



Dell PowerEdge Servers demonstrate excellent performance in MLPerf™ Training 3.0 benchmark
Tue, 27 Jun 2023 19:49:45 -0000
|Read Time: 0 minutes
MLPerf Training v3.0 has just been released and Dell Technologies results are shining brighter than ever. Our submission includes benchmarking test results from new generation servers that were recently launched, such as Dell PowerEdge XE9680, XE8640, and R760xa servers, and our previous generation of servers, such as the PowerEdge XE8545 and R750xa servers. Our submission included various use cases in the MLPerf training benchmark such as image classification, medical image segmentation, lightweight and heavy weight object detection, speech recognition, NLP, and recommendation. We encourage you to read our previous whitepaper about MLPerf Training v2.0, which introduces the MLPerf training benchmark. These benchmarks serve as a reference for the kind of performance customers can expect.
Dell Technologies also announced Project Helix, which introduced a solution that customers can use to run their generative AI workloads.
What’s new with MLPerf Training 3.0 with Dell submissions?
New features for this submission include:
- Significantly improved performance gains.
- Results that include NVIDIA H100 Tensor Core GPUs. Our results included submission to the newly introduced DLRMv2 benchmark, which has multihot encodings.
- First-time training submission using new generation Dell PowerEdge servers.
- First and only multinode results using Cornelis Omnipath interconnect fabric.
- More multinode results using different interconnect fabrics.
Overview of results
Dell Technologies submitted a total of 91 results, the highest number of results compared to other submitters, which constitute over one-third of all the closed division results. These results were submitted using 27 different systems. The most outstanding results were from Dell PowerEdge XE9680, XE8640, and R760xa servers with the new NVIDIA H100 PCIe and NVIDIA H100 SXM form factor-based accelerators. The results included multinodes. Other accelerators included NVIDIA A100 PCIE and SXM form factors.
Interesting data points include the following:
- Among other servers with four GPUs having the NVIDIA H100 PCIe accelerator, the Dell PowerEdge R760xa server has the lowest time to converge in MaskRCNN, ResNet, and UNet-3D benchmarks. Similarly, for the four NVIDIA H100 SXM accelerators, the PowerEdge XE8640 server had the lowest time to converge with BERT, DLRMv2, ResNet, and UNet-3D benchmarks.
- The Dell PowerEdge R760xa server features PCIe Gen 5, which allows for faster multi-GPU training. Our submissions included PowerEdge R750xa and R760xa servers with the same accelerators to show the performance gains customers can expect.
- MLPerf Training 3.0 was the first time that Dell Technologies made an eight-way NVIDIA SXM form factor accelerator submission for training workloads. The Dell PowerEdge XE9680 server with eight NVIDIA HGX H100 SXM GPUs had the lowest time to converge on the ResNet-50 benchmark among eight-GPU configurations, and has closely performed among other NVIDIA HGX systems on other benchmarks.
- Multinode results demonstrate near linear scaling, which shows that customers can gain faster time to value with all the workloads. These multinode submissions include different interconnects such as InfiniBand and Cornelis Omnipath, which allows for customers to make tradeoffs.
- Results for different Dell PowerEdge servers that render different accelerator TDP were submitted. These results are useful for scenarios in which the data center is power-constrained. These results help with FLOPS per watt decisions.
- Intel and AMD-based server submissions enable customers to see how CPUs can influence the training process.
- Our results included not only various systems, but also exceeded performance gains compared to the last round due to the newer generation of hardware acceleration from the newer server and accelerator.
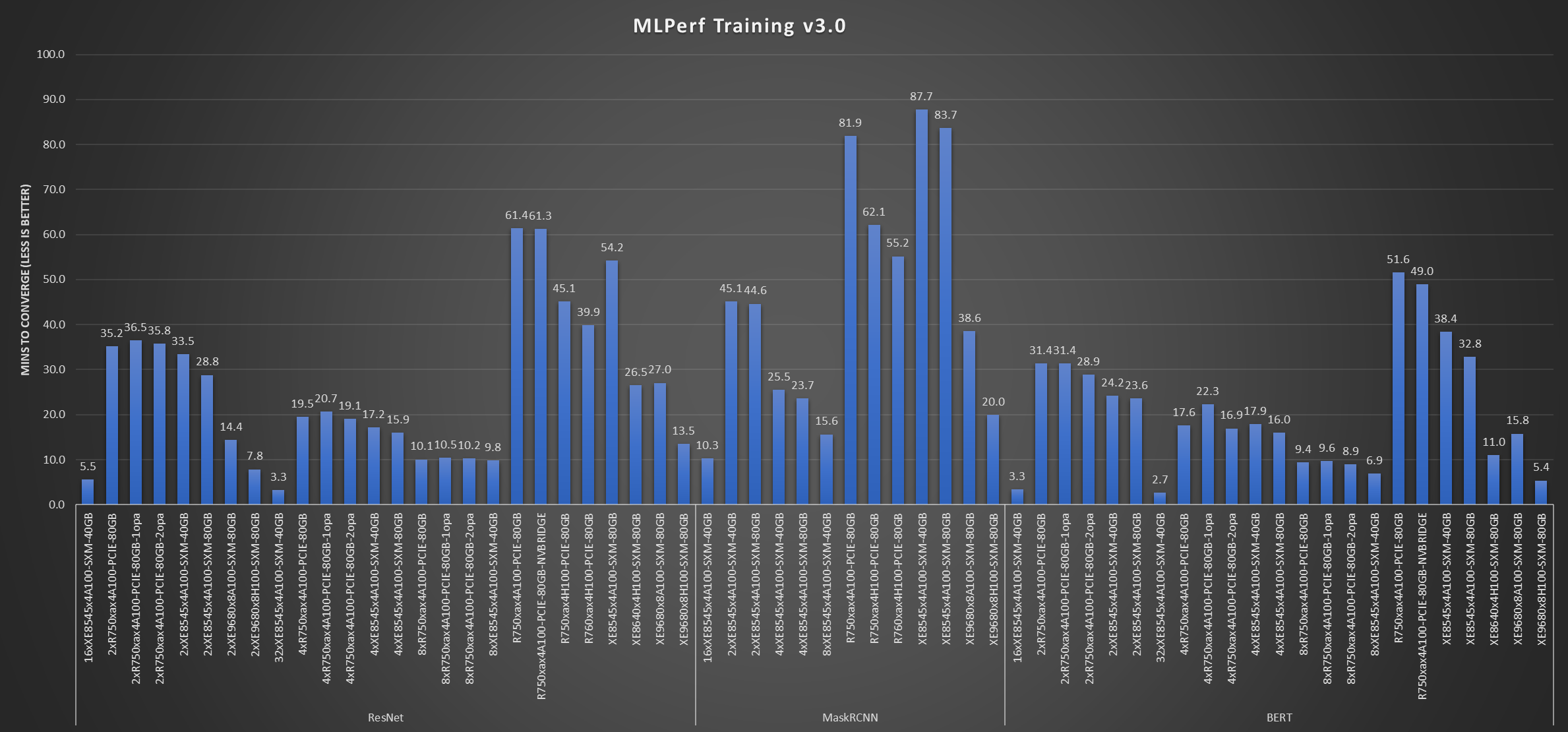
Fig 1: Dell systems used for ResNet, MaskRCNN, and BERT benchmarks
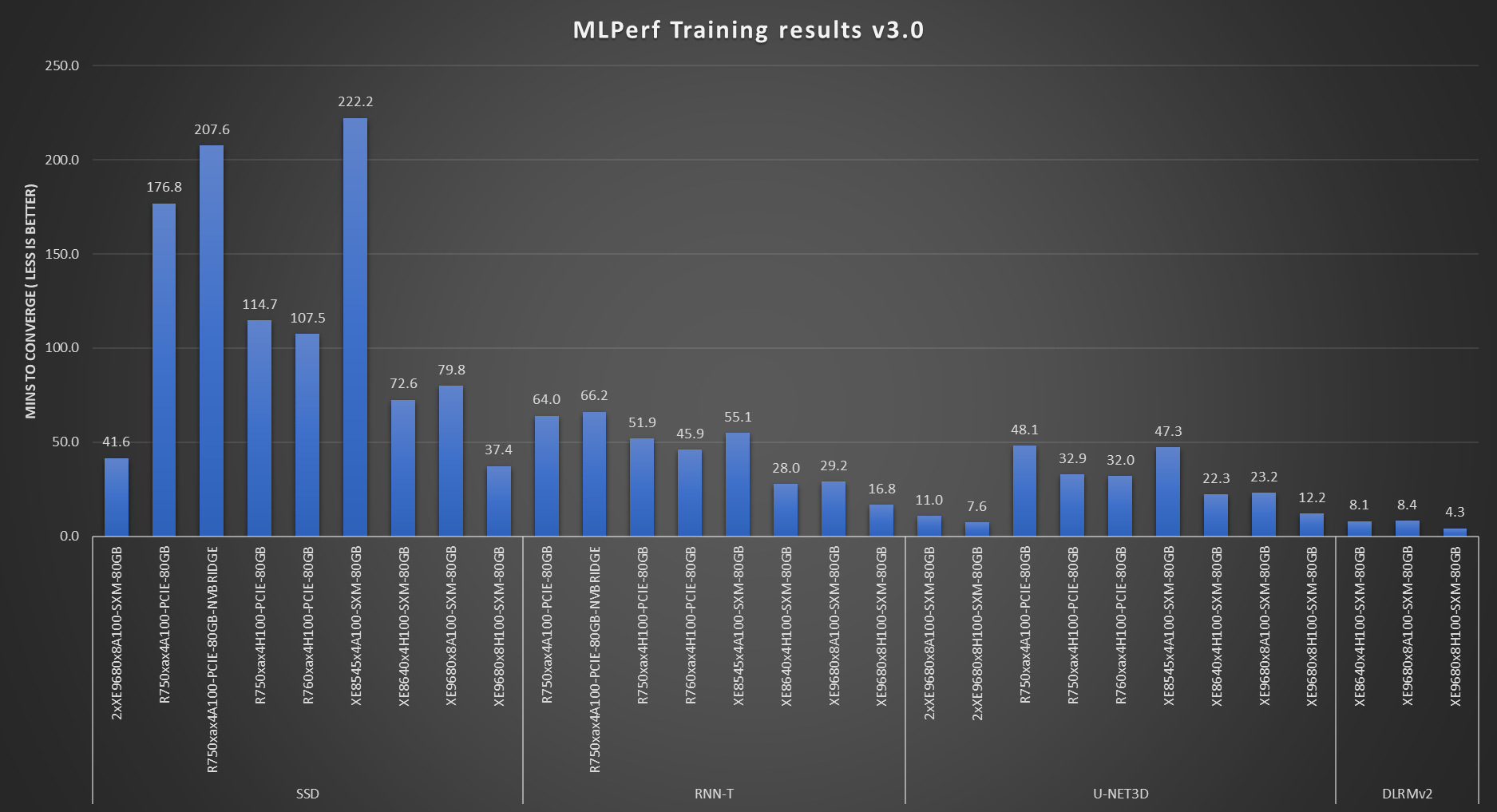
Fig 2: Dell systems used for SSD, RNN-T, UNnet-3D, and DLRM benchmarks
Figure 1 and Figure 2 list the systems and corresponding NVIDIA GPUs that were used in tests. We see that various systems with different NVIDIA GPUs were used for different use cases such as ResNet-50, MaskRCNN, BERT, SSD, RNN-T, UNet-3D, and DLRMv2. All the systems performed optimally and delivered low time to converge. These results also include multinode results.
The single server with the lowest time to converge is the Dell PowerEdge XE9680 server, which delivers incredible time to value for training and inference workloads. These systems scale well and enable the current demand for very high compute. Large AI workloads, including sizable generative AI training (LLMs), can be trained on multiple PowerEdge XE9680 servers.
The following figure shows the improvement in performance from the previous submission. It shows the best Dell single-system training submission results compared to the previous round of submissions.
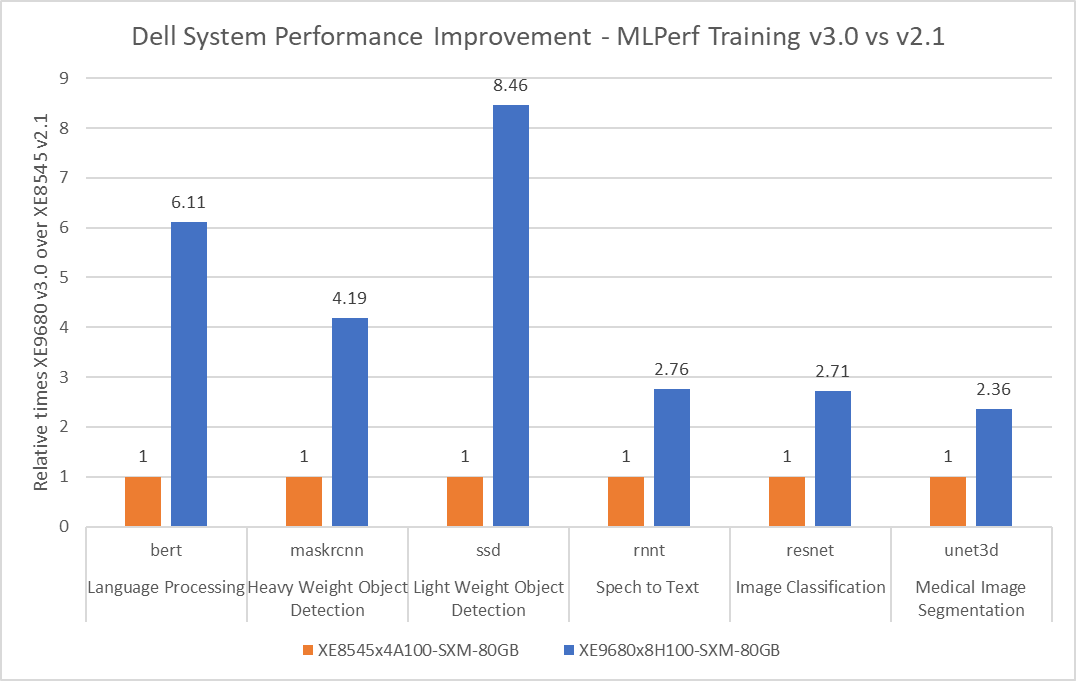
Fig 3: Performance improvement factor using a Dell PowerEdge XE9680 server with the previous generation Dell PowerEdge XE8545 server as a baseline across different benchmark
The figure shows the performance gains customers can expect if they upgrade to the latest generation of servers. Note that the latest generation server, the Dell PowerEdge XE9680 server, has eight NVIDIA H100 SXM GPUs; the previous generation Dell PowerEdge XE8545 server has four NVIDIA A100 SXM GPUs.
The most improvement at 846 percent was observed with the SSD benchmark, followed by the BERT benchmark at 611 percent. Other benchmarks yielded a greater than 230 percent improvement. These results are significant. The two-times improvement in time to train means more time for other workloads in the data center, yielding faster time to value for the business. With this acceleration, customers can expect faster prototyping, model training, and expedite their MLOps pipeline.
Conclusion
We have submitted compliant results for the MLCommons Training 3.0 benchmark. These results are numerous, using different servers powered by NVIDIA GPUs. Results show multinode scaling is linear, where more servers can help to solve the problem faster. Having various results helps customers choose the best server for their data center setting to deploy training workloads. Newer generation servers such as Dell PowerEdge XE9680, XE8640, and R760xa servers all deliver high performance while breaking MLCommons records across different use cases such as image classification, medical image segmentation, lightweight and heavy weight object detection, speech recognition, NLP, and recommendation. Furthermore, Project Helix offers customers an effective way to derive value from generative AI. Enterprises can enable their AI transformation with Dell Technologies efficiently to enable faster time to value to uniquely fit their needs.
MLCommons Results
https://mlcommons.org/en/training-normal-30/
The graphs above are MLCommons results MLPerf IDs from 3.0-2027 to 3.0-2053
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.