
Solution architecture
Solution architecture
-
Validating a solution architecture for running Microsoft SQL Server 2022 on the Red Hat® OpenShift® Container Platform, Red Hat® OpenShift® Data Foundation, and Dell ObjectScale object storage is a critical step to ensure a robust and scalable deployment.
Figure 1 provides an overview of the physical architecture that was used in this validation.
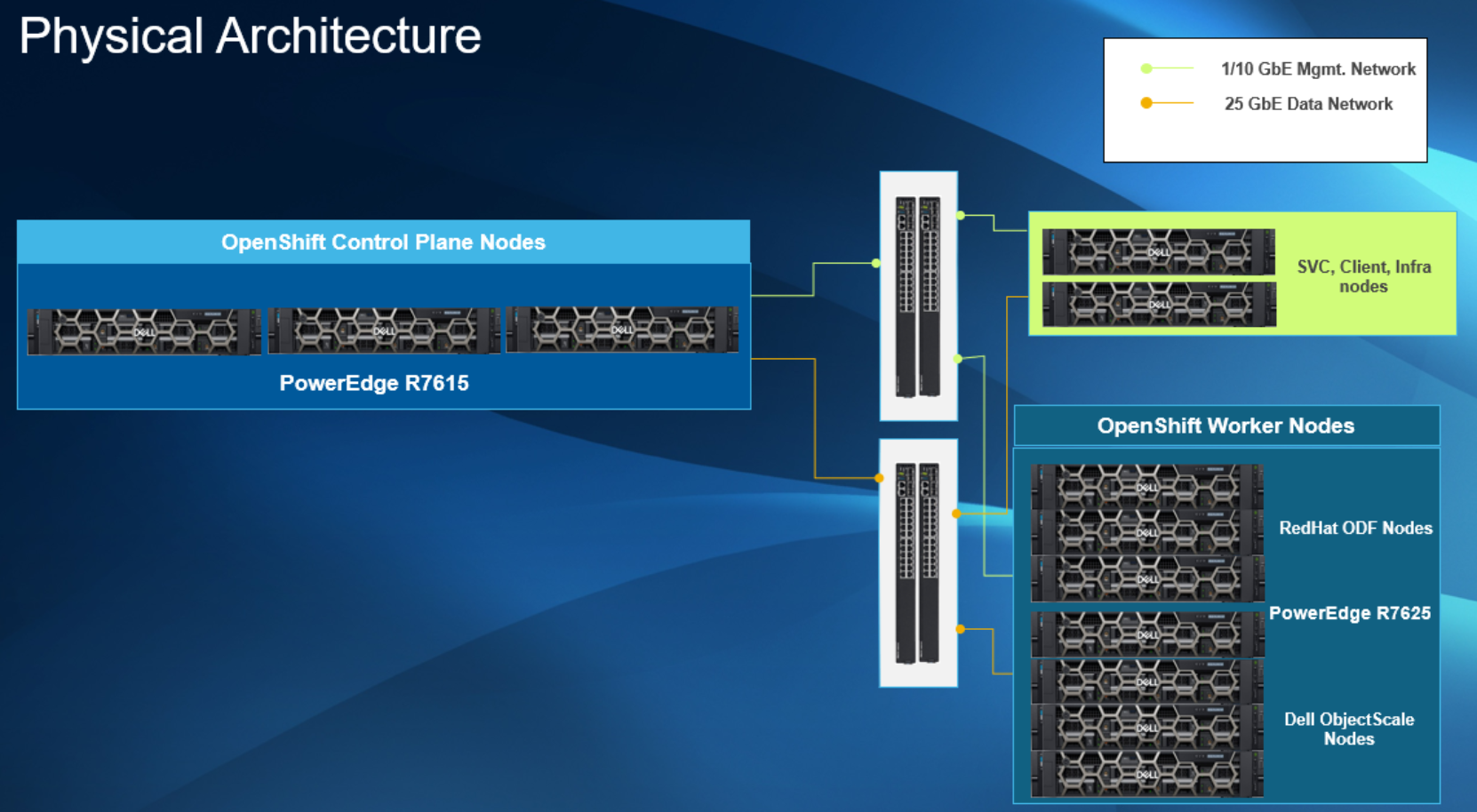 Figure 1. Physical architecture
Figure 1. Physical architectureThe physical components in this validation include:
- 7 x Dell PowerEdge R7625 Servers as compute nodes
- 3 x Dell PowerEdge R7615 Servers as control plane nodes
- 2 x PowerSwitch S5248F-ON top of rack switches for the data path (25 GbE)
- 2 x Management switches for out-of-band connectivity (1GbE/10GbE)
The Dell PowerEdge R7625 servers contain two AMD EPYC 9334 processors with each processor containing 32 physical cores. This dual-socket server model was configured as worker nodes. There were seven worker nodes total in this validation. These worker nodes have enough CPU power to handle the compute resources needed for SQL analytic workloads and provide capacity for both persistent block storage and object storage.
For the OpenShift® control plane nodes, we used three Dell PowerEdge R7615 servers. This single socket server model contains one AMD EPYC 9124 processor with 16 physical cores.
The Dell PowerSwitch S5248F-ON delivers 25 GbE open networking that provides state-of-the-art, high-density switching. These switches provide flexibility for changing network configurations and adapt to the containerized compute cluster.
Figures 2 and 3 show the details of the PowerEdge R7625 and R7615 server models.

Figure 2. PowerEdge R7625 worker node details
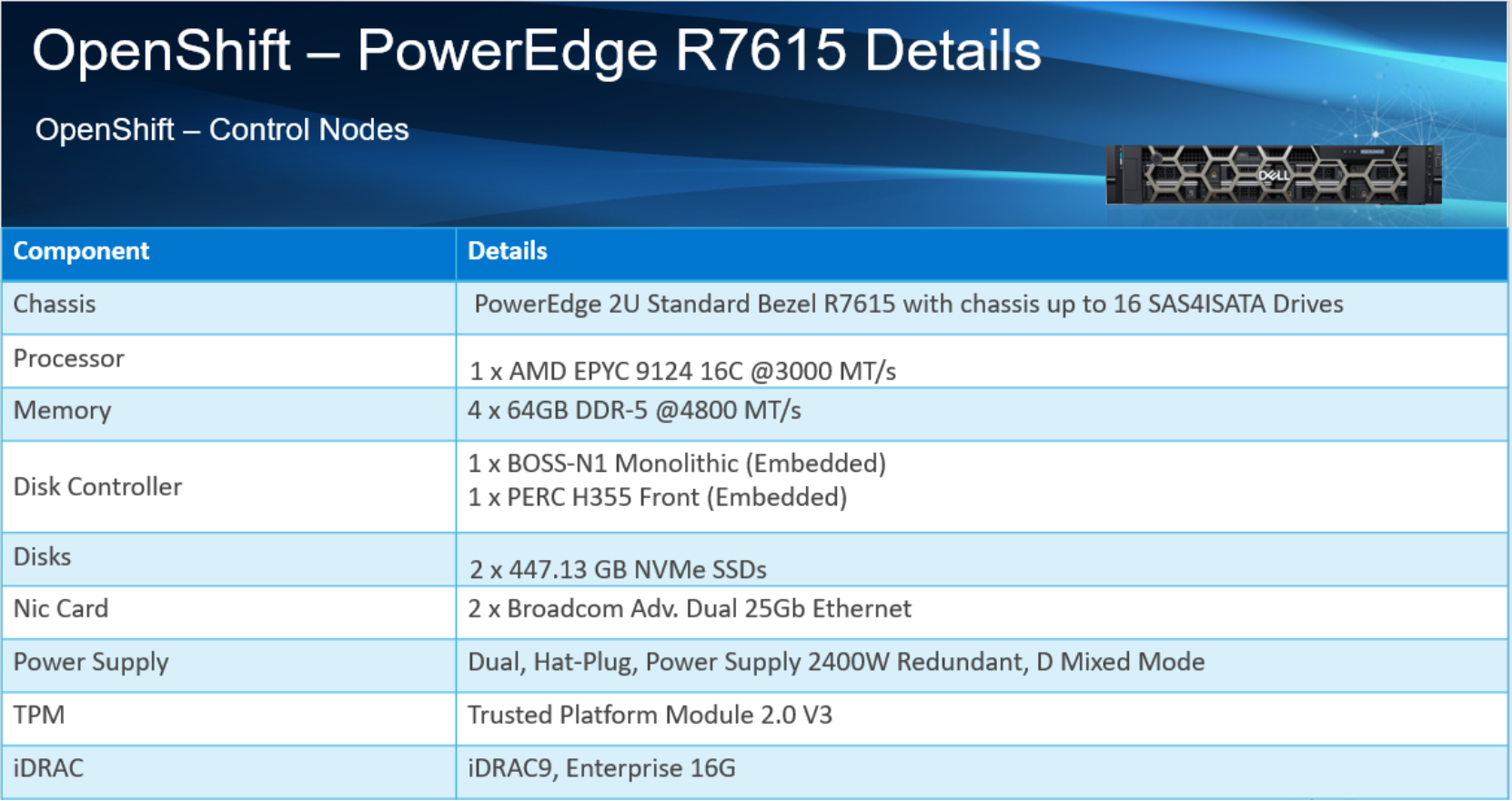 Figure 3. PowerEdge R7615 control plane node details
Figure 3. PowerEdge R7615 control plane node details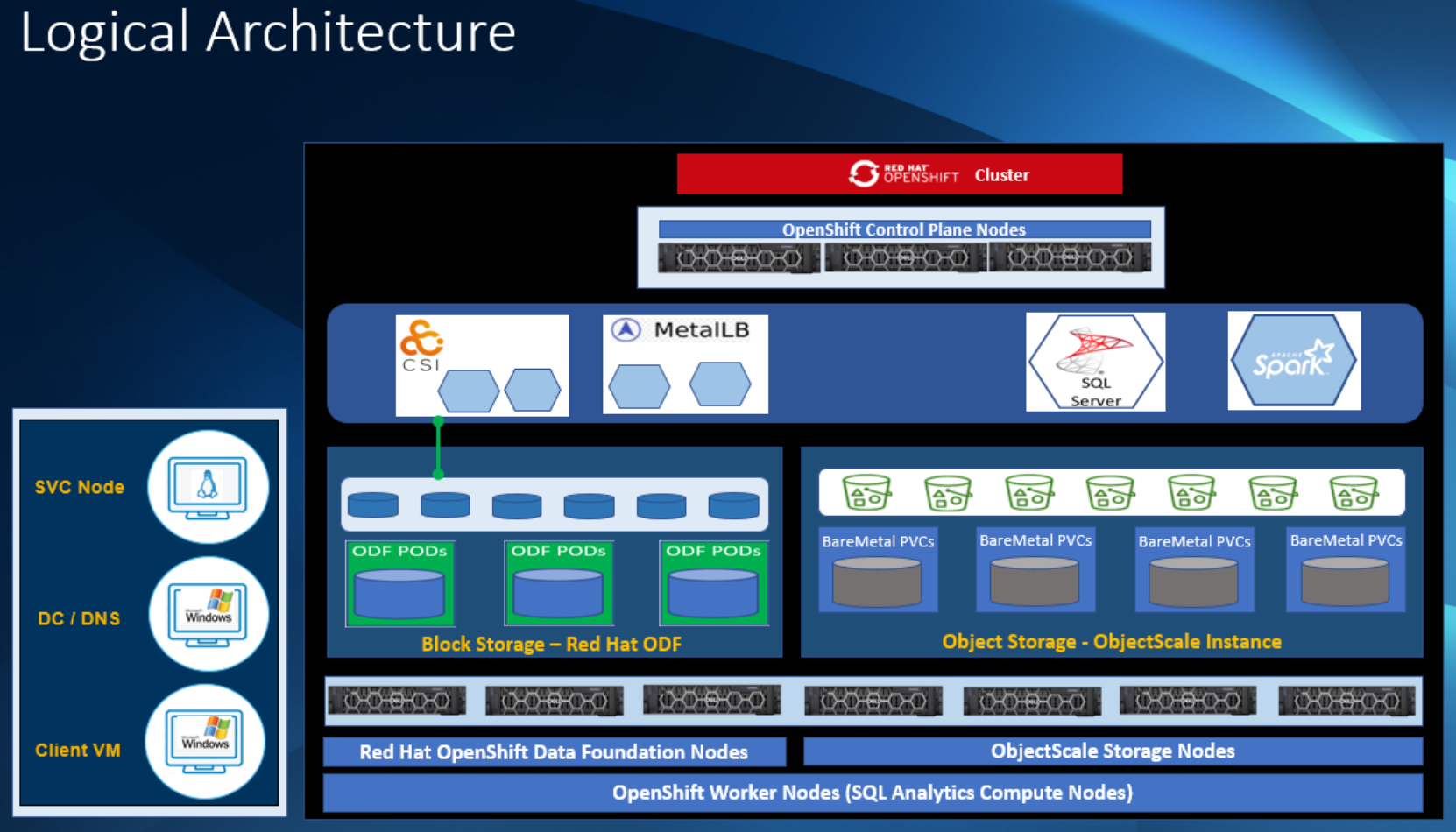 Figure 4. Logical architecture
Figure 4. Logical architectureThe following list includes the main components in the logical architecture:
- Red Hat® OpenShift® Container Platform: Red Hat OpenShift is the industry leader for hybrid cloud application platform powered by Kubernetes and brings together tested and trusted services to reduce the friction of developing, modernizing, deploying, running, and managing applications.
Red Hat OpenShift is the key pillar to this solution because one of the focus areas during development was to create a cloud-native data analytics solution that could be location agnostic and provide a consistent user experience across public cloud, on-premises, hybrid cloud, or edge infrastructure.
- Red Hat® OpenShift® Data Foundation (ODF): Red Hat OpenShift Data Foundation is a highly integrated collection of cloud storage and data services for Red Hat OpenShift Container Platform. It is available as part of the Red Hat OpenShift Container Platform Service Catalog, packaged as an operator to facilitate simple deployment and management.
We used ODF as a hyperconverged cloud native Block Storage provider for our overall solution. Each SQL Server instance deployed on OpenShift requires a reliable and performant block storage to store its data, logs, and TempDB files.
- Dell ObjectScale: - Dell ObjectScale is the next evolution of object storage from Dell and is built to run efficiently in Kubernetes, on shared infrastructure, and in multi-tenant environments.
ObjectScale gives organizations the power to put data closer to the applications they support, reducing latency and improving the user experience. Additionally, object storage from disparate platforms can cross-replicate for greater access, reliability, and redundancy. ObjectScale is an enterprise-grade object storage with these features and functionality:
- Simple, S3-compatible enterprise-grade object storage
- Kubernetes-based, customer-deployable
- Scaled-out, software-defined architecture
- Improved data protection with new erasure coding schemes
- New replication model with eventual consistency for greater availability during hardware failure
- Integrated management of bucket or object events enabling bucket notifications, ObjectScale replication, and metering
- A complete multi-tenant IAM service with IAM accounts and other IAM entities, like Users, Groups, Roles, Policies, and Service Providers
- Delta Lakehouse: Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, Ruby, and Python. Databricks originally developed the Delta Lake protocol and continues to actively contribute to the open-source project.
Delta Lake is open-source software that extends Parquet data files with a file-based transaction log for ACID transactions and scalable metadata handling. Delta Lake is fully compatible with Apache Spark APIs, and was developed for tight integration with Structured Streaming, allowing you to easily use a single copy of data for both batch and streaming operations and providing incremental processing at scale.
The following list describes the key features of Delta Lake:
- ACID transactions: Protect your data with serializability, the strongest level of isolation
- Scalable metadata: Handle petabyte-scale tables with billions of partitions and files with ease
- Time travel: Access or revert to earlier versions of data for audits, rollbacks, or reproduce
- Unified Batch and streaming: Exactly once semantics ingestion to backfill to interactive queries
- Schema Evolution and enforcement: Prevent bad data from causing data corruption
- Audit history: Delta Lake log all change details providing a fill audit trail
- DML operations: SQL, Scala/Java and Python APIs to merge, update and delete datasets
- Open source: Community driven, open standards, open protocol, open discussions
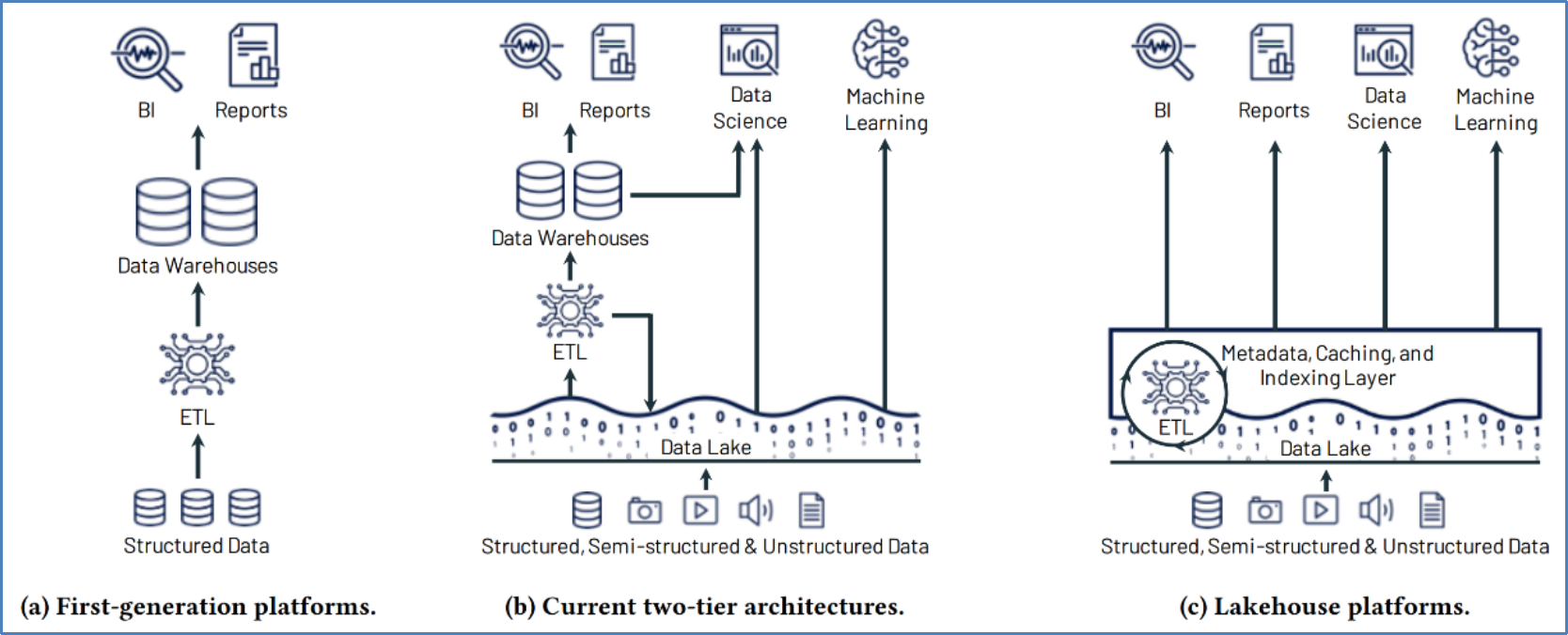 Figure 5. Evolution of data platform architectures to two-tier model (a-b) and the new Lakehouse model (c)
Figure 5. Evolution of data platform architectures to two-tier model (a-b) and the new Lakehouse model (c)For more information on the Delta Lake are available on the Delta Lake webpage and the following Delta Lake whitepaper.