
Training
Training
-
With the hardware and software platform available, the first training experiment run can be performed.
The steps for distributed fine-tuning training follow the example from this repository: https://github.com/opendatahub-io/distributed-workloads/tree/main/examples/ray-finetune-llm-deepspeed
The first step is to clone the repository which includes the notebook and necessary files and customize to the environment. The create_dataset.py python program can be modified to download a dataset (for example cognitivecomputations/dolphin-coder) and split it into the appropriate directories for the training (when the main notebook is run). By default, the training and testing jsonl files will be “./data/train.jsonl” and “./data/test.jsonl”
When the dataset is ready, launch the “ray_finetune_llm_deepspeed.ipynb” notebook file.
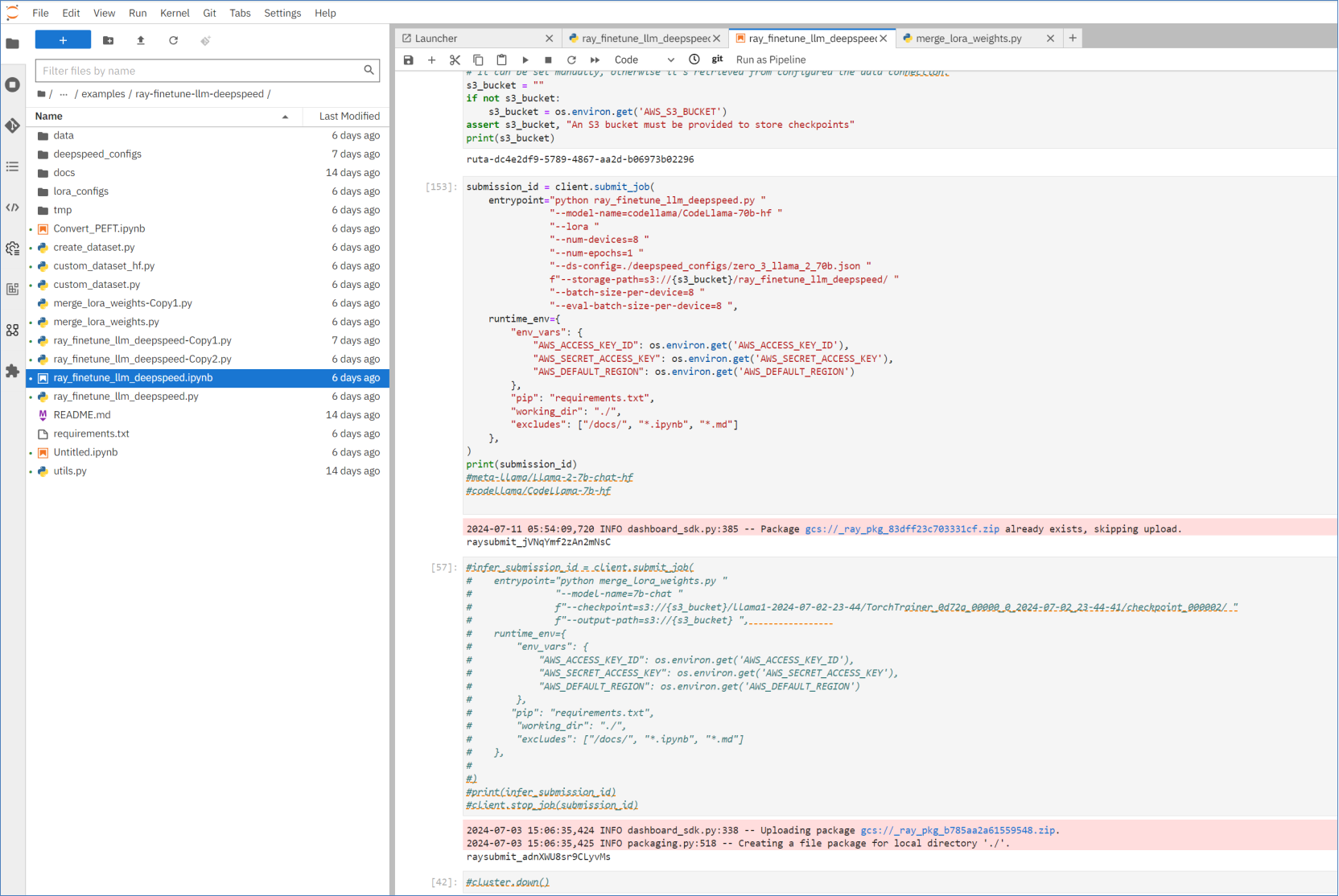
Figure 4. Fine-tuning Jupyter Notebook
After importing python modules for the notebook, creating the dataset directory, authenticating the CloudFlare SDK, the next step is to define the Ray cluster parameters.
To use all eight GPUs in the PowerEdge XE9680, the Ray cluster was configured with the following settings:
cluster = Cluster(ClusterConfiguration(
name='codellama',
namespace='drd',
num_workers=7,
min_cpus=12,
max_cpus=12,
head_cpus=12,
min_memory=200,
max_memory=200,
head_memory=200,
head_gpus=1,
num_gpus=1,
image="quay.io/rhoai/ray:2.23.0-py39-cu121-torch",
))
The next few calls in the Jupyter Notebook starts up the Ray cluster and shows the status. When ready the following Ray job can be submitted to the cluster for distribution across the eight pods in the cluster.
submission_id = client.submit_job(
entrypoint="python ray_finetune_llm_deepspeed.py "
"--model-name=codellama/CodeLlama-70b-hf "
"--lora "
"--num-devices=8 "
"--num-epochs=1 "
"--ds-config=./deepspeed_configs/zero_3_llama_2_70b.json "
f"--storage-path=s3://{s3_bucket}/ray_finetune_llm_deepspeed/ "
"--batch-size-per-device=8 "
"--eval-batch-size-per-device=8 ",
runtime_env={
"env_vars": {
"AWS_ACCESS_KEY_ID": os.environ.get('AWS_ACCESS_KEY_ID'),
"AWS_SECRET_ACCESS_KEY": os.environ.get('AWS_SECRET_ACCESS_KEY'),
"AWS_DEFAULT_REGION": os.environ.get('AWS_DEFAULT_REGION')
},
"pip": "requirements.txt",
"working_dir": "./",
"excludes": ["/docs/", "*.ipynb", "*.md"]
},
)
Note: The default job parameters are defined download the model from Hugging Face. The best practice would be to enable caching of the model locally for use in additional training run experiments and across the ephemeral Ray clusters to save network bandwidth and time.
The Ray cluster dashboard showing processing results can be viewed, and individual job status monitored as shown in Figure 5.
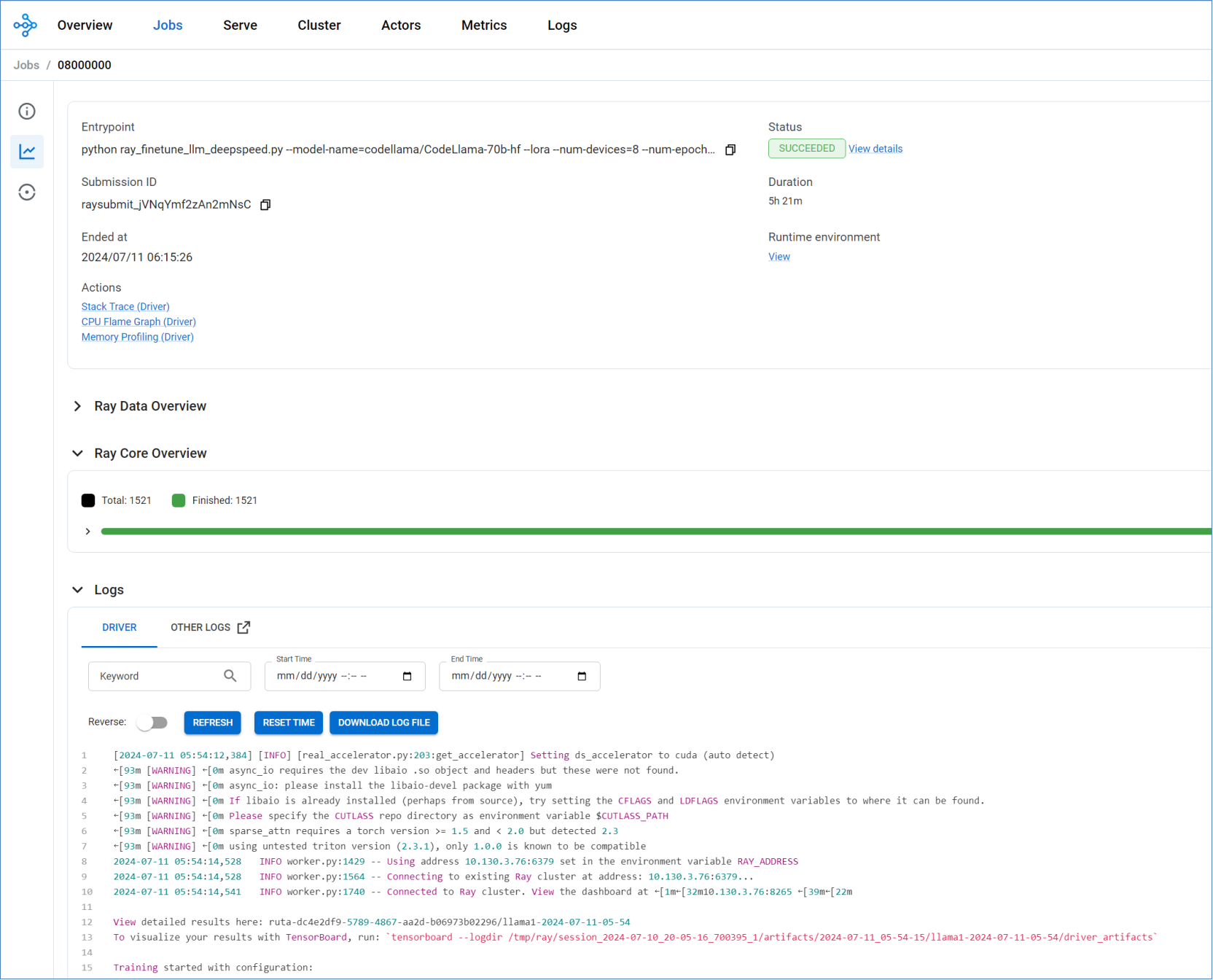
Figure 5. Ray cluster job status page
When the training is finished the logs will show where the results are stored including the best checkpoint.
The merge_lora_weights.py python script, from the Ray project on GitHub, was used to merge the checkpointed LoRA weights back to the base model used in training.