
Data understanding
Data understanding
-
The process of data understanding involves analyzing and understanding the data and their respective sources that are being used. This includes identifying the strengths and weaknesses of each source and exploring ways to combine them for a more comprehensive and accurate system. An initial analysis of the existing full-text search-based PSQN article retrieval system, followed by engagement with the data teams involved, revealed that the data management and curation process was predominantly manual and multi-stage. It also had unstructured points of entry, leading to some data quality issues.
Building on this information, an Exploratory Data Analysis (EDA) was conducted, uncovering a taxonomy misalignment related to the applicable product/band hierarchy between the article content management system and the target application (where UI/system articles are displayed for support agents). This misalignment impacted the design and effectiveness of the existing search system, prompting consideration of alternative approaches. The analysis also revealed substantial data gaps, highlighting the lack of complete data understanding.
The initial EDA was conducted on the article dataset from the existing system. The EDA involved examining the distribution of values, identifying missing data, and visualizing key aspects of the dataset. The primary goal was to ensure data quality and understand the underlying patterns and distributions before proceeding with further analysis and implementing DTS’s enhanced article retrieval strategy. Specific attention was paid to columns that provide valuable information about product categories, issue descriptions, symptoms, article title text, and associated URLs. DTS's analysis revealed substantial missing data in the higher-level product category (Prod Cat1) and article content fields, each with approximately 20 percent missing values. In contrast, the more specific product category (Prod Cat2) column had only 0.9 percent missing values, while the description, technical symptoms, and article link columns, were complete without any missing values. These findings, along with less than 50 percent accuracy in the higher-level product category and more specific product category data, highlighted significant quality concerns.
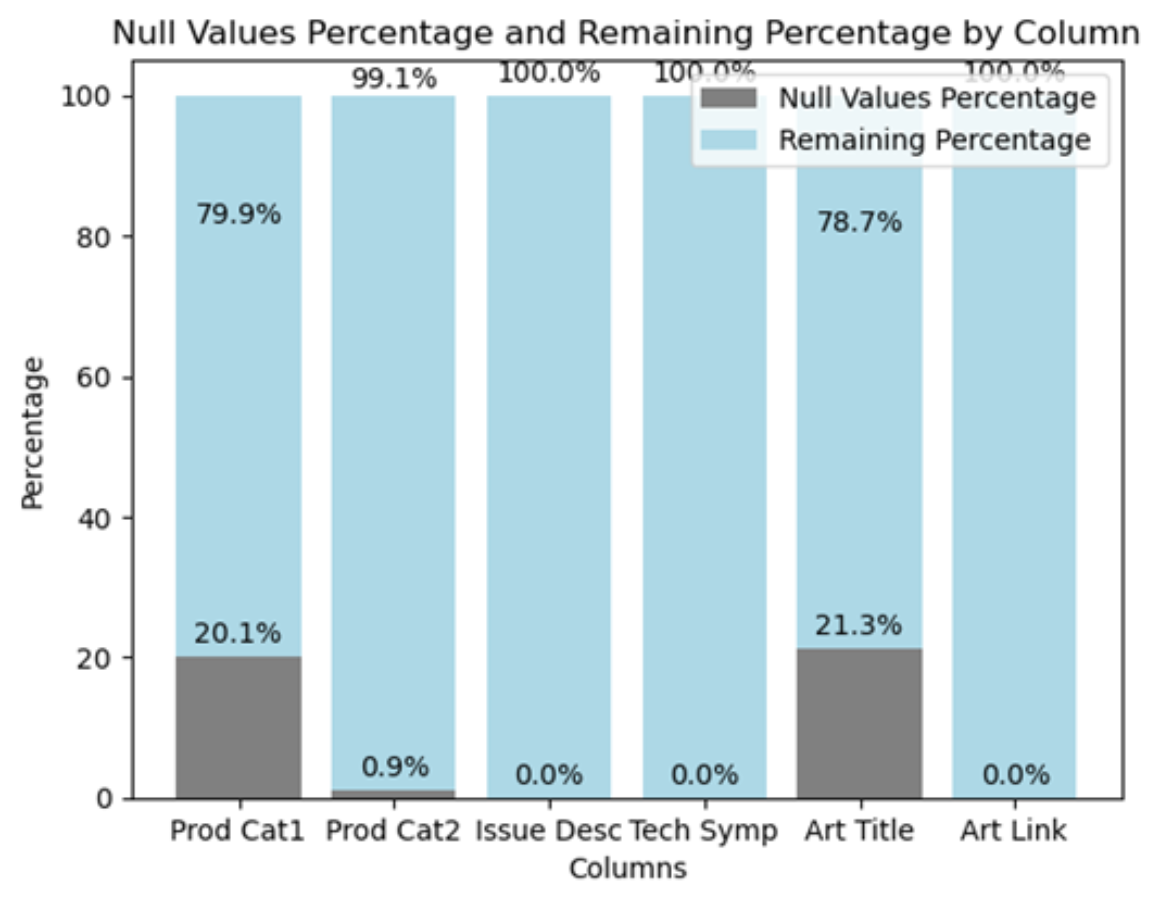
Figure 1. Initial EDA results
Subsequent analysis following engagement with data owners, it was understood that partial data is expected as not all articles are considered relevant at these product taxonomy levels. Further, analysis that incorporated the taxonomy misalignment understanding showed that where values did exist, they had a high (but not complete) 94 percent level of correctness. These insights lead to further analysis into upstream data which bridged the data gaps and were all brought into the data processing pipeline design.