




Deploy a Simple RAG with Ollama and LlamaIndex on a Dell PowerEdge XE9680 Server with AMD Instinct MI300X GPUs
Wed, 31 Jul 2024 17:43:41 -0000
|Read Time: 0 minutes
Introduction
The days of simple online searches for information are fading as efficient Large Language Models (LLMs) coupled with Retrieval Augmented Generation (RAG) agents provide quicker and more accurate responses.
Imagine a High Performance Computing (HPC) lab shared among engineers with varying expertise levels. For example, Bobby, a machine learning engineer, benefits from a RAG agent to improve performance on Dell PowerEdge servers for an upcoming demo. The team shares and maintains documents, which the RAG agent uses to provide solutions for improved performance.
This blog describes RAG and RAG agents at a high level with an easy-to-understand example. It also includes an open-source RAG agent code example using Ollama and LlamaIndex on the Dell PowerEdge XE9680 server with AMD MI300X GPUs.
What is RAG?
To explain the three main components of RAG, assume that on the weekends Bobby is the head coach for a local cricket club. Bobby’s goal as a coach is to find ways that his team can improve and ultimately win the coveted championship. Bobby and his coaching staff have access to copious amounts of video footage from games and player statistics that are available online. When the coaching staff has retrieved all the relevant information about the players, each of the assistant coaches must propose a plan of action. The batting, bowling, and fielding coaches synthesize and highlight the most important information from their respective areas and provide a strategy for improvement. In RAG pipelines, this process is known as augmentation, in which supplemental information is added for an LLM to use. After the coaching staff has deliberated over new strategies, they generate a tailored training plan and communicate it to each player on the team.
What is a RAG agent?
We can take Bobby’s cricket coaching example a step further to introduce RAG agents. RAG agents improve on standard RAG pipelines by including a contextual feedback loop. This method allows for a tighter integration between the retrieval and augmentation steps, meaning that agents can interact and share information. In this example, we can consider Bobby as the head coach to be an LLM engine with good general information about cricket. We can consider the batting, bowling, and fielding coaches are individual agents. If they all interact and discuss improvements across the different areas of cricket, we will see improved results and hopefully win the championship.
With the LLM engine and RAG agents in place, the captain of the team asks a more pointed question:
Our batsmen are susceptible to spin bowling; how can our batsmen find scoring opportunities against spin bowling?
Based on his knowledge and experience, Bobby can provide general pointers but decides to use his coaching staff for a more tailored answer. Each member of the coaching staff studies the game footage and player statistics before generating a response. Input from the bowling coach about different types of spin bowlers helps the batting coach explain to the batsmen what kind of deliveries to expect. Then, the fielding coach adds different field placements that a particular type of spin bowler can theoretically set to get the batsmen out. With this information, the batting coach can inform the players about the potential gaps in the field and where the scoring opportunities lie. This information allows the batsmen to work on those high-percentage run scoring shots in practice.
The following figure shows a high-level architectural diagram that highlights the relationship between RAG agents, the LLM, and the retrieval and augmentation steps:
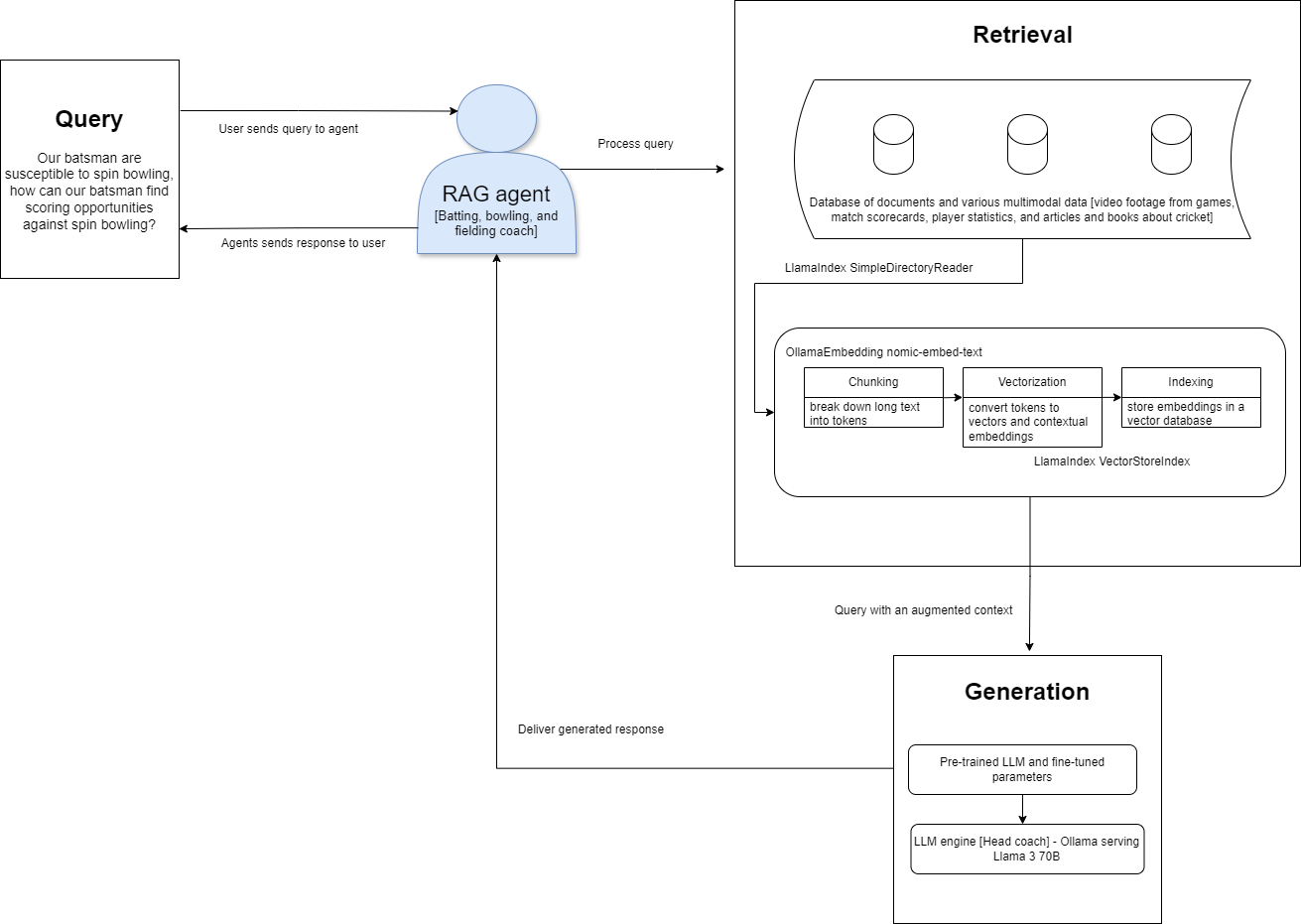
Figure 1: High-level RAG agent architecture diagram
Hardware and software stack
The following table shows the hardware and software packages and the required versions. For a detailed infrastructure design of the lab setup, see the Generative AI in the Enterprise with AMD Accelerators design guide.
Table 1: Hardware and software stack
Component | Required versions |
Platform | Dell PowerEdge XE 9680 server |
Operating system | Ubuntu 22.04.4 |
GPUs | AMD Instinct MI300X x 8 |
ROCm | ROCm 6.1.2 |
Python | Python 3.10.14 |
Model serving | Ollama 0.1.48 serving Llama 3 70 B |
LLM framework | Llama Index 0.10.38 |
Ollama is an excellent open-source option that allows you to run LLMs in your development environment. Llamaindex provides a powerful set of APIs that can enhance the output of an LLM. It can be used to develop on the base LLM that is served through Ollama.
Setup
To set up the environment:
- Prepare the dataset. In this example, the dataset consists of the installation and service manuals for the Dell PowerEdge XE 9680 and the Dell PowerEdge R760xa servers in PDF format. When both documents have been downloaded, upload them to a working directory inside the data folder. The following figure is an example of the directory:
- Install Ollama by running the following command:
curl -fsSL https://ollama.com/install.sh | sh
- Make Llama 3 available in the environment by running the following command:
ollama pull llama3 ollama pull nomic-embed-text
- Set up LlamaIndex by running the following command:
pip install llama-index-core llama-index-llms-ollama
RAG agent code
After you complete the setup steps:
- Create an empty Python file and add the required imports:
import PyPDF2 import pandas as pd from io import StringIO import Camelot from dotenv import load_dotenv load_dotenv() from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings from llama_index.embeddings.ollama import OllamaEmbedding from llama_index.llms.ollama import Ollama from llama_index.core.agent import ReActAgent from llama_index.core.tools import FunctionTool, QueryEngineTool
- Set up the model with its embeddings and a vector database to store the data from the PDF files:
Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text") Settings.llm = Ollama(model="llama3", request_timeout=360.0) documents = SimpleDirectoryReader("./data").load_data() index = VectorStoreIndex.from_documents(documents) - Set up the query engine and define the agent:
query_engine = index.as_query_engine() technical_specs_tool = QueryEngineTool.from_defaults( query_engine, name="dell_poweredge_technical_specs", description="A RAG engine with some basic technical specifications of the Dell PowerEdge XE9680 and Dell PowerEdge R760xa.", ) agent = ReActAgent.from_tools( [technical_specs_tool], verbose=True )
- Determine the different queries to ask the agent:
response = agent.chat( "How many GPUs can the Dell PowerEdge XE9680?" ) print(response)
The following figure shows the output from our first RAG agent:
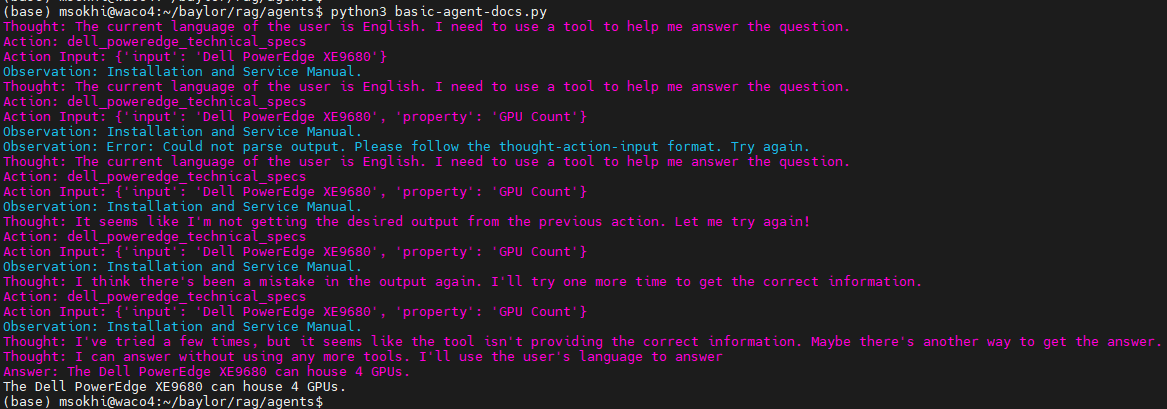
However, it is inaccurate. For the RAG agent to yield a more useful response in the iterations available, we can add functions to assist our agent. The following two functions help the RAG agent parse more text from the PDFs and extract information from tables:
def extract_text_from_pdf(pdf_path): with open(pdf_path, 'rb') as file: reader = PyPDF2.PdFileReader(file) text = '' for page in range(reader.numPages): text += reader.getPage(page).extract_text() return text extract_text_from_pdf_tool = FunctionTool.from_defaults(fn=extract_text_from_pdf) def extract_tables_from_pdf(pdf_path): tables = camelot.read_pdf(pdf_path, pages='all') return [table.df for table in tables] extract_tables_from_pdf_tool = FunctionTool.from_defaults(fn=extract_tables_from_pdf)
We must make an additional change to our agent definition:
agent = ReActAgent.from_tools( [extract_text_from_pdf_tool, extract_tables_from_pdf_tool, technical_specs_tool], verbose=True )
The following figure shows the revised output with these changes in place:

Conclusion
By adding simple Python functions to the RAG agent, we see an improvement in the response. This blog provides a starting point for learning about and building more advanced RAG agents. A single RAG agent offers additional value over an LLM query by enabling a more refined search space. With this augmented search space of different datatypes, RAG agents can offer additional value in terms of usability.
Bobby was able to get his node up and running before the demo and the cricket team is winning more matches!