
Model training example
Model training example
-
To show the capabilities of the Kubeflow platform in executing ML/DL training jobs as well as the scaling efficiencies of the OpenShift Container Platform, we ran the TensorFlow CNN benchmark to train the Resnet50 model, as shown in the following figure:
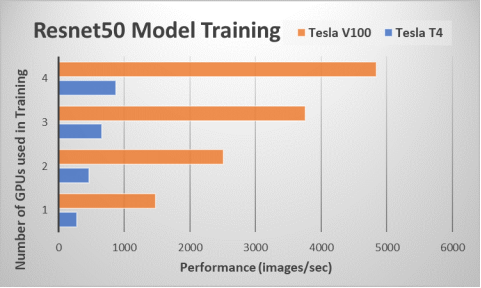
Figure 3. Training example: Resnet50 model
We ran the TensorFlow CNN benchmark using TFJobs, a Kubeflow interface to perform TENSORFLOW training and monitor the training runs. Figure 3 shows the performance of the training jobs using a throughput metric (images/sec). The performance results for the ResNet-50 benchmark is plotted for both NVIDIA Tesla V100 and T4 GPUs. As expected, using more GPUs to train the model results in a higher performance. We used the Horovod library developed by Uber to scale the training job for performing multi-node distributed training. The Tesla V100 GPU job executes approximately 5 times more images/sec than the Tesla T4 GPU, even though their theoretical TFLOPs delta is two times greater.
The Tesla V100 GPU uses the faster HBM2 memory, which has a significant impact on DL training performance. The Tesla V100 GPU model comes at a higher power and price point compared to the Tesla T4. We showcase a flexible environment where users can populate either the Tesla T4, the Tesla V100, or both GPUs on the OpenShift Container Platform and make it available to ML engineers through Kubeflow. The choice and number of GPUs will depend on the workload requirements and price targets for the ML/DL environment.
The following table shows the YAML file we used to deploy the TFJob on four T4 GPUs:
Table 1. YAML file for TFJob deployment
tf_nvidia_cnn.yml
apiVersion: kubeflow.org/v1beta2
kind: TFJob
metadata:
labels:
experiment: experiment
name: nvidiatfjob
namespace: default
spec:
tfReplicaSpecs:
Ps:
nodeSelector:
nvidia: t4
replicas: 1
template:
metadata:
creationTimestamp: null
spec:
imagePullPolicy: Always
nodeSelector:
nvidia: t4
containers:
- args:
- python
- /opt/benchmarks/tf_cnn_benchmarks.py
- --batch_size=256
- --model=resnet50
- --num_batches=100
- --num_gpus=1
- --variable_update=horovod
- --use_fp16=True
- --xla=True
image: nvcr.io/nvidia/tensorflow:19.06-py3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
nvidia.com/gpu: 1
workingDir: /home/benchmarks/tf_cnn_benchmarks.py
restartPolicy: OnFailure
Worker:
imagePullPolicy: Always
nodeSelector:
intelrole: worker
replicas: 4
template:
metadata:
creationTimestamp: null
spec:
nodeSelector:
nvidia: t4
containers:
- args:
- python
- /opt/benchmarks/tf_cnn_benchmarks.py
- --batch_size=256
- --model=resnet50
- --num_batches=100
- --num_gpus=1
- --variable_update=horovod
- --use_fp16=True
- --xla=True
image: nvcr.io/nvidia /tensorflow:19.06-py3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
nvidia.com/gpu: 1
workingDir: /home/benchmarks/tf_cnn_benchmarks.py
restartPolicy: OnFailure