
Solution approach
Solution approach
-
The solution approach for this design is to train a popular LLM to show both GPU and storage scaling. To keep the design applicable to today’s GenAI workflows, a LLAMA 2 model architecture was chosen with 7B and 70B parameter counts.
Table 1. Solution system configuration
Component
Configuration 1
Configuration 2
Compute server for model customization
1 x PowerEdge XE9680 servers
6 x PowerEdge XE9680 servers
GPUs per server
8 x NVIDIA H100 SXM GPUs
8 x NVIDIA H100 SXM GPUs
Ethernet Network adapters
2 x NVIDIA ConnectX-6 DX Dual Port 100 GbE
2 x NVIDIA ConnectX-6 DX Dual Port 100 GbE
Ethernet Network switch
2 x PowerSwitch S5232F-ON
2 x PowerSwitch S5232F-ON
InfiniBand Network adapter
4 x NVIDIA ConnectX-7, Single Port NDR OSFP PCIe,
No Crypto, Full Height4 x NVIDIA ConnectX-7,
Single Port NDR OSFP PCIe,
No Crypto, Full HeightInfiniBand Network switch
QM9790
QM9790
PowerScale F600 Cluster
3 x PowerScale F600 Performance Optimized nodes
3 x PowerScale F600 Performance Optimized nodes

Figure 4. Network connectivity of PowerEdge training nodes, PowerScale storage, and control plane nodes
Figure 4 shows the network architecture and connectivity for the PowerEdge training nodes, PowerScale storage, and the three control plane nodes that incorporate NVIDIA Base Command Manager Essentials and other software components.
Software design
The NVIDIA AI software stack is the primary software used in this design. NVIDIA enterprise software solutions are designed to give IT admins, data scientists, architects, and designers access to the tools they need to easily manage and optimize their accelerated systems.
NVIDIA AI Enterprise
NVIDIA AI Enterprise, the software layer of the NVIDIA AI platform, accelerates the data science pipeline and streamlines development and deployment of production AI, including generative AI, computer vision, speech AI, and more. This secure, stable, cloud-native platform of AI software includes over 100 frameworks, pretrained models, and tools that accelerate data processing, simplify model training and optimization, and streamline deployment.
Table 2. Software components and versions
Component
Details
Operating system
Ubuntu 22.04.1 LTS
Cluster management
NVIDIA Base Command Manager Essentials 10.23.12
Slurm cluster
Slurm 23.02.4
AI framework
NVIDIA NeMo Framework v23.11
The solution design presented here is modular, and each of the components can be independently scaled depending on the customer’s workflow and application requirements.
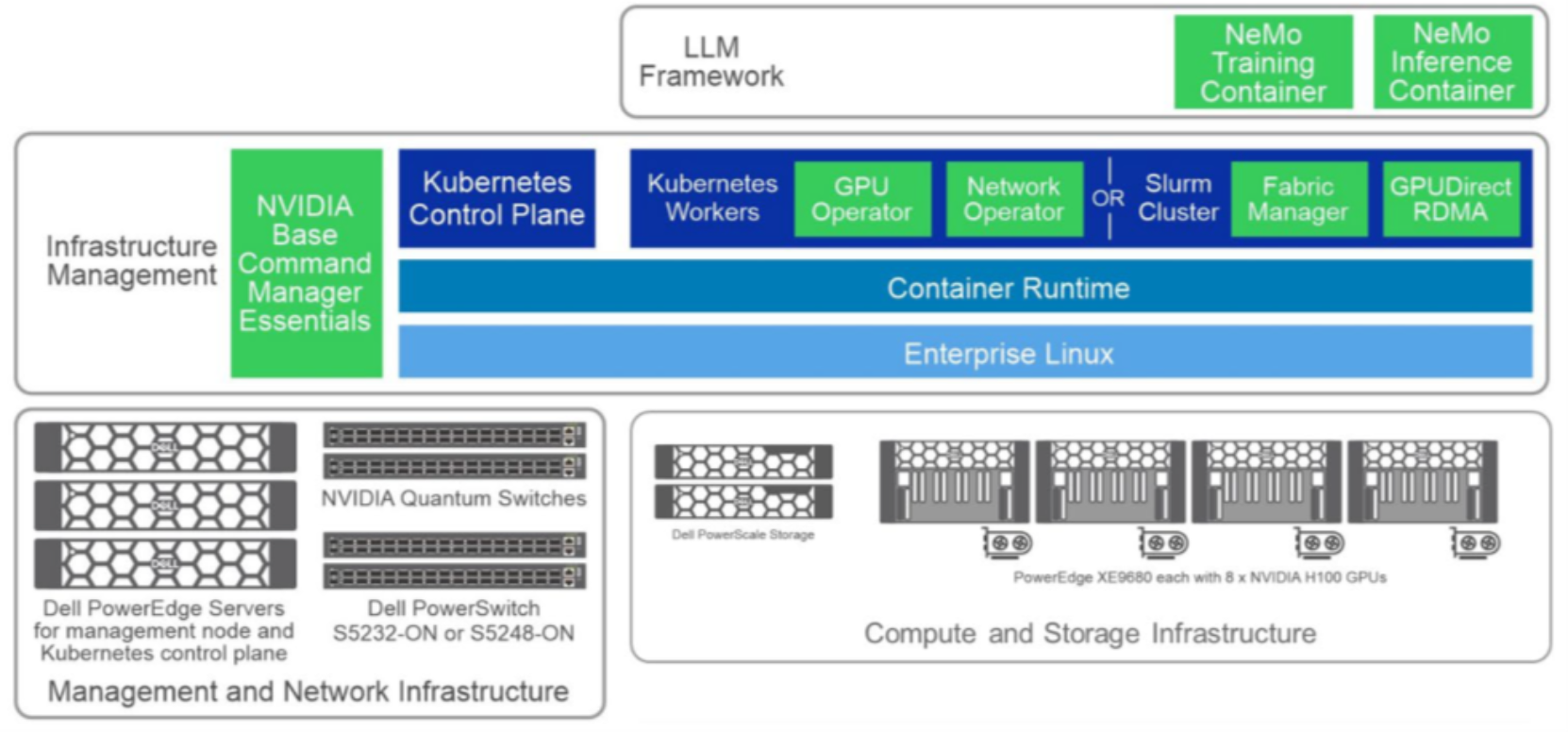
Figure 5. High-level software components used in testing
The goal in this validation was not to train a model to convergence and generate a complete foundational model, but rather to train for a defined number of steps.
The following list provides the details of our validation setup:
- Model architectures – 7B and 70B Llama 2 model architectures.
- Cluster configuration – Slurm for cluster management and job scheduling.
- Dataset – A Pile dataset was used for this validation. The Pile is an 825 GiB diverse, open-source language modeling dataset that consists of 22 smaller, high-quality datasets combined, derived primarily from academic and professional sources. Only 2 shards of the dataset (40G after tokenization) were used for this experiment.
- Storage Impact – Measure the impact of different training operations on the storage system. The initial data loading will read training data from the storage into GPUs while checkpointing during the training will show up as writes. These phases of the training process will be examined from a storage performance perspective.
- Time for training – The time to train will not be discussed in this document. Refer to GenAI in the Enterprise - Model Training for more on training time and a more thorough GPU examination.