
Solution Architecture
Solution Architecture
-
The architecture of our multimodal RAG chatbot leverages a robust system design to efficiently process and respond to user queries. The high-level flow of the RAG system is outlined in the following steps:
- Data Ingestion and Embedding: The system begins by ingesting diverse data types, which are then chunked, summarized, and embedded. This preprocessing step is crucial for preparing the data for efficient retrieval and analysis.
- Embedding Storage: The embeddings generated from the data are stored in a vector database. This database is optimized for semantic similarity searches, allowing for rapid retrieval of relevant data based on user queries.
- User Query Processing: When a user submits a query, it is embedded using the same technique as the data. The embedded query is then used to perform a semantic similarity search against the vector database.
- Data Retrieval: The most relevant data is retrieved based on the similarity search. In the case of multimodal RAG, this includes both text and images, providing a rich set of information for generating responses.
- Integration with LLM: The retrieved data, along with the user's query, is sent to a LLM. The LLM plays a critical role in interpreting and processing the data.
- Data Decomposition: The LLM decomposes the retrieved data into SQL and non-SQL components. This decomposition helps differentiate between structured queries that can be executed directly and other information that needs further processing.
- Text-to-SQL Conversion: The LLM converts the SQL components into executable SQL queries and submits them to the DDAE. This process allows for precise querying of structured data.
- SQL Results Retrieval: The tabular results from the DDAE are retrieved and converted back into natural language by the LLM. This step ensures that the structured data can be seamlessly integrated into the chatbot’s responses.
- Response Generation: Finally, the LLM generates a comprehensive response for the user. This response uses the retrieved data from both the DDAE and the vector database as context, ensuring accurate and contextually rich answers to the user’s query.
Note: Integration with AI governance tools like Privacera that are validated and certified with Dell Data Lakehouse provide addition of tools for Responsible AI implementations needed for enterprise deployment that are Data Access and Security, AI Governance, Evaluation, Guardrails, etc.
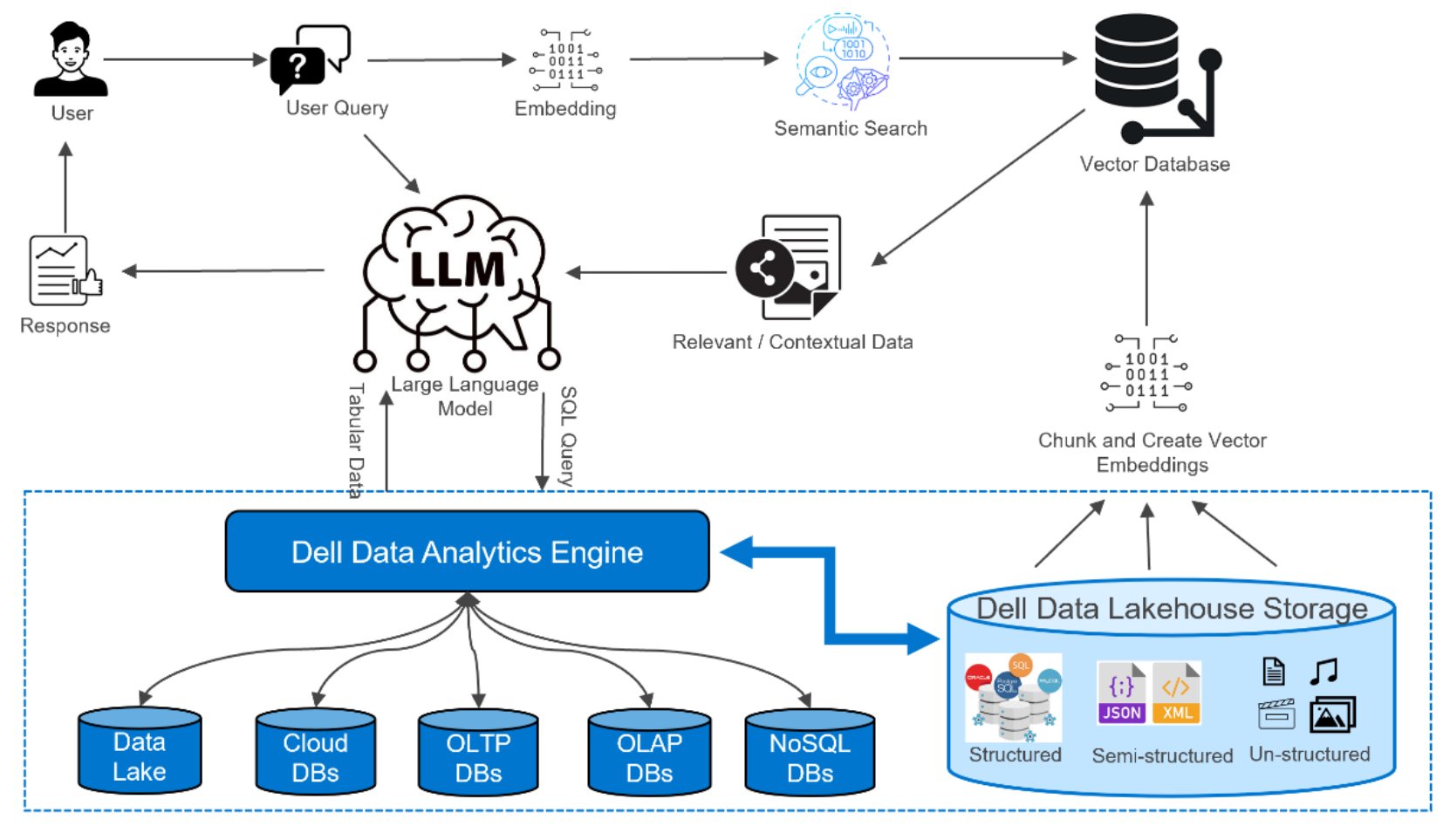
Figure 3. Dell Data Lakehouse Multimodal RAG Architecture
This architecture effectively combines data ingestion, embedding, retrieval, and natural language processing to deliver a sophisticated and responsive chatbot solution, capable of handling complex, multimodal queries with precision and efficiency.