




Fine-tuning Llama 3 Using torchtune: A New PyTorch-native Library on the Dell PowerEdge XE9680 Server

Fine-tuning is a machine learning process in which a pretrained model is further adjusted for a specific task or dataset. Instead of training a model from scratch, fine-tuning starts with an existing foundational model (usually pretrained on a large dataset) and adapts it to perform well on a narrower, domain-specific task. By fine-tuning, we use the knowledge captured by the pretrained model and specialize it for our specific use case. In the context of language models like large language models (LLMs), fine-tuning customizes the model’s weights on a smaller, task-specific dataset to improve its performance for specific tasks such as text generation, sentiment analysis, or translation. There are several options available for independently fine-tuning a model. These steps typically include starting with the data, preprocessing the dataset, choosing a foundational model, using transformers to fine-tune the model on the preprocessed dataset, and saving the tuned model. There are several frameworks available that enable developers to expedite the fine-tuning process.
Dell Technologies recently released a Dell Validated Design for Generative AI with AMD accelerators. As part of this initiative, we published the Generative AI in the Enterprise with AMD Accelerators reference architecture that outlines the steps for fine-tuning a Llama 3 model using Dell PowerEdge XE9680 servers with AMD Instinct MI300X GPUs and AMD ROCm software.
In a series of blogs, we will present fine-tuning techniques across various frameworks.
Introduction
The available libraries and frameworks for fine-tuning LLMs include:
- PyTorch torchetune─torchetune is an efficient and flexible library specifically designed for fine-tuning neural networks. It provides a high-level interface for customizing pretrained models, making it an excellent choice for LLM fine-tuning.
- Mosaic ML LLM Foundry─Mosaic ML’s LLM Foundry offers a comprehensive suite of tools for fine-tuning LLMs. With features like data augmentation, hyperparameter tuning, and model evaluation, it simplifies the fine-tuning process.
- Hugging Face Transfer Learning Toolkit (TRL)─Hugging Face’s TRL is a versatile toolkit that supports fine-tuning of various pretrained models, including LLMs. Its user-friendly APIs and extensive documentation make it accessible to both researchers and practitioners.
This blog focuses on fine-tuning the Llama model using the torchtune framework. Whether you are a seasoned developer or starting out, our blog guides you through the process, ensuring successful fine-tuning with torchetune.
PyTorch torchtune
For fine-tuning language models, torchtune stands out as a versatile and powerful tool. Unlike other frameworks, torchtune seamlessly integrates with your existing PyTorch installation. The following details set it apart from other tools:
- Composable and modular building blocks─torchtune offers native PyTorch implementations of popular LLMs. These implementations are designed with modularity in mind, allowing you to mix and match components effortlessly.
- Hackable training recipes─Forget about complex trainers and frameworks. With torchtune, you get straightforward, easy-to-use training recipes for fine-tuning techniques like Local Rank Adaptation (LoRA) and Quantized Low-Rank Adaptation (QLoRA). It is all about empowering you to experiment and iterate without unnecessary barriers.
- YAML configurations for flexibility─By configuring training, evaluation is simple with YAML files. Customize your settings, adapt to different tasks, and maintain clarity throughout your experiments with various hyperparameters.
- Seamless integration with Hugging Face─torchtune can integrate Hugging Face modules to load models and datasets, as well as preprocessing the datasets from Hugging Face.
- Dataset support─torchtune includes integrated support for various popular datasets. Whether you are working with Alpaca, CNN daily mail, Chat, Grammar, wiki text, SAMSum, Stack Exchange paired data, or text completion tasks, torchtune has you covered. This support helps data scientists to experiment with the torchetune framework and understand its capabilities.
- Fine-tuning techniques─Two key techniques shine in torchtune:
- Local Rank Adaptation (LoRA)─Boost your fine-tuning performance with this method.
- Full tuning─Dive deep into fine-tuning with the full_finetune_distributed module.
Both techniques can be configured for single devices, single-node multidevice setups, or multi-node configurations. In this blog, we explore an example using LoRA on a single node with multiple devices and multiple nodes.
High-level workflow
The following flowchart illustrates a machine learning workflow using PyTorch:
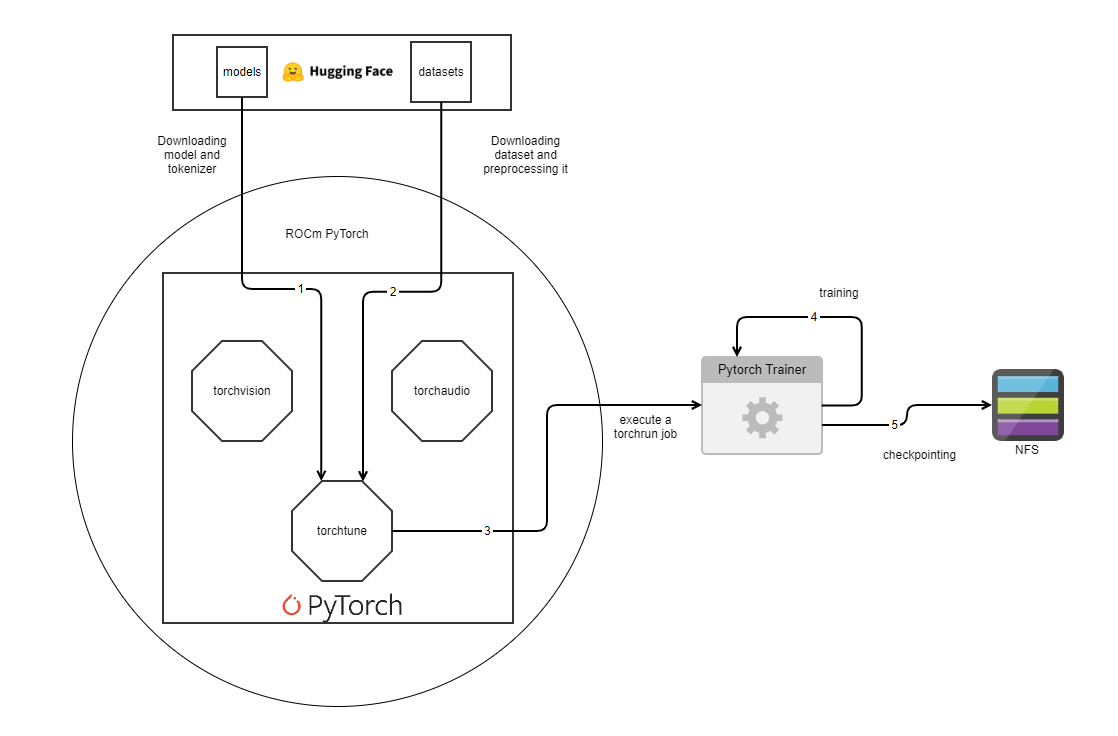
Figure 1: High-level workflow using PyTorch
The workflow begins by downloading models and tokenizers, as well as datasets from Hugging Face. PyTorch is the heart of the process that incorporates elements such as ROCm PyTorch, torchaudio, and torchtune. A torchrun script initiates the training phase, which PyTorch Trainer oversees. The training job persists based on hyperparameters such as max_steps, epochs, and so on resulting in actions such as checkpointing and employing NFS for the storage and retrieval of these checkpoints. This integrated system underscores the elaborate procedures entailed in running a machine learning project with PyTorch.
Preparing the environment
Now that you are familiar with torchtune and its high-level workflow, let’s look at how we fine-tuned a Llama 3 model using torchtune using Dell PowerEdge XE9680 systems powered by AMD MI300X GPUs.
The environment requires the following:
- Dell PowerEdge XE9680 server with AMD Instinct MI300X GPUs─Choosing the right accelerator and network configuration is essential for successful model training. In this example, we use a Dell PowerEdge XE9680 server with AMD MI300X Accelerators. For more information about, see the hardware specifications in Generative AI in the Enterprise with AMD Accelerators.
- Docker Container setup─ Ensure that you have installed and configured Docker. Containers provide a consistent environment for your AI workloads.
- GPU drivers─ Depending on the GPU that you use, install the appropriate GPU drivers. For this example, we installed the amd-rocm drivers.
Use either a bare metal setup or any containerized setup. GPU drivers are the foundational part of the fine-tuning process. For the systems that are powered with AMD GPUs, use the following container that has PyTorch and ROCm preinstalled:
rocm/pytorchrocm6.1_ubuntu22.04_py3.10_pytorch_2.1.2 - PyTorch─Install PyTorch, considering whether to use CUDA or ROCm. PyTorch is the backbone of your deep learning framework.
- Custom container─For our validation in the lab, we built a custom container that addresses the following steps referenced in Generative AI in the Enterprise with AMD Accelerators. The open-source containers, such as rocm/pytorch, include the necessary libraries for single-node setups. Often, for a multinode setup, an additional driver installation is required for network adapters along with some sanity tests for the multinode setup.
The custom base container used in our Dell validated design includes the following steps as its foundation:
- Use Ubuntu 22.04 as a base image.
- Install predependent developer packages for the GPU model.
- Configure and install network drivers; this step is necessary for multinode runs.
- Install the appropriate GPU drivers, depending on if you choose AMD or NVIDIA GPUs.
- Install Python and PyTorch.
- Use RCCL or NCCL tests, depending on the GPUs.
- Install torchtune from pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning (github.com).
- Build and create the following image:
docker build -f <Dockerfile> -t <imagetag> .where ‘.’ refers to the current folder in which the drivers are stored and referred to in the dockerfile.
- torchtune─torchtune is your go-to tool for fine-tuning and experimenting with LLMs. Download the torchtune library from GitHub.
Notes:
- This repo does not support the Databricks Dolly 15k dataset.
- The default source for torchtune supports only a limited set of the dataset. Currently is supports Samsun, Alpaca, WikiText, Grammar, and so on. We have created a fork on top of pytorch/torchtune and created our own repo that supports the databricks-dolly-15k dataset. To accommodate a custom dataset, follow these high-level steps:
- List the name of the new dataset in the __init__.py file.
- Define a function for the new dataset under the datasets folder that returns an object of Instruct Dataset.
- Update the _instruct.py file with a preprocessing function that prepares the sample. The following is a sample snippet that you can find in the codebase referred to below:
if databricks_dolly: key_output = ( self._column_map["response"] if self._column_map and "response" in self.column_map else "response" )
- For codebase samples, see:
- premmotgi/torchtune: A Native-PyTorch Library for LLM Fine-tuning (github.com)
- branch: feature/torchtune_databricks_support
- For the AMD GPU, bf16 is only supported on of PyTorch 6.1 or later. For other GPUs, both bf16 and fp32 are supported.
Running fine-tuning
To run fine-tuning, follow these steps:
- Run the container of choice or custom-created container based on the previous instructions to get started with the process of fine-tuning. The container environment is the foundational aspect as it contains the necessary libraries to run the model customization for this use case. In our lab, we built a container by following the steps in Preparing the environment and tagged it as imagehub.ai.lab:5000/waco0.1. You can either use the PyTorch container and install the required libraries or build you own custom container. The fine-tuning can be of many types: single device, multidevice (single node), multi-node (more than one node). You can choose the type of the fine-tuning depending on the size of the model, the type of the use-case, and the availability of resources. Run single-node fine-tuning on one node. For multinode fine-tuning, use the docker run command on all the wanted nodes. In this blog, we focus on both types as its easy to scale the fine-tuning job from a single GPU to distributed training across multiple nodes, meaning, only the pytorch-torchrun parameters will change along with training configuration.
- Run the following command to run the container on a single node:
docker run -it --shm-size 250G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ipc host --network host --device=/dev/kfd --device=/dev/dri --group-add video -v /dev:/dev -v /sys:/sys --privileged -v /<Workspace_folder>/:/<Workspace_folder> -v /<NFS_PATH>:/<NFS_PATH> -v /<NFS_FOLDER>/tvar/:/var -v /<NFS_FOLDER>/ttmp/:/tmp imagehub.ai.lab:5000/waco0.1:052224Note: We used our custom-built image in this example. If you built your own container, refer to it. - In the container, create a symbolic link to the model file. For smaller models such as llama3-8b, torchtune can swiftly download and customize the model. However, for larger models, downloading all the shards can be time-consuming due to the greater model size. In such instances, it is more efficient to create a symbolic link to the model folders, allowing torchtune to reference the links directly (for example, use the ln -s command).
- Create a checkpoint folder in NFS to store the checkpoints and output model.
- Update the recipe configuration file for 70 B to point to created symbolic link to the model as well as the checkpoint storage directory:
File Path: recipes/configs/llama3/70B_lora.yaml File: # Model Arguments model: _component_: torchtune.models.llama3.lora_llama3_70b lora_attn_modules: ['q_proj', 'k_proj', 'v_proj'] apply_lora_to_mlp: False apply_lora_to_output: False lora_rank: 16 lora_alpha: 32 tokenizer: _component_: torchtune.models.llama3.llama3_tokenizer path: /work/torchtune/Meta-Llama-3-70B/original/tokenizer.model #Path within container checkpointer: _component_: torchtune.utils.FullModelHFCheckpointer checkpoint_dir: /work/torchtune/Meta-Llama-3-70B checkpoint_files: [ model-00001-of-00030.safetensors, model-00002-of-00030.safetensors, model-00003-of-00030.safetensors, model-00004-of-00030.safetensors, model-00005-of-00030.safetensors, model-00006-of-00030.safetensors, model-00007-of-00030.safetensors, model-00008-of-00030.safetensors, model-00009-of-00030.safetensors, model-00010-of-00030.safetensors, model-00011-of-00030.safetensors, model-00012-of-00030.safetensors, model-00013-of-00030.safetensors, model-00014-of-00030.safetensors, model-00015-of-00030.safetensors, model-00016-of-00030.safetensors, model-00017-of-00030.safetensors, model-00018-of-00030.safetensors, model-00019-of-00030.safetensors, model-00020-of-00030.safetensors, model-00021-of-00030.safetensors, model-00022-of-00030.safetensors, model-00023-of-00030.safetensors, model-00024-of-00030.safetensors, model-00025-of-00030.safetensors, model-00026-of-00030.safetensors, model-00027-of-00030.safetensors, model-00028-of-00030.safetensors, model-00029-of-00030.safetensors, model-00030-of-00030.safetensors, ] recipe_checkpoint: null output_dir: /tmp/Meta-Llama-3-70B-Instruct model_type: LLAMA3 resume_from_checkpoint: False # Dataset and Sampler dataset: _component_: torchtune.datasets.databricks_dolly_15k train_on_input: True seed: null shuffle: True batch_size: 2 # Optimizer and Scheduler optimizer: _component_: torch.optim.AdamW weight_decay: 0.01 lr: 3e-4 lr_scheduler: _component_: torchtune.modules.get_cosine_schedule_with_warmup num_warmup_steps: 100 loss: _component_: torch.nn.CrossEntropyLoss # Training # set epochs to a higher number to run towards convergence. epochs: 1 max_steps_per_epoch: null #Gradient accumulation is a technique used during fine-tuning to balance memory efficiency and training effectiveness. gradient_accumulation_steps: 1 # Logging output_dir: /tmp/Meta-Llama-3-70B-Instruct metric_logger: _component_: torchtune.utils.metric_logging.TensorBoardLogger log_dir: ${output_dir} organize_logs: true log_every_n_steps: 1 log_peak_memory_stats: False # Environment device: cuda dtype: bf16 enable_activation_checkpointing: True After updating the file, next step is to run the tuning: Single node: tune run --nnodes=1 --nproc_per_node=8 --rdzv_id=456 --rdzv_backend=c10d --node-rank=0 --rdzv_endpoint=<hostname/container_name>:29603 lora_finetune_distributed --config recipes/configs/llama3/70B_lora.yaml output_dir=<created_checkpoint_folder_path>/lora-70b-bf16-sn checkpointer.output_dir=<created_checkpoint_folder_path>/lora-70b-bf16-sn dtype=bf16" For multinode, 2 nodes: Node1: tune run --nnodes=2 --nproc_per_node=8 --rdzv_id=456 --rdzv_backend=c10d --node-rank=0 --rdzv_endpoint=<master_node>:29603 lora_finetune_distributed --config recipes/configs/llama3/70B_lora.yaml output_dir=<created_checkpoint_folder_path>/lora-70b-bf16-sn checkpointer.output_dir=<created_checkpoint_folder_path>/lora-70b-bf16-sn dtype=bf16" Node2: only node-rank will change tune run --nnodes=2 --nproc_per_node=8 --rdzv_id=456 --rdzv_backend=c10d --node-rank=1 --rdzv_endpoint=<master_node>:29603 lora_finetune_distributed --config recipes/configs/llama3/70B_lora.yaml output_dir=<created_checkpoint_folder_path>/lora-70b-bf16-sn checkpointer.output_dir=<created_checkpoint_folder_path>/lora-70b-bf16-sn dtype=bf16"The training now runs.
After training finishes, validate if the checkpoint exists:
1|939|Loss: 0.9668265581130981: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 939/939 [1:32:18<00:00, 5.65s/it]INFO:torchtune.utils.logging:Model checkpoint of size 9.17 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0001_0.ptINFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0002_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 10.00 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0003_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.93 GB saved to/created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0004_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0005_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0006_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0007_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 10.00 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0008_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.93 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0009_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0010_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0011_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0012_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 10.00 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0013_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.93 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0014_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0015_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0016_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0017_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 10.00 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0018_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.93 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0019_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0020_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0021_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0022_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 10.00 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0023_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.93 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0024_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0025_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0026_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.33 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0027_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 10.00 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0028_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 9.93 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0029_0.pt
INFO:torchtune.utils.logging:Model checkpoint of size 4.20 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/hf_model_0030_0.pt
INFO:torchtune.utils.logging:Adapter checkpoint of size 0.18 GB saved to /created_nfs_checkpoint_folder_path/torchtune/lora-70b-bf16-sn/adapter_0.pt
1|939|Loss: 0.9668265581130981: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 939/939 [1:46:54<00:00, 6.83s/it]
Now, let's check if the customized model is ready in our NFS folder that we created:
pmotgi@bcm10:/<checkpoint_folder>$ tree lora-70b-bf16-sn
lora-70b-bf16-sn
├── adapter_0.pt
├── config.json
├── hf_model_0001_0.pt
├── hf_model_0002_0.pt
├── hf_model_0003_0.pt
├── hf_model_0004_0.pt
├── hf_model_0005_0.pt
├── hf_model_0006_0.pt
├── hf_model_0007_0.pt
├── hf_model_0008_0.pt
├── hf_model_0009_0.pt
├── hf_model_0010_0.pt
├── hf_model_0011_0.pt
├── hf_model_0012_0.pt
├── hf_model_0013_0.pt
├── hf_model_0014_0.pt
├── hf_model_0015_0.pt
├── hf_model_0016_0.pt
├── hf_model_0017_0.pt
├── hf_model_0018_0.pt
├── hf_model_0019_0.pt
├── hf_model_0020_0.pt
├── hf_model_0021_0.pt
├── hf_model_0022_0.pt
├── hf_model_0023_0.pt
├── hf_model_0024_0.pt
├── hf_model_0025_0.pt
├── hf_model_0026_0.pt
├── hf_model_0027_0.pt
├── hf_model_0028_0.pt
├── hf_model_0029_0.pt
├── hf_model_0030_0.pt
└── run_0_1717639075.1460745
└── events.out.tfevents.1717639075.nlp-sft-worker-0.357.0
1 directory, 33 filesConclusion
This blog demonstrates how to run distributed fine-tuning on both a single node and multiple nodes using the new PyTorch native library, torchtune. This library seamlessly integrates with Hugging Face libraries for model and dataset loading. Notably, torchtune acts as a wrapper around the torchrun script, using all the advantages it offers. Additionally, it automatically adapts to the available PyTorch version on the device, eliminating versioning concerns for developers. Currently, PyTorch supports both bf16 and fp32 precision for AMD GPUs nightly, although older versions might lack bf16 support. Configuration files for torchtune runs enable consistent configurations across various use cases, allowing performance comparisons across different Llama 3 models. For full fine-tuning, only two adjustments are required in the tune run command:
- Specify the module name as full_finetune_distributed.
- Select the appropriate configuration file (for example, recipes/configs/llama3/70B_full.yaml).
Stay tuned for Part 2 of this blog, in which we will explore similar model customization using the Mosaic ML LLM Foundry framework.