




Empowering Enterprises with Generative AI: How Does MLPerf™ Help Support Requirements?
Fri, 14 Apr 2023 17:05:26 -0000
|Read Time: 0 minutes
Generative AI has developed into a critical workload in the deep learning ecosystem. In the generative AI world, 2023 has been a year of explosive growth as generative AI continues to make huge progress by improving the quality and ease of access to these ecosystems. With the advent of ChatGPT, Stable Diffusion, and so on, which have gained significant popularity, we can consider generative AI to be one of the pivotal use cases that mainstreams AI to the world. We expect to see generative AI push new frontiers and enable an explosion of productivity. This blog provides an overview of generative AI and its relevance to the MLCommonsTM AI system benchmark to which we submit on a frequent basis.
Introduction to Generative AI
Generative AI is a phenomenon by which AI systems (consisting of hardware and software) can produce plausible renders of images, audio, video, text, code, 3D renders, and so on when given an instruction prompt. The prompt can be text, voice, or other forms. Some popular examples include ChatGPT, Stable Diffusion image generator, and Text to speech engines.
These AI systems can enable a significant productivity boost by generating and modifying existing pieces of content that effectively improve the user’s workflow.
What can these AI Systems do?

Generative AI is capable of generating and optimizing:
- Chat and Text─This modality is useful for customer support, for generating blogs, ad copies, design guides, and technical reports, reading and taking action, answering questions, summarizing large documents, producing code that can run directly, inspiring developers to write improved code, and so on.
- Video generations:
- Talking head videos─These videos can be useful for content producers, tutorial guides, and so on in which personas are able to communicate with voice, lip syncing, and emotions, these are helpful for customer support and other interactive services.
- NERF (neural radiance fields) – Given a few angles from pictures, it can produce an entire scene of smooth footage that looks to be real. NERF can be useful in providing more perspective for a scene and enable more interesting viewpoints.
- High-resolution images─These creative images can be used for multiple purposes including B-rolls, explanation of ideas and simulated concepts, special effects, graphic vectors, infographics, backdrops, scenes and so on.
- High-fidelity audio─These audio samples can be voices, music, and so on. Voices can deliver emotions, be of high quality like voiceovers, and deliver speech for advertisements. Audio samples can also be songs for karaoke, songs with beats, customer support and so on.
- 3D Generations─These renders are useful for producing a new world with just imagination. They are powerful for VFX, VR, and other immersive experiences. These 3D generations can be used for creating digital clones of the real world, games, commercials, movies, and so on.
This blog does not highlight many other use cases. With more innovation and research, there will be a Cambrian explosion of more use cases that are fueled by generative AI. These models can also produce personalized content for the end user as opposed to serving generic material.
What kind of compute is needed to train these AI systems?
Training generative AI systems is a compute-intensive task. Typically, text generation, chatbots, and instruction followers have billions of parameters and use thousands of GPU hours. This task presents a large problem needing different mechanisms of parallelization, training update optimizations, including full stack (hardware and software) optimization, and so on.
For instance, the GPT3 model has 175 B parameters and the Megatron model has approximately 530 B parameters. Training and Inference procedures for these systems are significantly different than the traditional deep learning models that do not have as many parameters. For instance, large language models (LLMs) require large inference setups including multinode inference, scaling training to a trillion parameter models needing different mechanisms including dynamic sparsity, optimizing communication costs, self-tuning, and so on.
In essence, the compute needs for generative AI are ever growing in unique ways. While training generative AI models remains crucial for compute needs, the subsequent necessity for compute could be arriving from fine tuning and inferencing needs.
Why adapt now?
Generative AI has been in development for many years now; Transformers, Wavenet, GANs, Autoencoders with decoders, and so on have been around for quite some time. There has been much innovation in these areas, which continues to be mixed and matched to meet productive outcomes. For instance, the growth of multimodal models (models that take different kinds of inputs) facilitate a more collaborative workflow. Multimodal models form the cornerstone for enabling near human intelligence for a specific task. Although there is small chance of reaching human-level performance overall, these multimodal models can produce plausible results. Consumers of these systems can take the outputs, modify them and use them in their workflow. These systems render output quickly compared to a manual effort and provide more layers of creativity.
These plausible renders, ease of access, and open-source development have been an incredible fuel for popularizing generative AI systems. The next step is pushing these systems to perform better, whether by improving quality of service or improving throughput. Improving quality of service and throughput is an already established problem. To improve convergence and throughput, many benchmarks have been attempting to optimize AI systems.
Relationship to MLCommons
The MLCommons Training benchmark has been instrumental in enabling significant improvements for convergence of the training time of systems by taking a holistic view of the hardware and software. The MLCommons Inference benchmark has been conducive for optimizing the inference of AI systems.
Furthermore, MLCommons has generative AI benchmarks in their road map. For instance, LLM is part of MLCommons v3.0 training; Stable Diffusion is scheduled to be included as part of MLCommons v3.1 training.
The need to continuously improve systems is essential, more so now for generative AI use cases. We can see that the MLCommons community has made significant improvements in performance every year. These optimizations from vendors, benchmarks, and the deep learning community continue to serve this generative AI effort. All these efforts make adoption of generative AI more attractive now.
Paradigms
Some fundamental models that are used for generative AI workloads in MLPerf benchmarks include:
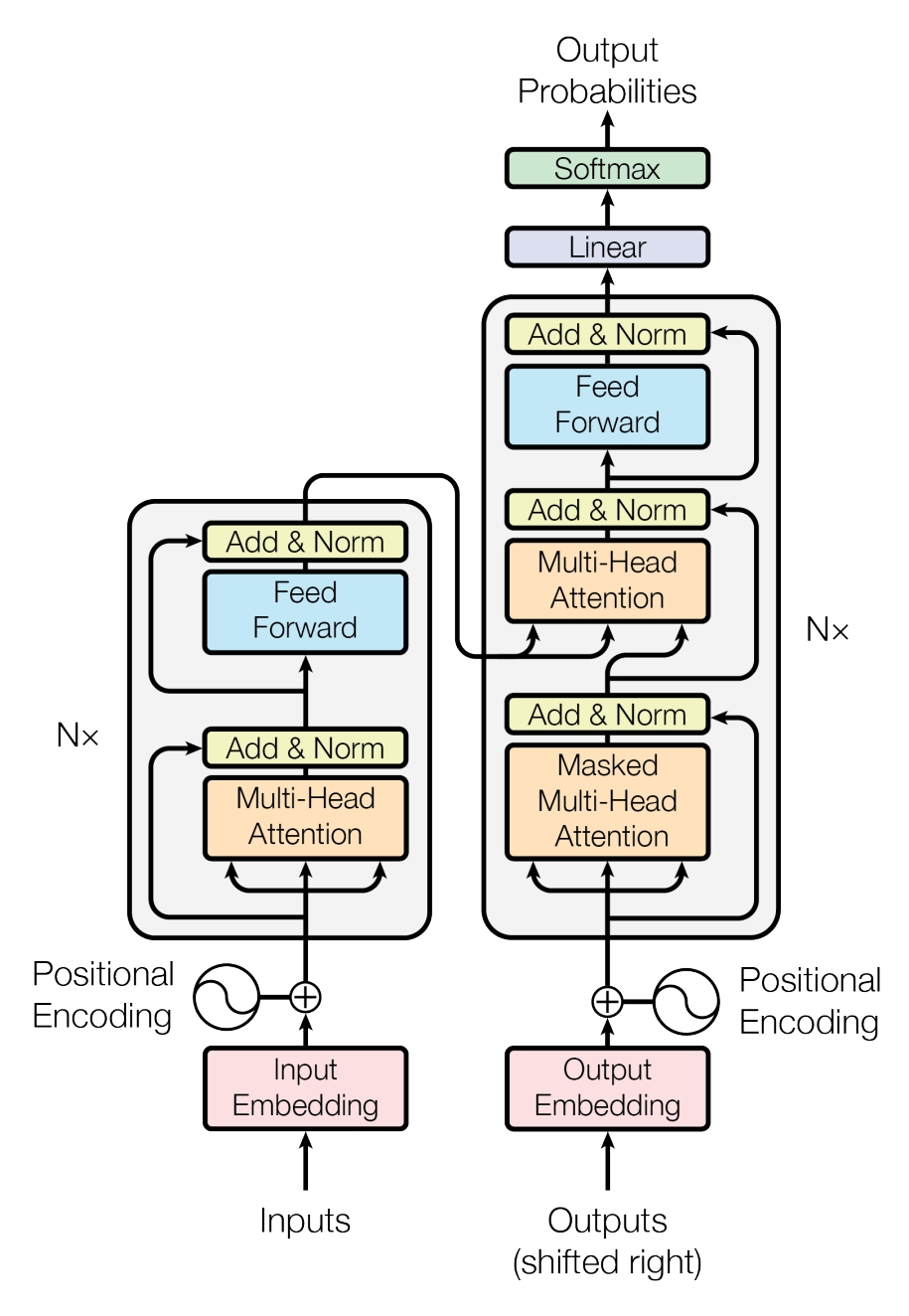
Figure 1: Transformer architecture
- Transformer─This model uses an attention mechanism to model areas of interest in a specific context. This method allows building relationships that signify how one element relates to others.
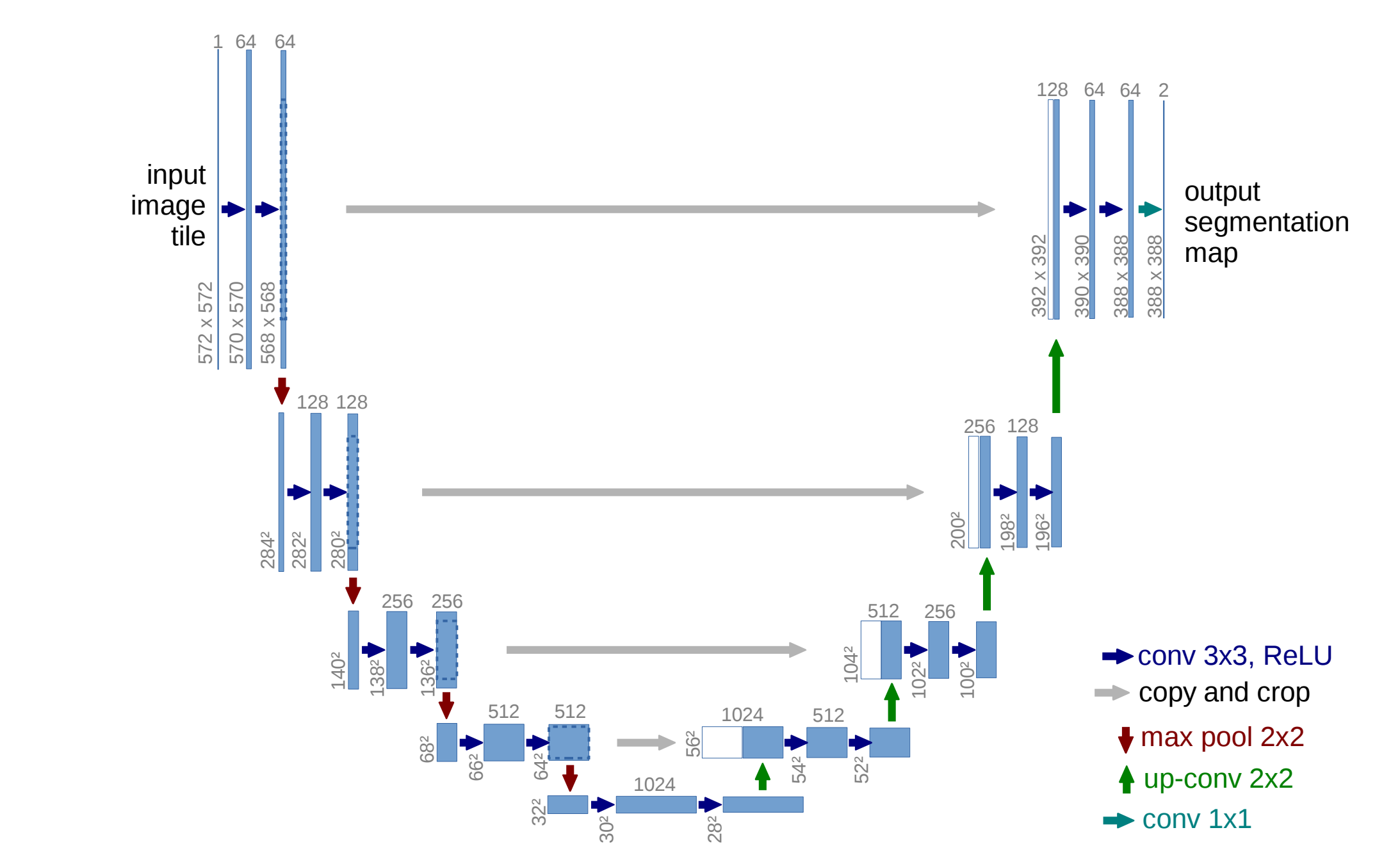
Figure 2: U-Net architecture
- 3d-UNet─This model uses convolution and pooling blocks to set up a contractive and expanding path that creates a bottleneck. The image is reconstructed from this bottleneck. The bottleneck captures the compression of data; only important information is used to reconstruct the image.
How is generative AI relevant to MLPerf Training and Inference?
MLPerf Training uses the BERT language model. Many text-based generative AI workloads are LLMs. While BERT is not as large as GPT3 (about 1/500th the size of GPT3 based on a number of parameters (340 M compared to 175 B)) it has fundamental blocks that GPT3 uses.
For instance, BERT uses multiple Attention Heads, Layernorms SoftMax, and so on, which GPT3 also uses. While parameters, layer count, and model size are larger for GPT3, BERT uses fundamentally similar procedures that are essential for training.
Conversely, Stable Diffusion uses UNet layers. This method is useful for constructing images of high quality. It takes encoded text and uses the UNet bottleneck to effectively enable a denoising procedure. 3D-UNet is a part of the MLPerf benchmark, which is optimized.
The preceding examples show that optimizations used in MLPerf are transferable, and we can use current MLPerf models to be a relative proxy to the generative AI workloads.
Furthermore, MLPerf includes LLMs and Stable Diffusion on the road map for the upcoming training submission versions. We can expect optimized versions of these implementations to be made available to the public.
The links in the references show optimizations made by NVIDIA for the benchmarks. Customers can take the already optimized references and use them for their generative AI use cases.
We recognize the importance of AI workloads including generative AI. Therefore, we submit to MLCommons benchmarks that provide like-to-like comparisons with different OEMs and vendors. Scale is an important aspect of generative AI workloads. We have introduced the new PowerEdge XE9680 server that produces stellar performance at scale. The following figure shows the performance improvement from MLPerf Inference v2.1 to MLPerf Inference v3.0.
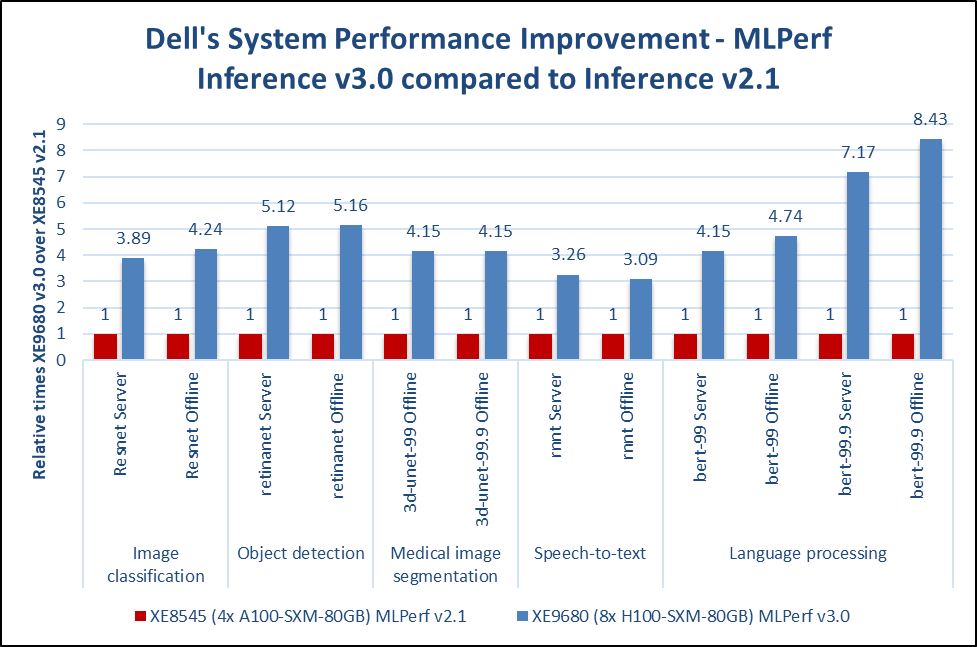
* MLPerf ID 2.1-0014 and MLPerf ID 3.0-0013
Figure 3: MLPerf Inference 3.0 vs Inference 2.1 performance improvement from XE9680 server having 8xH100 GPUs compared to XE8545 having 4xA100 GPUs
PowerEdge XE9680 and XE8545 systems are an excellent choice for generative AI workloads. Customers can expect faster time to value and these systems scale very well, as attributed by the MLPerf training results.
Conclusion
While generative AI has produced enormous excitement, there are many challenges such as biased outputs, incorrect answers, hallucinations, instability, and so on that require monitoring and policing. Generative AI systems still cannot make autonomous decisions tied to other algorithms for mission-critical applications.
The latest MLPerf Inference 3.0 results show up to three times to eight times improvements for all categories. These improvements show Dell Technologies’ commitment to continuously enable improvement in performance. We understand generative AI is an important class of AI workload; Dell hardware supports these workloads. By upgrading to the latest servers, such as the PowerEdge XE9680 servers, customers can derive a faster time to value. Dell Technologies can help customers adapt and deploy generative AI workloads.
To summarize, compute, quality of service (plausible outputs), open-source development, and ease of access are major drivers for mass adoption of generative AI. Organizations can leverage these drivers to produce outputs for their workflow. Enabling these systems with humans in the loop are good first steps to boosting productivity. Dell Technologies has been making MLPerf submissions to show how our servers can deliver excellent performance. The optimizations made for MLPerf are transferable to generative AI workloads.
References
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/1505.04597
https://developer.nvidia.com/blog/leading-mlperf-training-2-1-with-full-stack-optimizations-for-ai/
https://developer.nvidia.com/blog/boosting-mlperf-training-performance-with-full-stack-optimization/