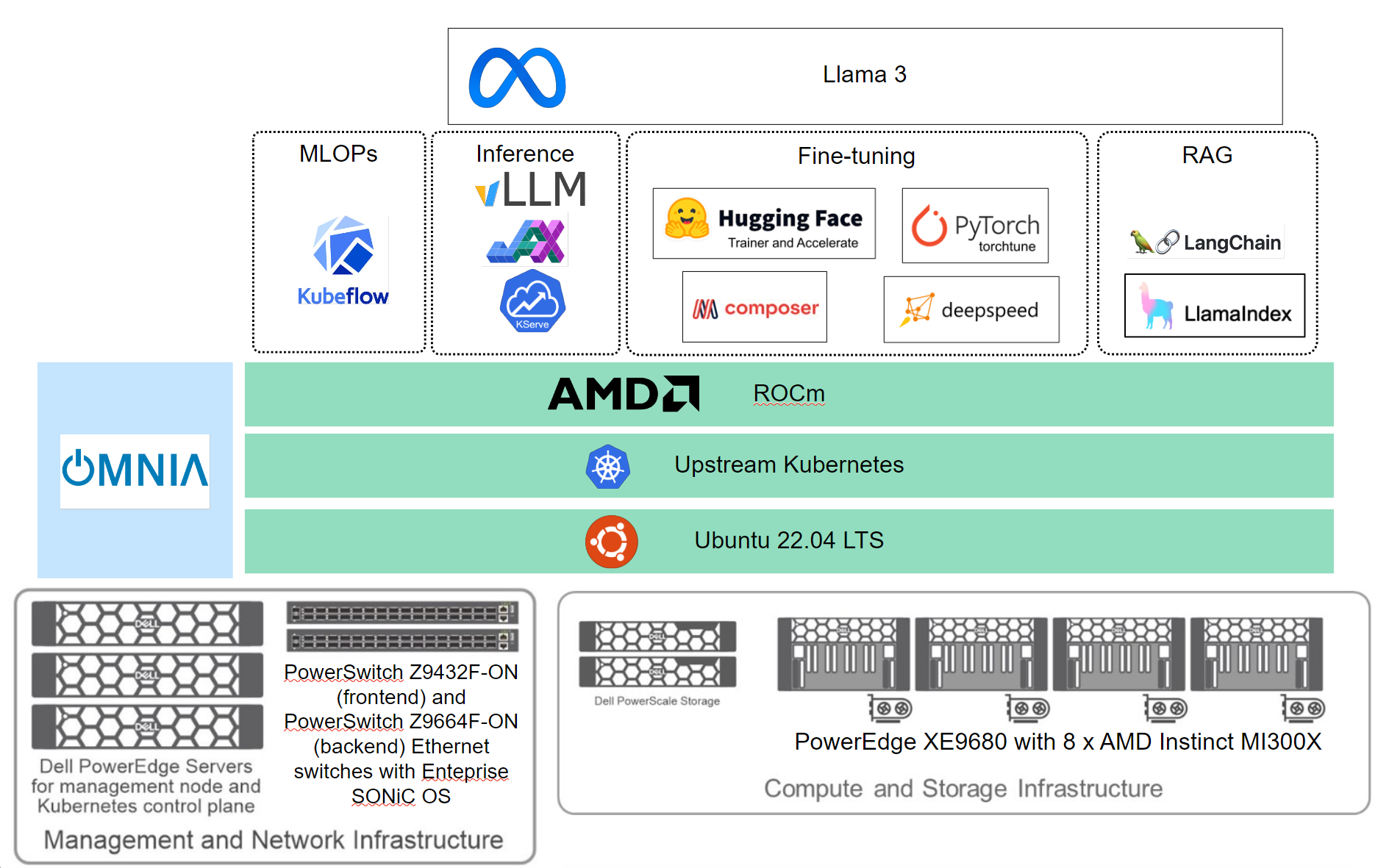
Figure 3: Hardware and software infrastructure for the Dell-validated generative AI solution with AMD GPUs
Featuring eight MI300X GPUs with 192 GB HBM3 memory at 5.3 TB/s, each PowerEdge XE9680 server boasts over 21 petaflops of FP16 performance. This combination is set to democratize access to generative AI, enabling enterprises to train larger models, reduce data center footprints, lower total cost of ownership (TCO) and gain a competitive edge. While these results are highly impressive, achieving ease of use with popular deep learning frameworks poses several challenges. It is crucial for data scientists and machine learning engineers to have native support for these frameworks to benefit fully from them. AMD has successfully navigated the complex path to upstreaming, overcoming numerous challenges.
Challenges and benefits of upstreaming to deep learning frameworks
The challenges and benefits upstreaming to deep learning frameworks such as JAX include the following:
ROCm platform─ROCm serves as a fundamental software building block for AMD GPUs, which is distinct from other GPU computing platforms. This difference is more than just high-level details. It touches the fundamental depth of how instructions are run on the GPU.
Instruction set─AMD GPUs use the ROCm platform, which requires different instruction sets, such as CDNA3, compared to other instruction sets. This divergence implies that code optimized for one platform might not run at all or if it does run, it will underperform. Adapting software to use these instruction sets effectively is a formidable task. It requires in-depth knowledge of both the ROCm platform and the specific optimizations it supports. These optimizations can include:
- Rewriting kernel functions to match ROCm's execution model
- Adjusting memory access patterns to align with AMD GPU architecture
- Reimplementing certain algorithms to take advantage of ROCm-specific features
Note: To remove the overhead of learning, AMD uses Heterogeneous Compute Interface for Portability (HIP), which serves as a straightforward porting mechanism to use these optimizations without needing to rewrite code. However, for maximum performance, some level of optimization specific to the AMD architecture might be beneficial.
Memory hierarchy─Effectively using memory hierarchy including the use of High Bandwidth Memory, different cache hierarchies can significantly differ from other GPUs. The appropriate use of this memory architecture to accelerate workloads is vital and requires customized memory management and optimization techniques.
Compute unit optimization─The compute unit’s organization of AMD GPUs can vary significantly from other architectures, and compute units must be fully consumed. This variance affects how parallelism is exploited on each platform. Furthermore, it is vital to adjust aspects such as work group sizes and memory layouts, allowing to integrate ROCm-specific libraries and tools to work with hardware.
Integration with Accelerated Linear Algebra (XLA)─JAX relies heavily on XLA for optimizing and compiling code to run on various hardware including GPUs and TPUs. Adding XLA support to AMD GPUs requires significant modifications, specific to AMD’s ROCm platform. This modification not only ensures compatibility but also optimizes performance to match or exceed existing solutions. While support for XLA is evolving and significant progress has been made, it is a vital key component to allow JAX to run.
The ability of AMD GPUs to run JAX workloads without code modification is due to the robust integration of ROCm with XLA, the availability of prebuilt packages, and JAX's automatic hardware detection capabilities. These factors collectively enable a seamless experience for users, allowing them to use AMD GPUs for their JAX-based computations with minimal setup effort.
Functional programming and GPU architecture─JAX's functional programming paradigm, which is beneficial for parallel processing on GPUs, must be adapted to work efficiently with AMD's GPU architecture. This functional programming paradigm ensures that the functional purity and side-effect-free nature of JAX code is maintained while optimizing for AMD's hardware specifics. It can be particularly challenging because AMD's architecture might have different performance characteristics and bottlenecks compared to other architectures. It might be necessary to adapt the XLA backend to generate efficient code for AMD's unique memory hierarchy, compute unit organization, and cache behavior. The challenge lies in fine-tuning parallel computation strategies and memory access patterns to use AMD's architectural strengths fully, while maintaining JAX's cross-platform portability. Achieving this balance requires in-depth knowledge of both JAX's internals and AMD's hardware specifics, but promises significant performance gains.
Existing toolchains─The existing ecosystem of tools and libraries on which JAX depends, such as specialized GPU-accelerated numerical computing packages, are primarily optimized for an existing GPU architecture. Rewriting or adapting these tools to work with alternative GPU platforms is a nontrivial task. It requires not only porting but also extensive testing to ensure that performance and functionality remain consistent across different hardware platforms.
Open-source gains─Because both JAX and ROCm are open source, they allow for community contributions, collaboration, transparency, customization, ecosystem expansion, reduced vendor constraints, and a better understanding of hardware to software interactions that opens possible avenues for research.
Overview of Grok-1
Grok-1, with 314 billion parameters, is approximately twice the size of models like GPT-3, enhancing its potential ability to handle nuanced and complex interactions.
Model architecture
Grok-1 is built as a mixture of experts (MoE) model, using two out of eight experts per token, thereby optimizing computational efficiency by activating only 25 percent of its weights for each input token. Grok-1 is an autoregressive transformer-based language model that incorporates multihead attention, feed-forward neural networks, MoE layers, and rotary embeddings for positional encoding. The model features 64 layers, with 48 attention heads for queries and eight attention heads for keys and values. It has an embedding size of 6,144. Grok-1 uses the SentencePiece tokenizer with a vocabulary of 131,072 tokens. Additional features include rotary embeddings (RoPE), support for activation sharding, and 8-bit quantization, with a maximum sequence length of 8,192 tokens. It also features key-value memory for efficient processing of long sequences and uses sharding to distribute computation across multiple devices, ensuring high performance and scalability for large AI models.
xAI has released Grok-1 under the Apache 2.0 license, making its model weights and network architecture available to the public, even for commercial purposes.
Accuracy leaderboard of the Grok-1 release
The performance of Grok-1 was evaluated across several key benchmarks, each designed to test different aspects of language model capabilities:
- GSM8k─This benchmark assesses the model's ability to solve complex, multistep mathematical problems, using the chain-of-thought prompt. (GSM8k: Middle school math word problems. (Cobbe et al. 2021))
- MMLU─MMLU tests the model's knowledge across a wide range of academic and professional domains, which provides 5-shot in-context examples. (MMLU: Multidisciplinary multiple-choice questions, (Hendrycks et al. 2021))
- HumanEval─This benchmark evaluates the model's proficiency in generating functional code zero-shot evaluated for pass@1. (HumanEval─Python code completion task, (Chen et al. 2021))
- MATH: MATH challenges the model with advanced mathematical reasoning tasks, prompted with a fixed 4-shot prompt. (MATH: Middle school and high school mathematics problems written in LaTeX, (Hendrycks et al. 2021))
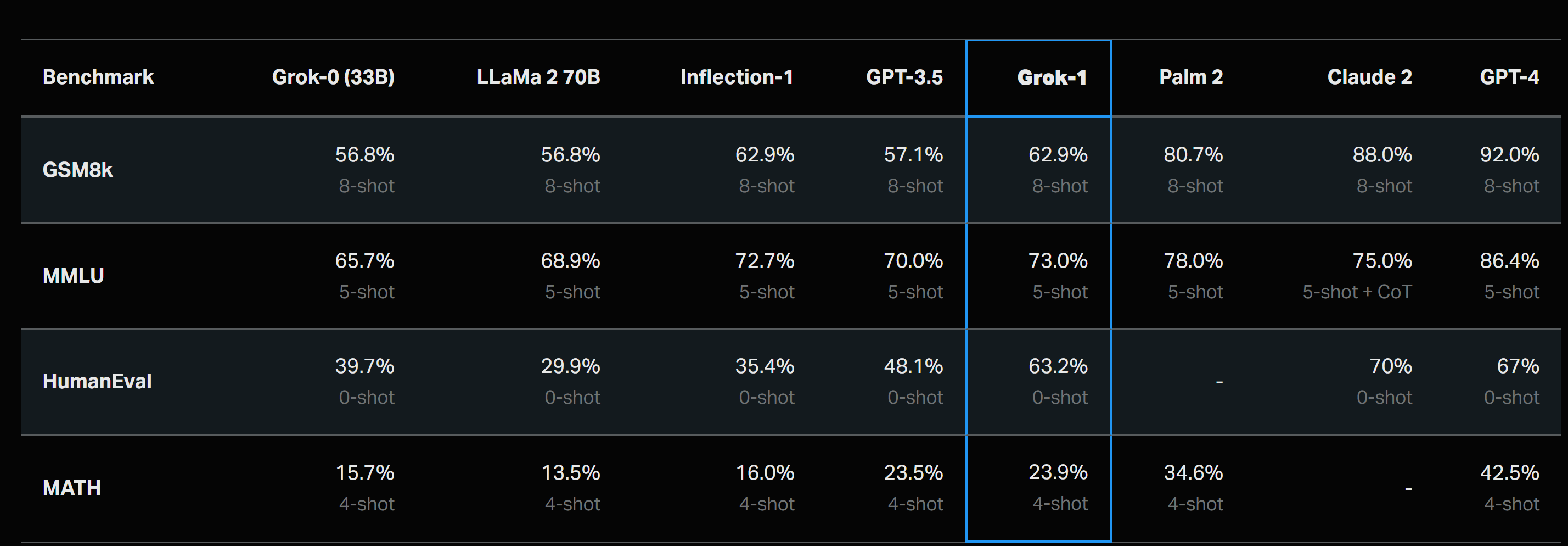
Figure 4: Grok -1 accuracy scores[1]
PowerEdge XE9680 hardware requirements
Due to its vast parameter count, Grok-1 requires significant computational power. The PowerEdge XE9680 server with eight AMD MI300x GPUs serves as an excellent choice to run this workload. The server requires multiple GPUs to run efficiently.
The version of Grok-1 released to the public is the base model from its pretraining phase, which is not yet customized for specific applications such as conversational AI. The release includes an inference setup script, which uses the JAX deep learning Framework.
Running the workload on the PowerEdge XE9680 server with AMD MI300x GPUs
We ran the workload with the following system configuration:
Component | PowerEdge XE9680 |
Processor Configuration | 2 Sockets of 4th Gen Intel Xeon Scalable Processor processors |
Memory | 32 x 64 GB @ 4800 MT/s DDR5 |
Storage - OS Boot | BOSS-N1 (960 GB NVMe) |
Storage – Internal Drives | Up to 8 x U.2 NVMe |
Network Cards | Add-in-Card for Backend Traffic: 8 x Broadcom 57608 400 GbE Adapter, PCIe (Thor 2) Add-in-Card for Frontend Traffic: 2 x Broadcom 57608 400 GbE Adapter, PCIe (Thor 2) Integrated LOM: 2 x 1 GbE Base-T Broadcom 5720 Optional OCP 3.0 Card: Broadcom 57504 Quad Port 10/25 GbE SFP28 (not installed) |
PCIe Riser | Riser Config 2 MI300X - 10 x PCIe Gen5 FH slots |
GPU | AMD Instinct MI300X 8-GPU OAM 192 GB 750 W |
Power Supply | 6 x 2800 W AC Titanium |
Backend switch Fabric | Dell PowerSwitch Z9664 (400 GbE) (Broadcom Tomahawk 4) |
Management Fabric | Dell PowerSwitch S3248 (1 GbE) |
Embedded Systems Management | iDRAC9 Datacenter 16G |
ROCM Version | 6.1.1 |
To run the workload using Grok-1, use the following commands:
# pull and run the rocm/jax container
docker run --rm -it --network=host --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size 16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined rocm/jax:latest
# once its done, it’ll take you into the container
git clone https://github.com/xai-org/grok-1.git && cd grok-1
pip install huggingface_hub[hf_transfer]
# this downloads the grok-1 checkpoints – takes a while to download as this is a large download
huggingface-cli download xai-org/grok-1 --repo-type model --include ckpt-0/* --local-dir checkpoints --local-dir-use-symlinks False
Modify your requirements.txt file to remove versions, as shown in the following figure:

Figure 4: Updated requirements.txt file to address versions to match the latest rocm/jax container
# run the benchmark after installing the requirements.txt
python run.py
The following figure shows the output of the Grok model that picked up the ROCM backend:
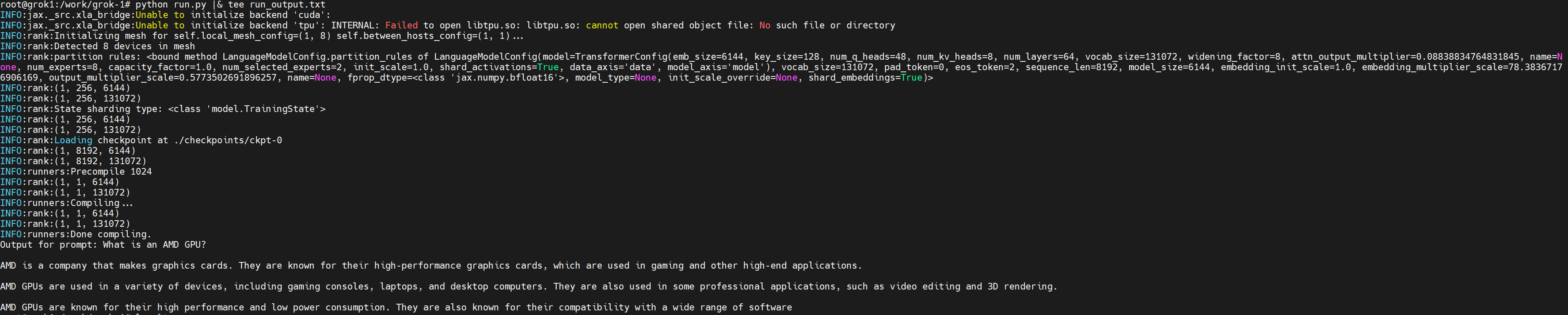
Figure 5: Output of the Grok-1 run on the PowerEdge XE9680 server
The following figure shows the version of Python packages inside the container:
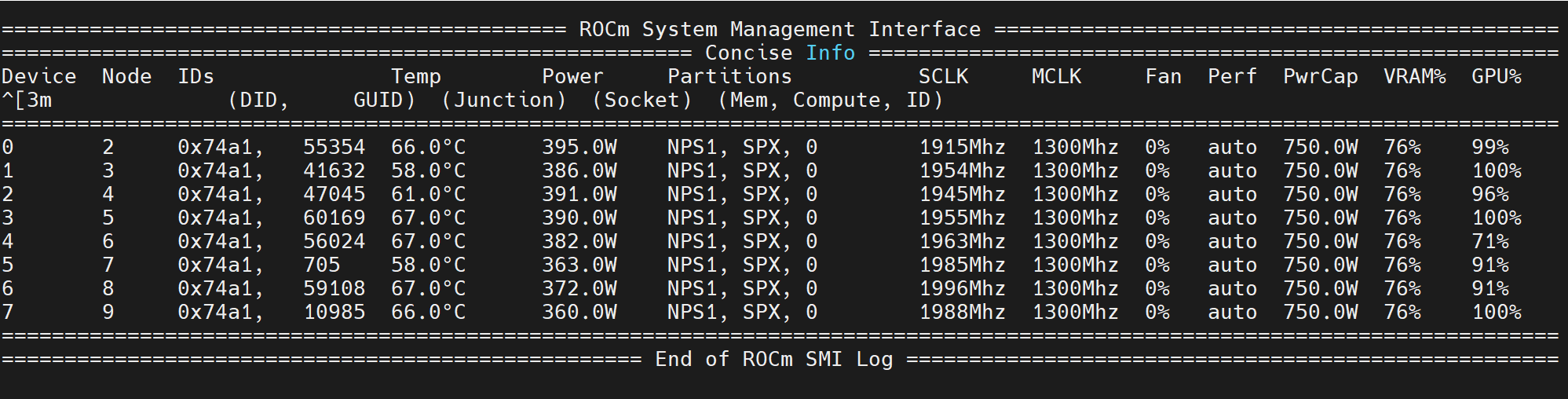
The following figure shows the output of the rocm-smi while running the inference:
Conclusion
We were able to successfully run Grok-1. Running Grok-1 on a Dell PowerEdge XE9680 server equipped with eight AMD MI300x GPUs uses cutting-edge GPU technology, high-bandwidth interconnects, and robust hardware integration. This setup is optimized to meet the computational and data-intensive requirements of large AI models, offering substantial performance improvements, scalability, and flexibility for AI and machine learning workloads. Upstreaming a new GPU such as the AMD MI300x GPU to the JAX framework is a complex and resource-intensive task. The task adapts the XLA compiler, dedicating significant engineering resources, using community contributions, and ensuring compatibility with existing tools and libraries. These challenges identify some of the difficulty of integrating new hardware into an established and optimized software ecosystem like JAX for modern AI workloads such as LLMs. Despite these challenges, AMD has been successful in implementing this integration.
The partnership between Dell Technologies and AMD promises even more advancements in the future. By combining AMD's innovative GPU technology with Dell's robust server infrastructure, this collaboration is set to deliver enhanced performance, scalability, and flexibility for AI and machine learning workloads with customers, brings silicon diversity in data center. Users can expect continued improvements and cutting-edge solutions driving the next generation of AI capabilities.
For more information, see Generative AI in the Enterprise with AMD Accelerators.