



MLPerf™ Inference v2.0 Edge Workloads Powered by Dell PowerEdge Servers
Fri, 06 May 2022 19:54:11 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. This blog examines the results of two specialty edge servers: the Dell PowerEdge XE2420 server with the NVIDIA T4 Tensor Core GPU and the Dell PowerEdge XR12 server with the NVIDIA A2 Tensor Core GPU.
Introduction
It is 6:00 am on a Saturday morning. You drag yourself out of bed, splash water on your face, brush your hair, and head to your dimly lit kitchen for a bite to eat before your morning run. Today, you have decided to explore a new part of the neighborhood because your dog’s nose needs new bushes to sniff. As you wait for your bagel to toast, you ask your voice assistant “what’s the weather like?” Within a couple of seconds, you know that you need to grab an extra layer because there is a slight chance of rain. Edge computing has saved your morning run.
Although this use case is covered in the MLPerf Mobile benchmarks, the data discussed in this blog is from the MLPerf Inference benchmark that has been run on Dell servers.
Edge computing is computing that takes place at the “edge of networks.” Edge of networks refers to where devices such as phones, tablets, laptops, smart speakers, and even industrial robots can access the rest of the network. In this case, smart speakers can perform speech-to-text recognition to offload processing that ordinarily must be accomplished in the cloud. This offloading not only improves response time but also decreases the amount of sensitive data that is sent and stored in the cloud. The scope for edge computing expands far beyond voice assistants with use cases including autonomous vehicles, 5G mobile computing, smart cities, security, and more.
The Dell PowerEdge XE2420 and PowerEdge XR 12 servers are designed for edge computing workloads. The design criteria is based on real life scenarios such as extreme heat, dust, and vibration from factory floors, for example. However, despite these servers not being physically located in a data center, server reliability and performance are not compromised.
PowerEdge XE2420 server
The PowerEdge XE2420 server is a specialty edge server that delivers high performance in harsh environments. This server is designed for demanding edge applications such as streaming analytics, manufacturing logistics, 5G cell processing, and other AI applications. It is a short-depth, dense, dual-socket, 2U server that can handle great environmental stress on its electrical and physical components. Also, this server is ideal for low-latency and large-storage edge applications because it supports 16x DDR4 RDIMM/LR-DIMM (12 DIMMs are balanced) up to 2993 MT/s. Importantly, this server can support the following GPU/Flash PCI card configurations:
- Up to 2 x PCIe x16, up to 300 W passive FHFL cards (for example, NVIDIA V100/s or NVIDIA RTX6000)
- Up to 4 x PCIe x8; 75 W passive (for example, NVIDIA T4 GPU)
- Up to 2 x FE1 storage expansion cards (up to 20 x M.2 drives on each)
The following figures show the PowerEdge XE2420 server (source):

Figure 1: Front view of the PowerEdge XE2420 server

Figure 2: Rear view of the PowerEdge XE2420 server
PowerEdge XR12 server
The PowerEdge XR12 server is part of a line of rugged servers that deliver high performance and reliability in extreme conditions. This server is a marine-compliant, single-socket 2U server that offers boosted services for the edge. It includes one CPU that has up to 36 x86 cores, support for accelerators, DDR4, PCIe 4.0, persistent memory and up to six drives. Also, the PowerEdge XR12 server offers 3rd Generation Intel Xeon Scalable Processors.
The following figures show the PowerEdge XR12 server (source):

Figure 3: Front view of the PowerEdge XR12 server

Figure 4: Rear view of the PowerEdge XR12 server
Performance discussion
The following figure shows the comparison of the ResNet 50 Offline performance of various server and GPU configurations, including:
- PowerEdge XE8545 server with the 80 GB A100 Multi-Instance GPU (MIG) with seven instances of the one compute instance of the 10gb memory profile
- PowerEdge XR12 server with the A2 GPU
- PowerEdge XE2420 server with the T4 and A30 GPU
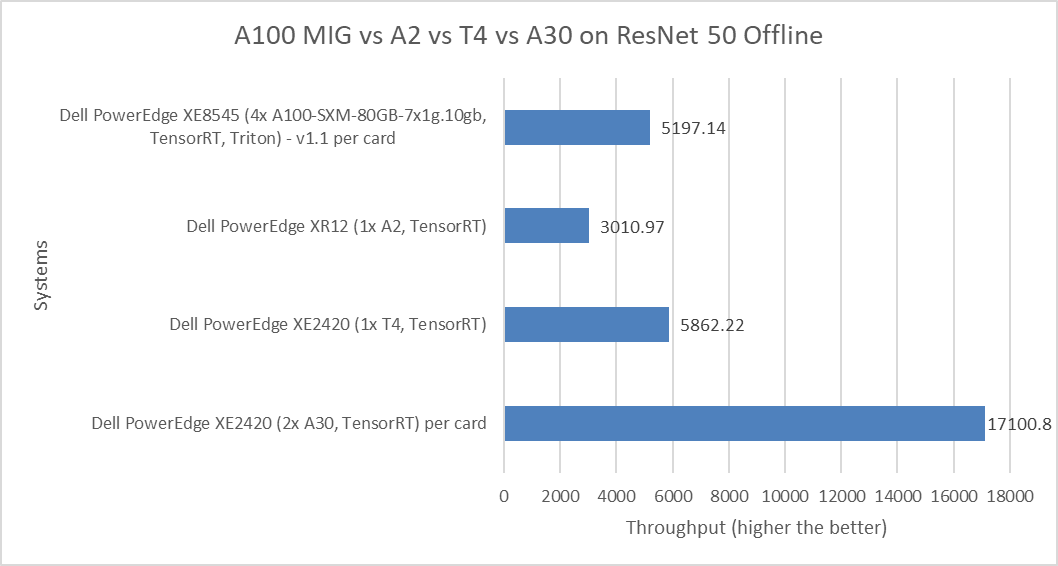
Figure 5: MLPerf Inference ResNet 50 Offline performance
ResNet 50 falls under the computer vision category of applications because it includes image classification, object detection, and object classification detection workloads.
The MIG numbers are per card and have been divided by 28 because of the four physical GPU cards in the systems multiplied by second instances of the MIG profile. The non-MIG numbers are also per card.
For the ResNet 50 benchmark, the PowerEdge XE2420 server with the T4 GPU showed more than double the performance of the PowerEdge XR12 server with the A2 GPU. The PowerEdge XE8545 server with the A100 MIG showed competitive performance when compared to the PowerEdge XE2420 server with the T4 GPU. The performance delta of 12.8 percent favors the PowerEdge XE2420 system. However, the PowerEdge XE2420 server with A30 GPU card takes the top spot in this comparison as it shows almost triple the performance over the PowerEdge XE2420 server with the T4 GPU.
The following figure shows a comparison of the SSD-ResNet 34 Offline performance of the PowerEdge XE8545 server with the A100 MIG and the PowerEdge XE2420 server with the A30 GPU.
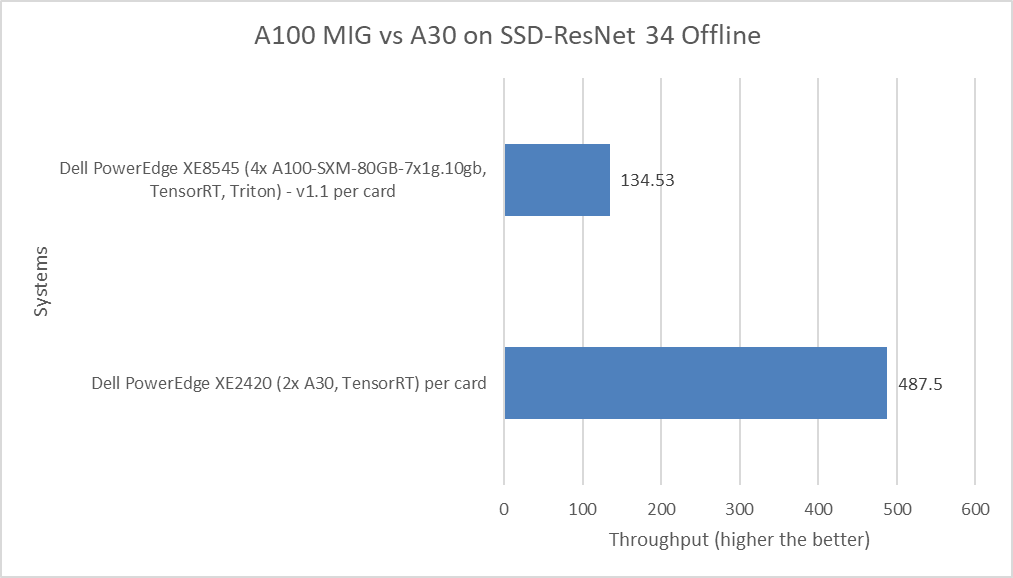
Figure 6: MLPerf Inference SSD-ResNet 34 Offline performance
The SSD-ResNet 34 model falls under the computer vision category because it performs object detection. The PowerEdge XE2420 server with the A30 GPU card performed more than three times better than the PowerEdge XE8545 server with the A100 MIG.
The following figure shows a comparison of the Recurrent Neural Network Transducers (RNNT) Offline performance of the PowerEdge XR12 server with the A2 GPU and the PowerEdge XE2420 server with the T4 GPU:
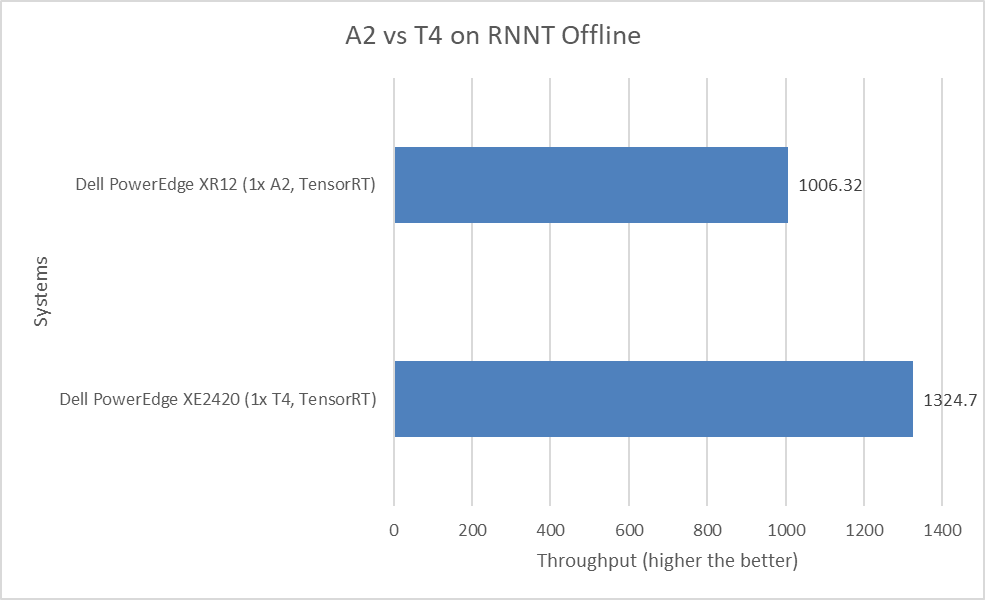
Figure 7: MLPerf Inference RNNT Offline performance
The RNNT model falls under the speech recognition category, which can be used for applications such as automatic closed captioning in YouTube videos and voice commands on smartphones. However, for speech recognition workloads, the PowerEdge XE2420 server with the T4 GPU and the PowerEdge XR12 server with the A2 GPU are closer in terms of performance. There is only a 32 percent performance delta.
The following figure shows a comparison of the BERT Offline performance of default and high accuracy runs of the PowerEdge XR12 server with the A2 GPU and the PowerEdge XE2420 server with the A30 GPU:
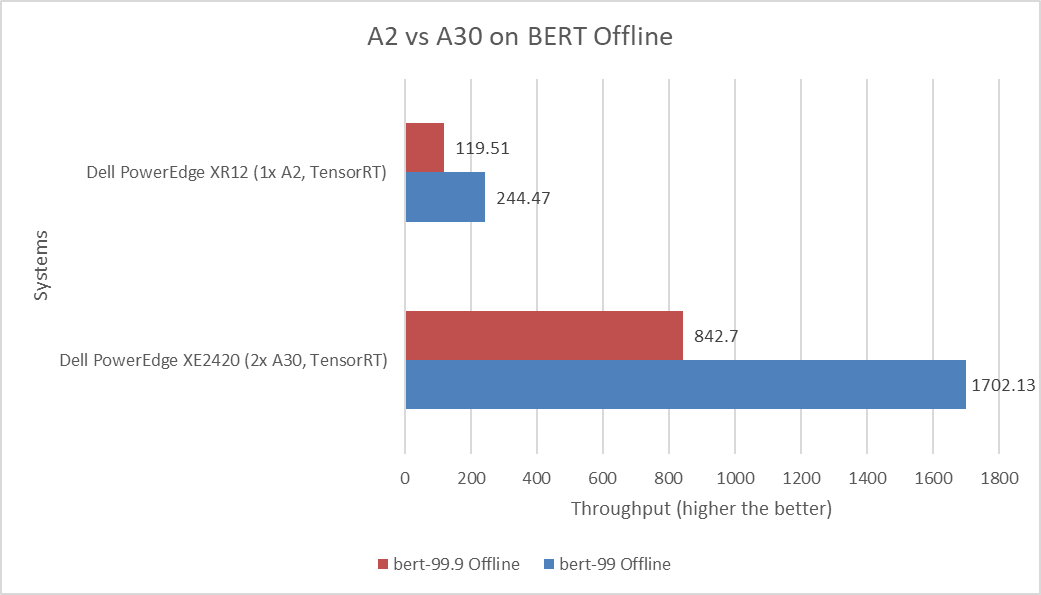
Figure 8: MLPerf Inference BERT Offline performance
BERT is a state-of-the-art, language-representational model for Natural Language Processing applications such as sentiment analysis. Although the PowerEdge XE2420 server with the A30 GPU shows significant performance gains, the PowerEdge XR12 server with the A2 GPU exceeds when considering achieved performance based on the money spent.
The following figure shows a comparison of the Deep Learning Recommendation Model (DLRM) Offline performance for the PowerEdge XE2420 server with the T4 GPU and the PowerEdge XR12 server with the A2 GPU:
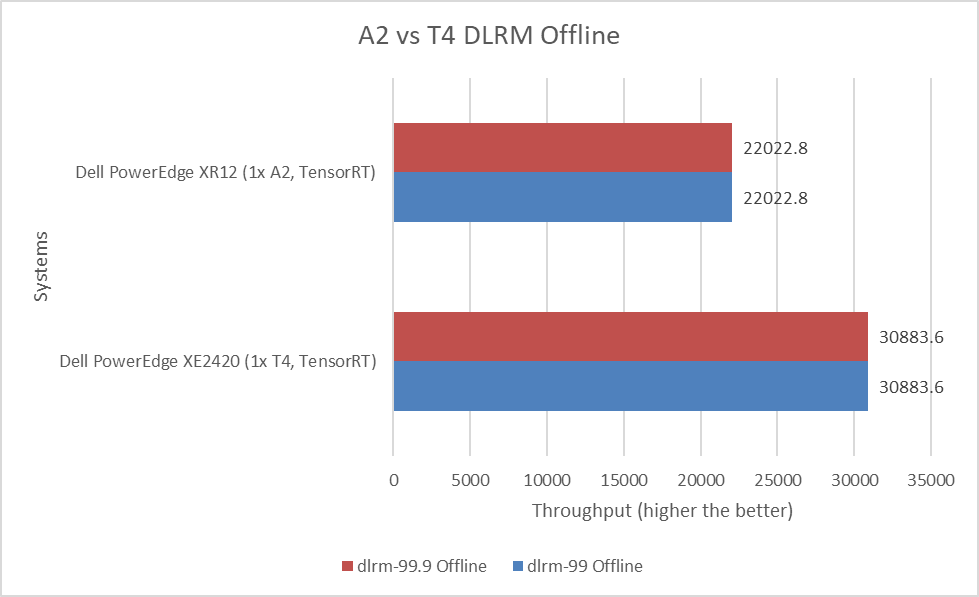
Figure 9: MLPerf Inference DLRM Offline performance
DLRM uses collaborative filtering and predicative analysis-based approaches to make recommendations, based on the dataset provided. Recommender systems are extremely important in search, online shopping, and online social networks. The performance of the PowerEdge XE2420 T4 in the offline mode was 40 percent better than the PowerEdge XR12 server with the A2 GPU.
Despite the higher performance from the PowerEdge XE2420 server with the T4 GPU, the PowerEdge XR12 server with the A2 GPU is an excellent option for edge-related workloads. The A2 GPU is designed for high performance at the edge and consumes less power than the T4 GPU for similar workloads. Also, the A2 GPU is the more cost-effective option.
Power Discussion
It is important to budget power consumption for the critical load in a data center. The critical load includes components such as servers, routers, storage devices, and security devices. For the MLPerf Inference v2.0 submission, Dell Technologies submitted power numbers for the PowerEdge XR12 server with the A2 GPU. Figures 8 through 11 showcase the performance and power results achieved on the PowerEdge XR12 system. The blue bars are the performance results, and the green bars are the system power results. For all power submissions with the A2 GPU, Dell Technologies took the Number One claim for performance per watt for the ResNet 50, RNNT, BERT, and DLRM benchmarks.
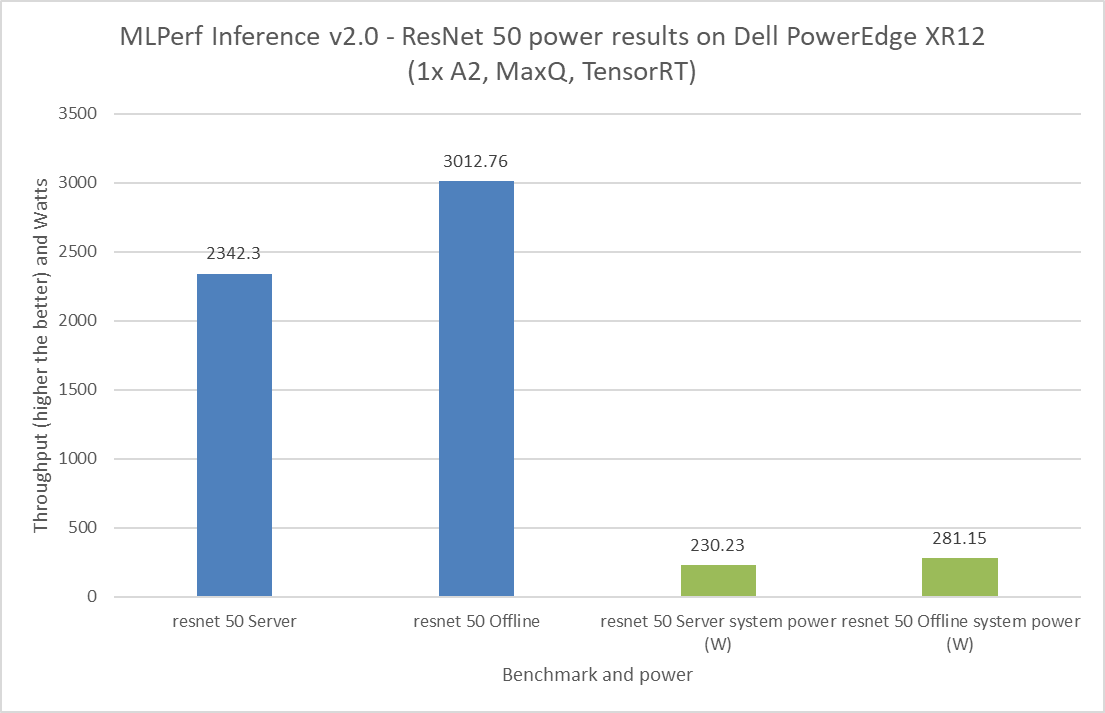
Figure 10: MLPerf Inference v2.0 ResNet 50 power results on the Dell PowerEdge XR12 server
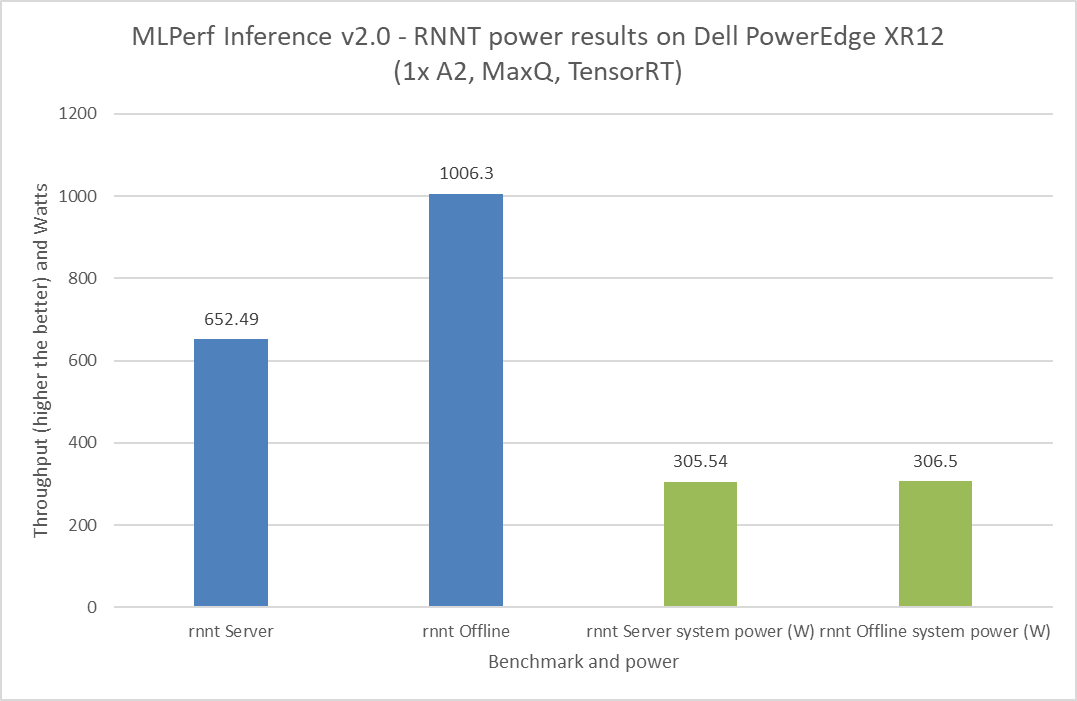
Figure 11: MLPerf Inference v2.0 RNNT power results on the Dell PowerEdge XR12 server
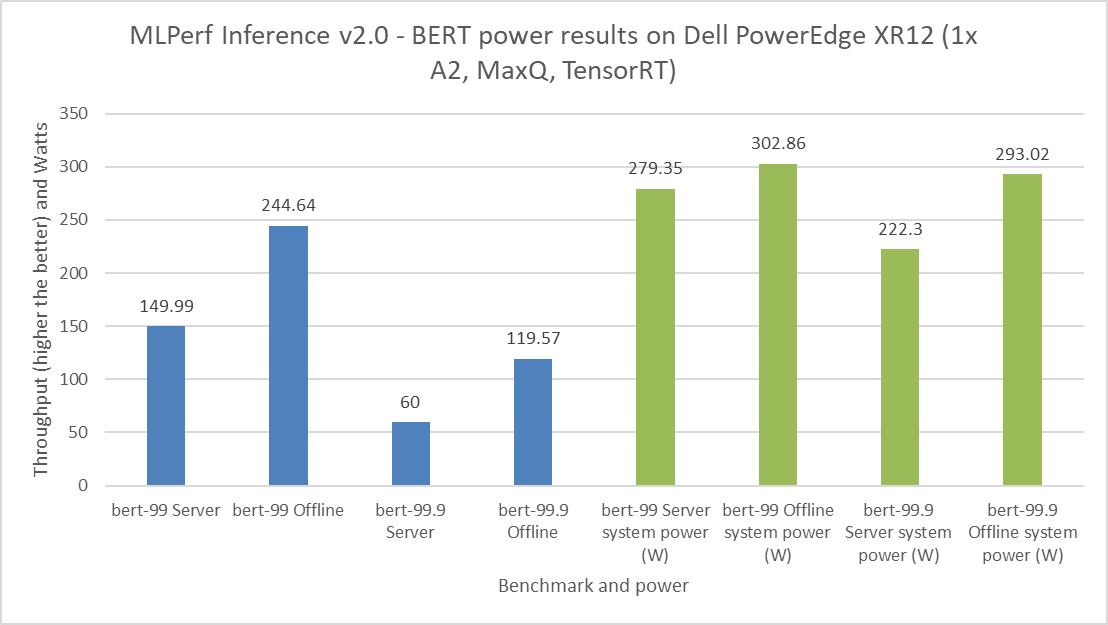
Figure 12: MLPerf Inference v2.0 BERT power results on the Dell PowerEdge XR12 server
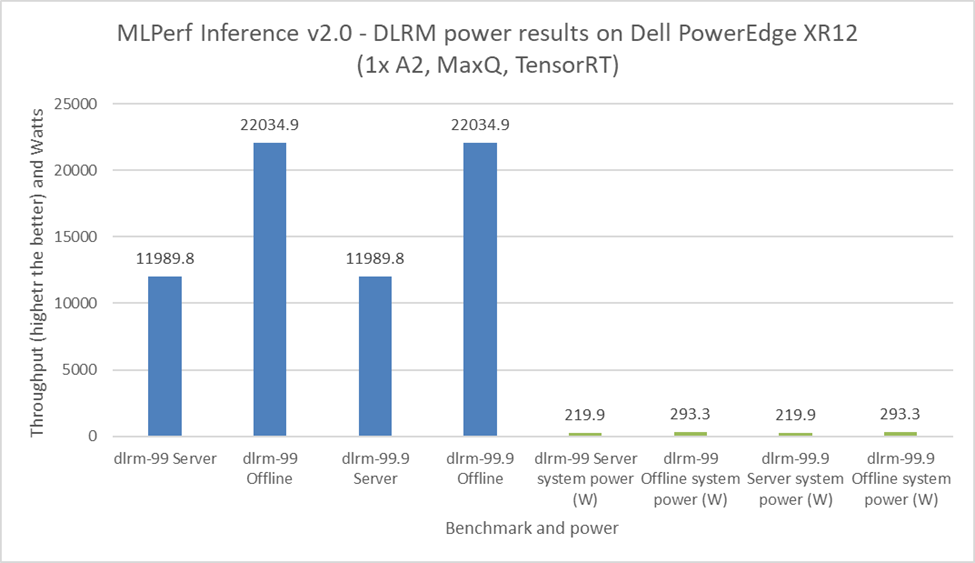 Figure 13: MLPerf Inference v2.0 DLRM power results on the Dell PowerEdge XR12 server
Figure 13: MLPerf Inference v2.0 DLRM power results on the Dell PowerEdge XR12 server
Note: During our submission to MLPerf Inference v2.0 including power numbers, the PowerEdge XR12 server was not tuned for optimal performance per watt score. These results reflect the performance-optimized power consumption numbers of the server.
Conclusion
This blog takes a closer look at Dell Technologies’ MLPerf Inference v2.0 edge-related submissions. Readers can compare performance results between the Dell PowerEdge XE2420 server with the T4 GPU and the Dell PowerEdge XR12 server with the A2 GPU with other systems with different accelerators. This comparison helps readers make informed decisions about ML workloads on the edge. Performance, power consumption, and cost are the important factors to consider when planning any ML workload. Both the PowerEdge XR12 and XE2420 servers are excellent choices for Deep Learning workloads on the edge.
Appendix
SUT configuration
The following table describes the System Under Test (SUT) configurations from MLPerf Inference v2.0 submissions:
Table 1: MLPerf Inference v2.0 system configuration of the PowerEdge XE2420 and XR12 servers
Platform | PowerEdge XE2420 1x T4, TensorRT | PowerEdge XR12 1x A2, TensorRT | PowerEdge XR12 1x A2, MaxQ, TensorRT | PowerEdge XE2420 2x A30, TensorRT |
MLPerf system ID | XE2420_T4x1_edge_TRT | XR12_edge_A2x1_TRT | XR12_A2x1_TRT_MaxQ | XE2420_A30x2_TRT |
Operating system | CentOS 8.2.2004 | Ubuntu 20.04.4 | ||
CPU | Intel Xeon Gold 6238 CPU @ 2.10 GHz | Intel Xeon Gold 6312U CPU @ 2.40 GHz | Intel Xeon Gold 6252N CPU @ 2.30 GHz | |
Memory | 256 GB | 1 TB | ||
GPU | NVIDIA T4 | NVIDIA A2 | NVIDIA A30 | |
GPU form factor | PCIe | |||
GPU count | 1 | 2 | ||
Software stack | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.47.03 DALI 0.31.0 | |||
Table 2: MLPerf Inference v1.1 system configuration of the PowerEdge XE8545 server
Platform | PowerEdge XE8545 4x A100-SXM-80GB-7x1g.10gb, TensorRT, Triton |
MLPerf system ID | XE8545_A100-SXM-80GB-MIG_28x1g.10gb_TRT_Triton |
Operating system | Ubuntu 20.04.2 |
CPU | AMD EPYC 7763 |
Memory | 1 TB |
GPU | NVIDIA A100-SXM-80GB (7x1g.10gb MIG) |
GPU form factor | SXM |
GPU count | 4 |
Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.57.02 DALI 0.31.0 |