Production Kafka
Production Kafka
-
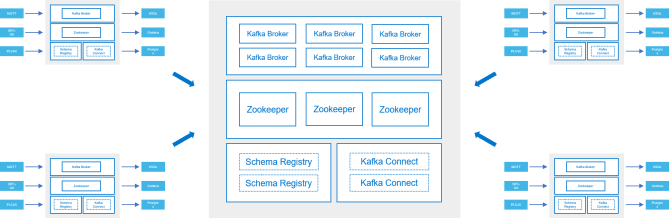
Kafka was designed for scale-out performance and high availability, and is based on the same principles that were used to develop big data platforms like the Hadoop ecosystem. The most basic production deployment that has support for high availability is a single-site, three-broker design, as shown in the following figure.
Figure 5: Three-broker Kafka deployment
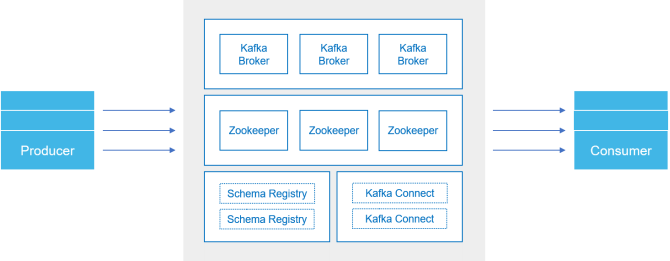
This design pattern can be an appropriate middleware design for a single in-plant event streaming platform. The system can be deployed and managed by Operational Technology (OT) staff. This middleware enables the conversion from point-to-point integrations towards a central service capable of handling many systems as both producers and consumers using a common framework.
Organizations that integrate data from computing and storage technology at the edge with core systems in one or more IT-managed core data centers require a more sophisticated design. Multiple-instance, cross data center Kafka implementations are now common. Many distributed computing uses cases require zero data loss and high availability service level agreements.
Figure 6: Cross-data center streaming deployment
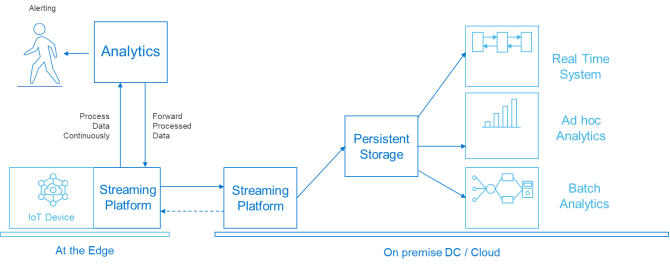
The design that is shown in the previous figure matches what Dell EMC deployed in its engineering lab to test the anomaly detection use case described in Predictive maintenance use case. Details are in Deployment scenario. This design can be extended to include more than two sites using common deployment, configuration, replication and high availability features at all sites. See the following figure.
Figure 7: Multiple-site streaming deployment