
Consume data and Analyze
Consume data and Analyze
-
Once the transformed data lands in ECS it can be immediately consumed by the Data Lakehouse, converted to Apache Iceberg table format, and queried.
Step 1: Using an S3 client we can list the location where the data was uploaded by the BMC AMI cloud storage API:aws --profile ddlh --endpoint-url https://10.243.19.39:9021 s3 ls s3://kbhive/mainframe_dump/samplefile/
2024-08-21 10:18:02 0
2024-08-21 10:20:14 5199280 MKTCWR.DELL.CRBMCDDB.CRINDDTS.P001
Step 2: Configure the Dell Data Lakehouse catalog
S3 Storage
The Dell Data Lakehouse is backed by an S3 storage platform like Dell ECS or PowerScale for storing and processing large datasets in open file and table formats.
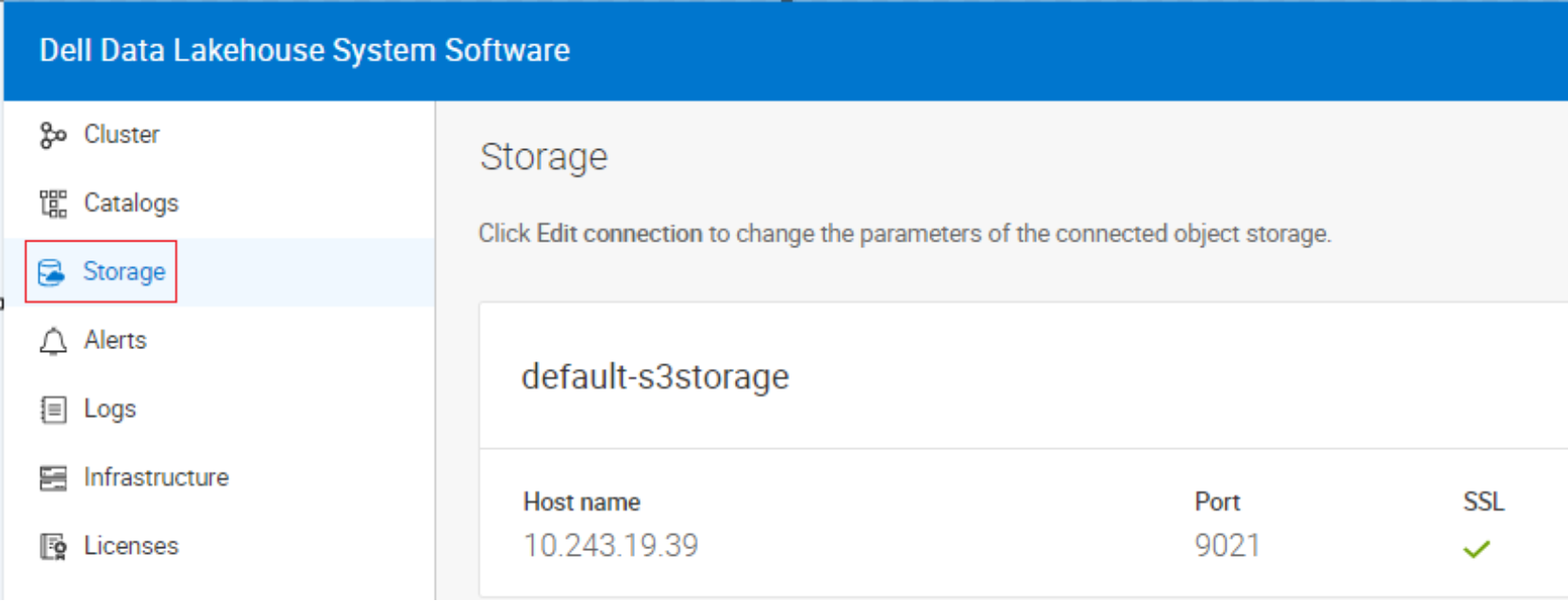
Figure 6. S3 Storage connection details
Catalogs
A catalog contains the configuration that allows the Dell Data Analytics Engine to access a data source.
The Hive Metastore (HMS) provides a central repository of metadata that can easily be analyzed to make informed, data driven decisions, and therefore it is a critical component of many data lake architectures.
The Dell Data lakehouse includes a Hive Metastore out-of-the-box which means an external Metastore is not necessary.
For this solution we’ll be using two different catalogs:
Hive
The Hive connector allows querying data stored in an Apache Hive data warehouse. As seen in the below image it includes a property to access S3 Storage.
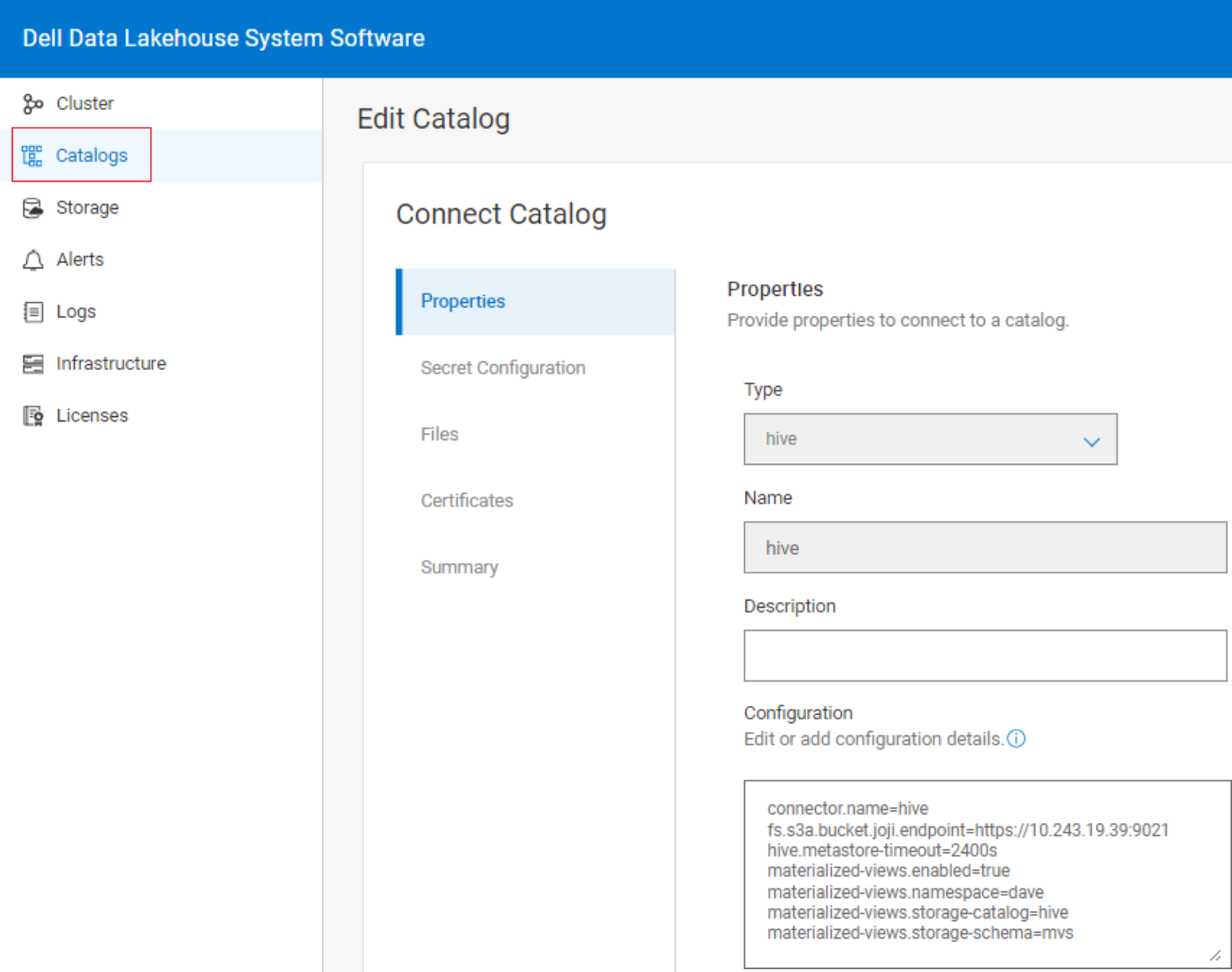
Figure 7. The Hive Catalog properties
S3 Credentials
The S3 access and secret keys can be defined as properties in the catalog however, best security practices would be to add them as key and value pairs in the Secret Configuration screen.
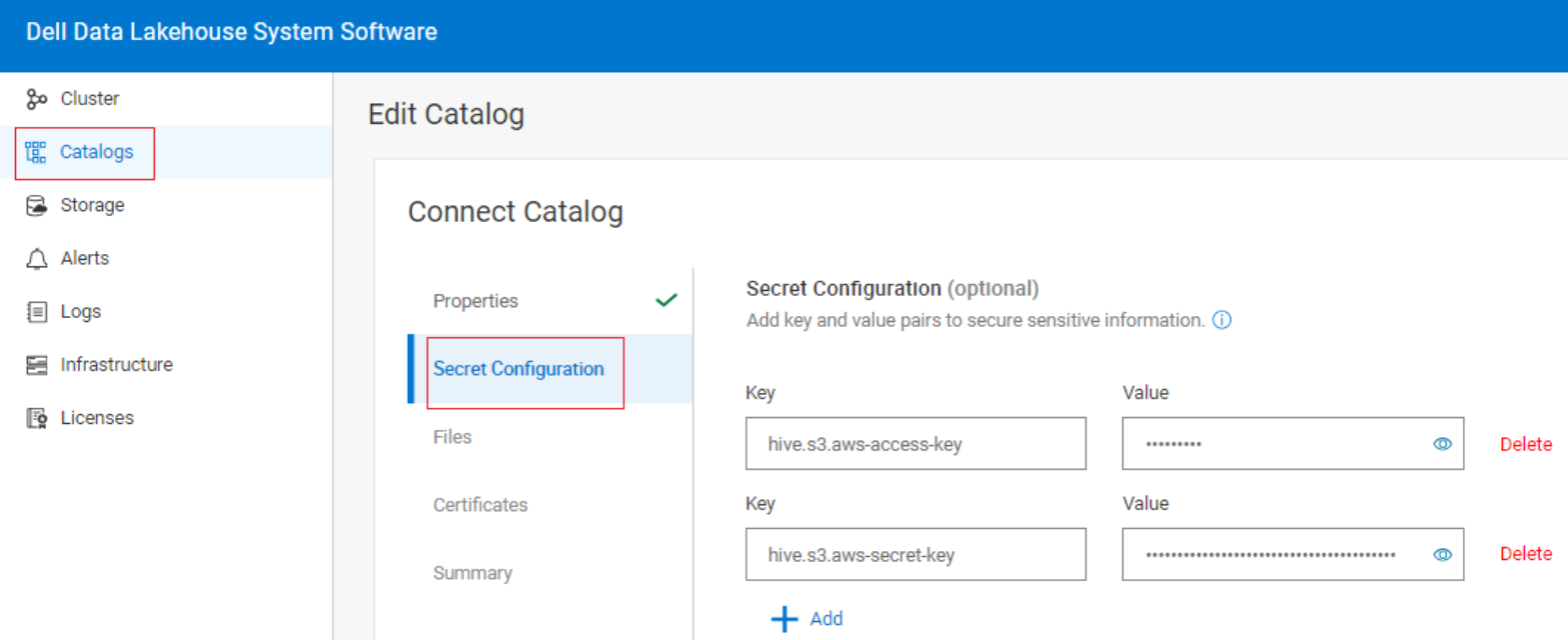
Figure 8. S3 Secret Configuration
Step 3: Create the schema and table from the Dell Data Analytics Engine
Create the Schema
We create the schema in the ‘hive’ catalog providing a schema name and location. Note that the location is the same one we queried with an S3 client in Step 1.
CREATE SCHEMA hive.kbmainframe WITH (LOCATION = 's3a://kbhive/mainframe_dump');
Create the Table
Next create a table specifying the columns and data types. We skip the first line in the file because it specifies the column names.
CREATE TABLE hive.kbmainframe.samplefile (
primary_key_a VARCHAR,
primary_key_b VARCHAR,
firstnm VARCHAR,
lastnm VARCHAR,
phone VARCHAR,
ent_date VARCHAR,
first_order_date VARCHAR,
userid VARCHAR)
WITH (FORMAT = 'CSV',
skip_header_line_count = 1
);
Verify the table schema is reflected on the Dell Data Analytics Engine Catalog under the Hive Catalog.
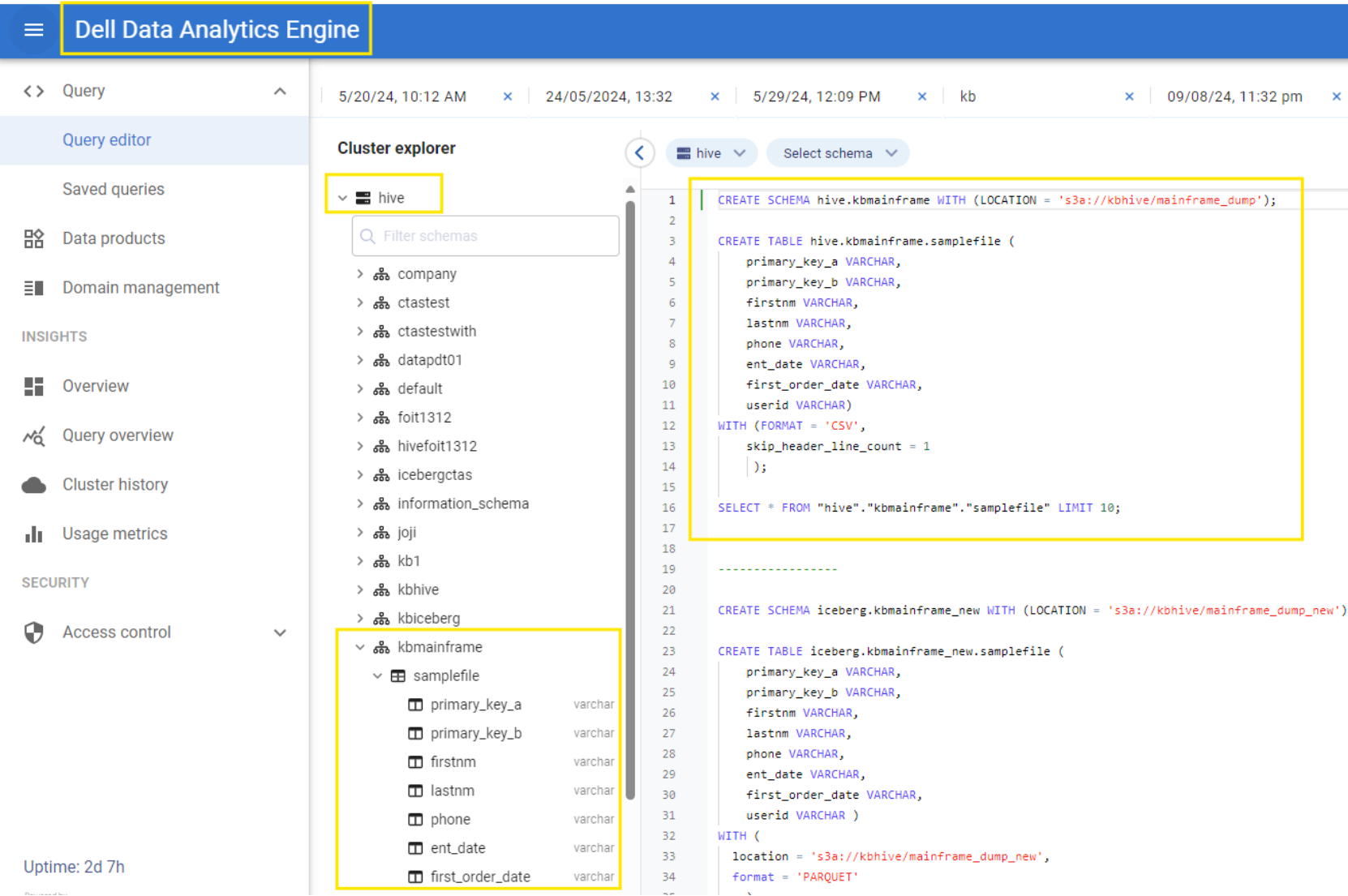
Figure 9. New Table Schema and Table Name reflected under Hive Catalog
Query the table
Now we can query the data in the table.
SELECT * FROM "hive"."kbmainframe"."samplefile" LIMIT 10;
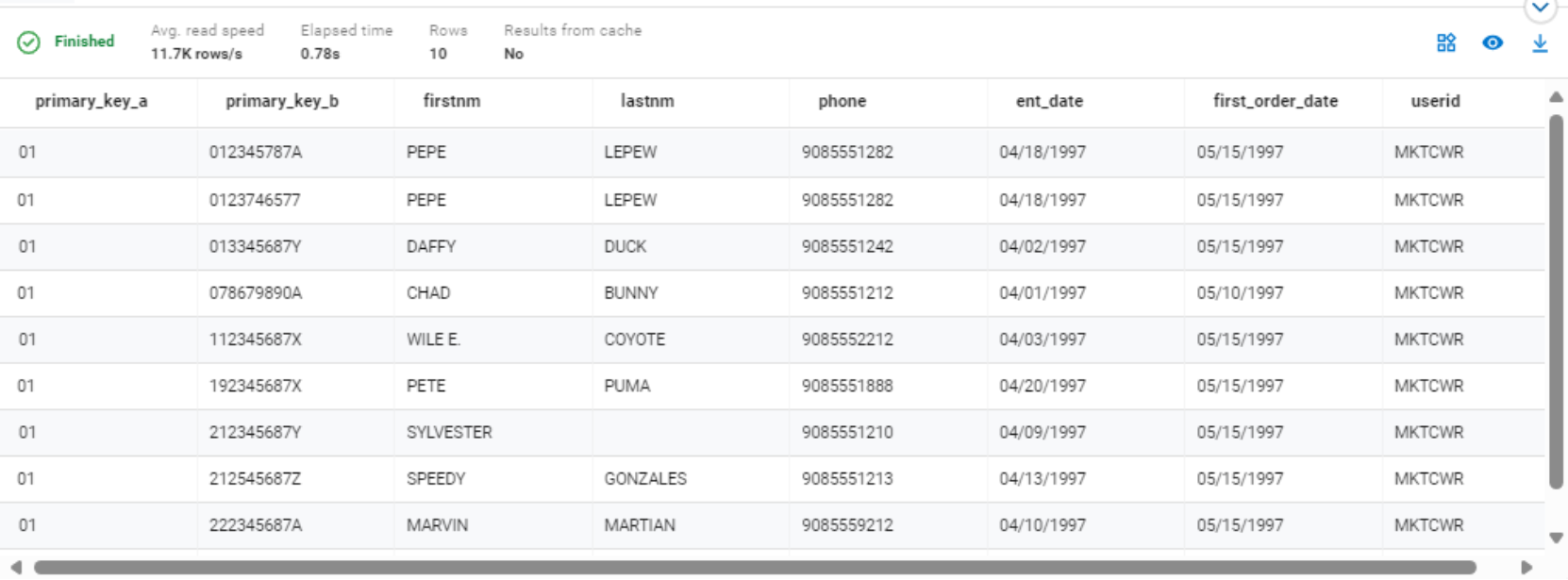
Figure 10. Hive query results
Step 4: Use a CREATE TABLE AS statement to read the data from the hive catalog table and write it to a new table in the Iceberg catalog.
Apache Iceberg is a new open-source, high-performance data table format designed for large-scale data platforms. Its primary goal is to bring the reliability and simplicity of SQL tables to big data while providing a scalable and efficient way to store and manage data. This performance is especially important in the context of big data workloads. Iceberg makes it possible for engines such as Spark, Trino, Flink, Presto, Hive, and Impala to safely work with the same tables, simultaneously. It addresses some of the limitations of traditional data storage formats such as Apache Parquet and ORC.
Create the Schema in the Iceberg catalog
CREATE SCHEMA iceberg.kbmainframe_new WITH (LOCATION = 's3a://kbhive/mainframe_dump_new');
Create the Table
CREATE TABLE iceberg.kbmainframe_new.samplefile (
primary_key_a VARCHAR,
primary_key_b VARCHAR,
firstnm VARCHAR,
lastnm VARCHAR,
phone VARCHAR,
ent_date VARCHAR,
first_order_date VARCHAR,
userid VARCHAR )
WITH (
location = 's3a://kbhive/mainframe_dump_new',
format = 'PARQUET'
);
Insert data to the new table
Execute a CTAS query to copy the data from the hive.kbmainframe.samplefile table in the hive catalog to our Iceberg table.
INSERT into iceberg.kbmainframe_new.samplefile (select * from hive.kbmainframe.samplefile);
Query the table
Now we can query the new table.
SELECT * FROM "iceberg"."kbmainframe_new"."samplefile" LIMIT 10;
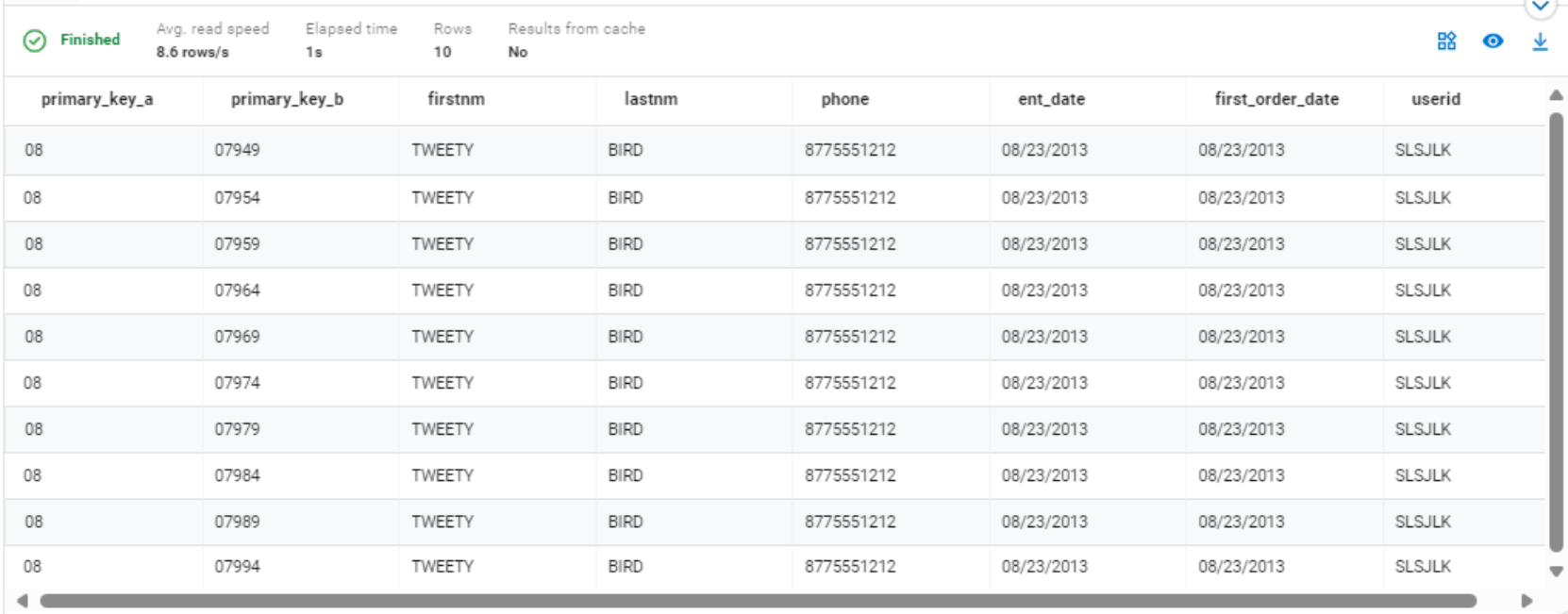
Figure 11. Iceberg table query results
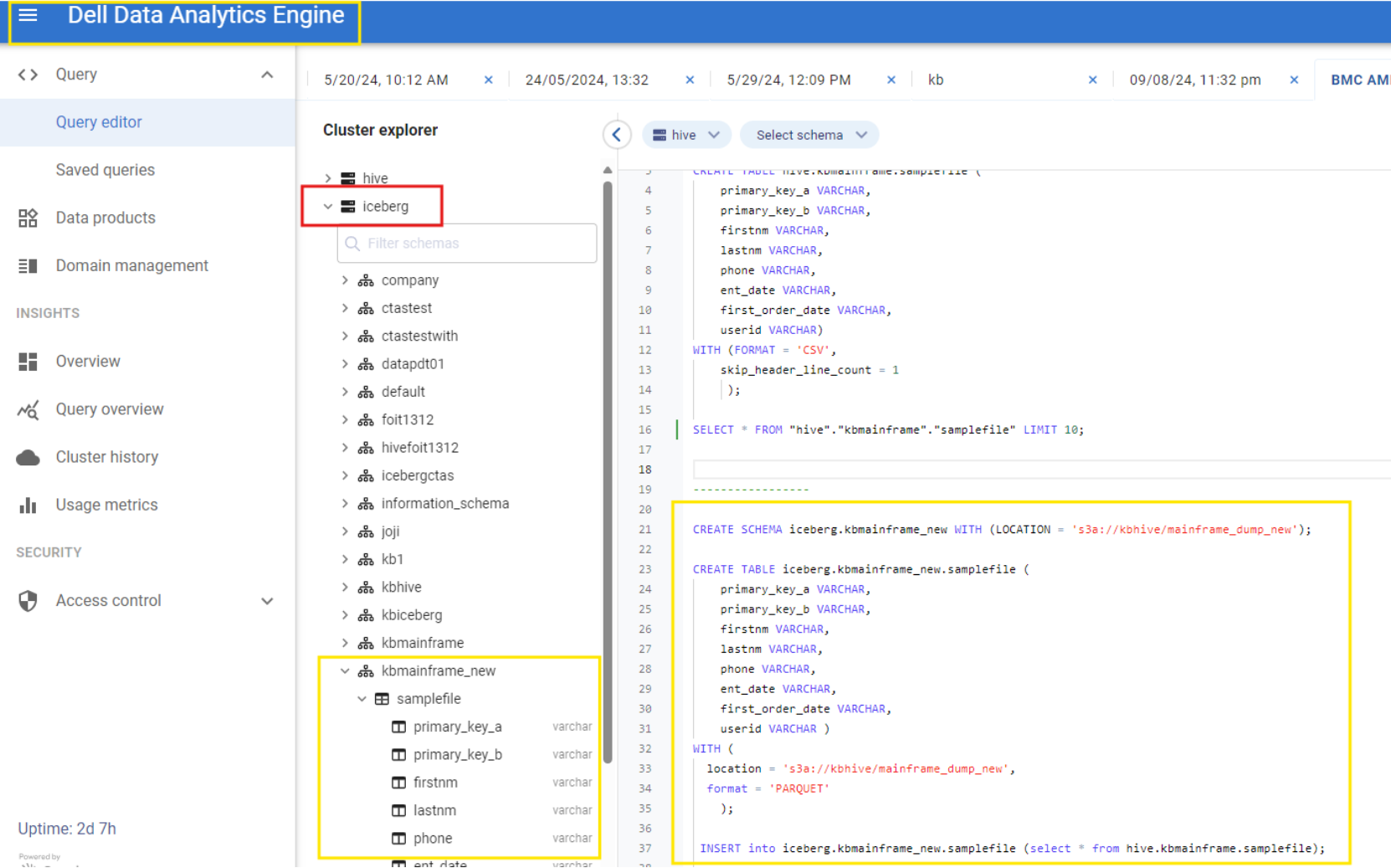
Verify the new Schema and Tables for Mainframe dataset created under iceberg catalog. The iceberg open table formats stores data underneath in Parquet file format. This provides better storage footprint, faster data access over the network, and results in improved analytical performance on the mainframe data.
Figure 12. New Table Schema and Table Name reflected under Iceberg Catalog
Using an S3 client we can list the location and see that there are 2 folders or prefixes which are created under the mainframe_dump_new folder.
aws --profile ddlh --endpoint-url https://10.243.19.39:9021 s3 ls s3://kbhive/mainframe_dump_new/samplefile/
PRE data/
PRE metadata/
2024-08-23 06:26:39 0
The data folder contains files that can be in Parquet, ORC, or AVRO format, and store the actual data for the Iceberg Table.
The metadata folder has files that are part of the metadata layer and contain details about the schema of the table, current snapshot ID information, and the manifest-list file