
Running SQL Server 2022 with Red Hat OpenShift on AMD EPYC based Dell PowerEdge servers and Dell ObjectScale
Converting to Delta Lake format
Converting to Delta Lake format
-
Once the data became available in ObjectScale, we converted these files to the Delta Lake format using following steps:
- We deployed a spark pod in OpenShift using the following YAML manifest file. We used our custom spark image in our private image registry.
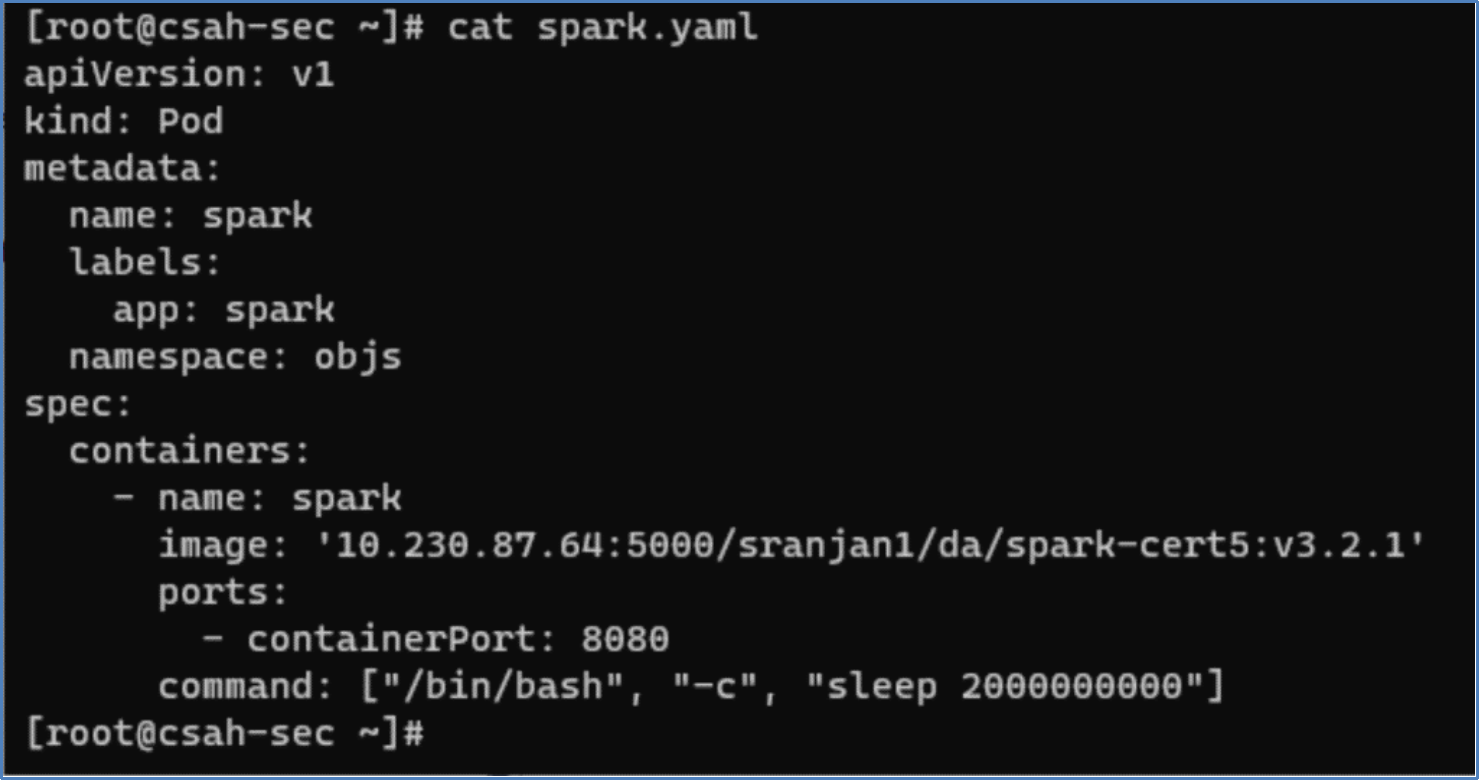 Figure 8. Spark pod YAML manifest
Figure 8. Spark pod YAML manifest- After the pod was deployed, we can verify it using the following oc command.
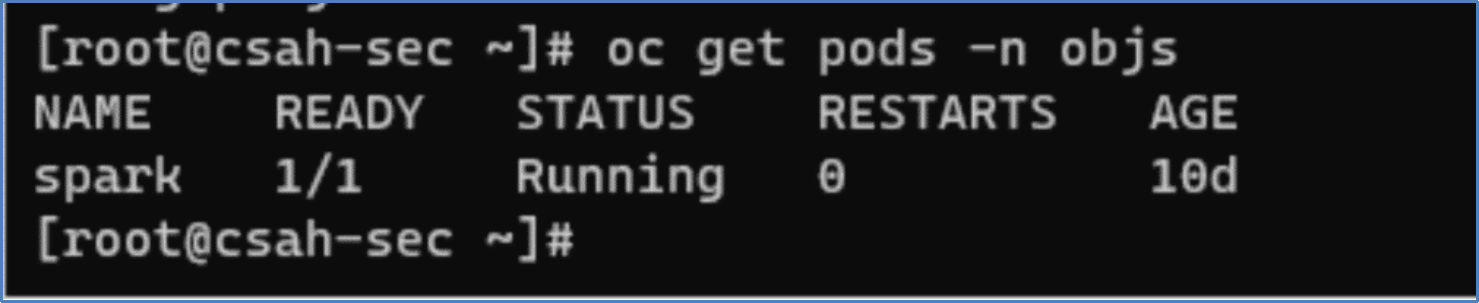 Figure 9. Spark pod status
Figure 9. Spark pod status- Now we can connect to the Spark pod and initiate a PySpark shell using the pyspark command. We pass the appropriate ObjectScale S3 API endpoints along with the access and the secret keys.

If the command is successful, the Spark login screen appears, as shown in Figure 10.
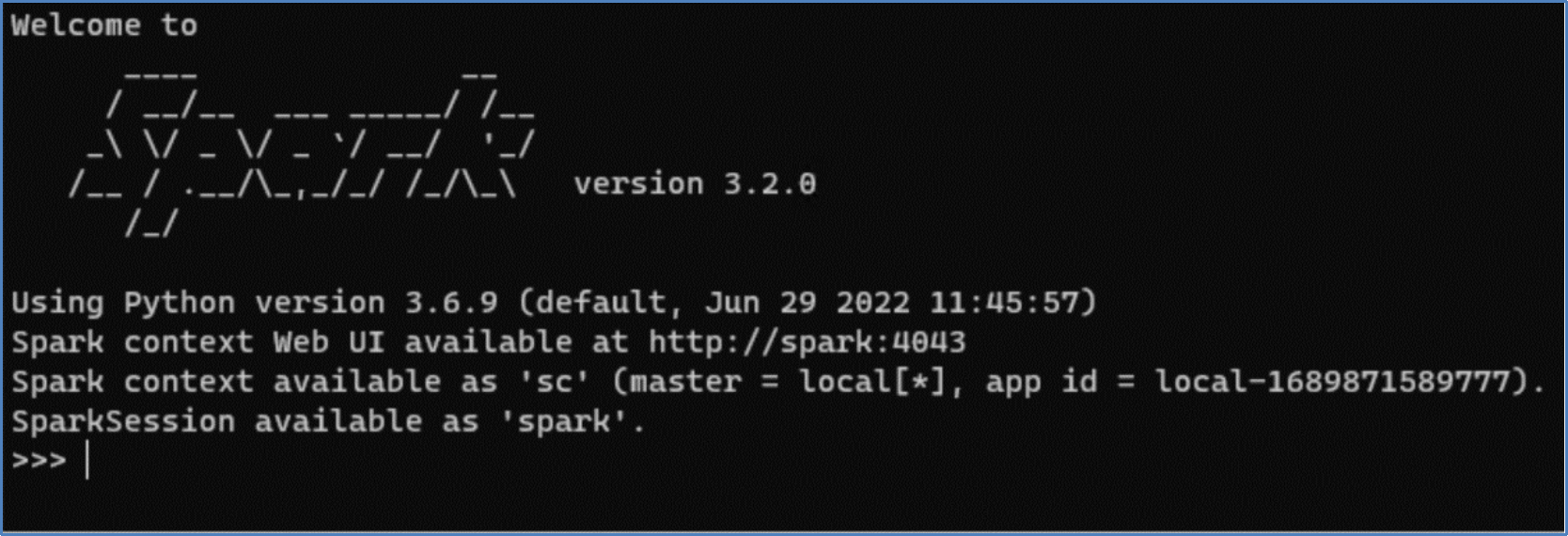 Figure 10. Spark login screen
Figure 10. Spark login screen- Define a schema based on the data file, as shown in the following sample script:

- After the schema is created, we can load the data into PySpark data frame as shown in the following script:

- Now we save this data frame as Delta Lake format on ObjectScale bucket as shown in the following script:

- We can verify the data in Delta Lake format using S3 Browser as shown in Figure 11:
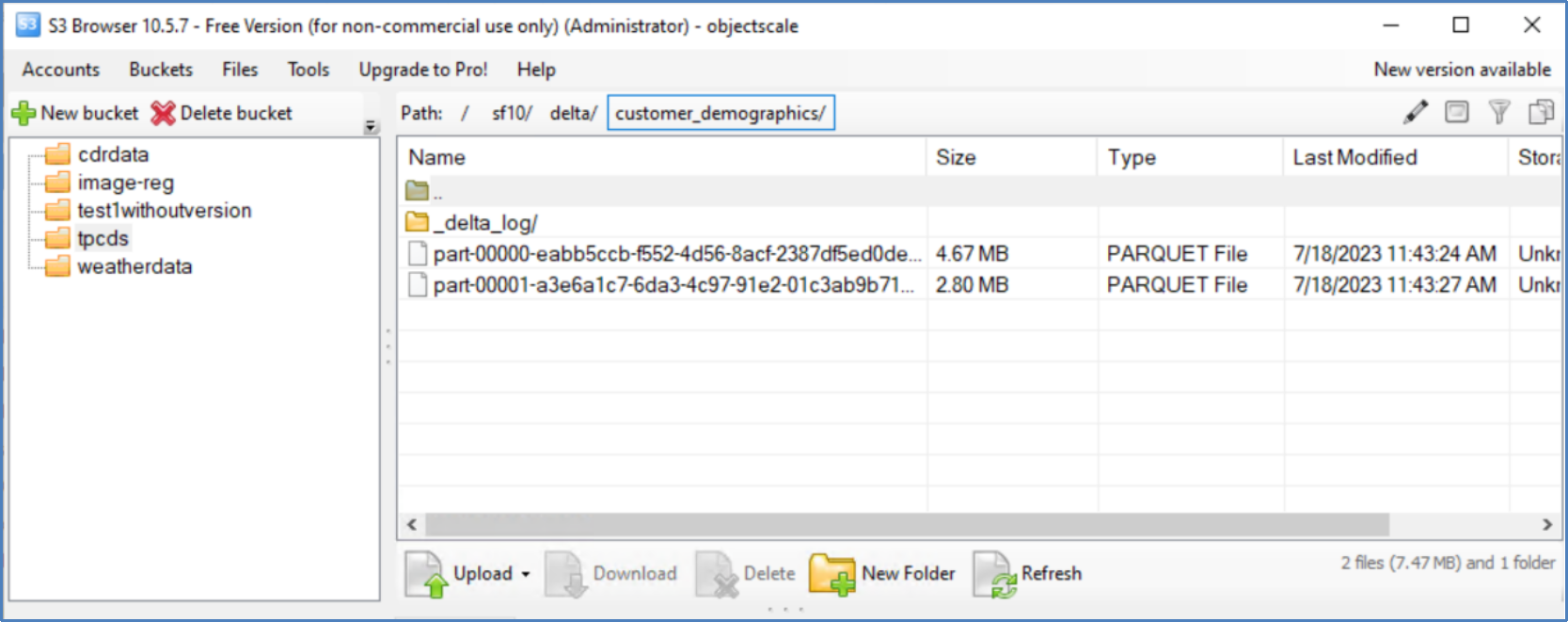 Figure 11. S3 browser bucket view
Figure 11. S3 browser bucket viewAll the .dat files for each of the 25 tables must be converted in the TPC-DS dataset and ingested into ObjectScale bucket.