
None
None
-
In use case 5, we focus on model quantization. We are using the XE9680 with H100 GPU and running Llama 3 70B using floating point 8 (quantization) and floating point 16 (no quantization). The lower the latency, the better.
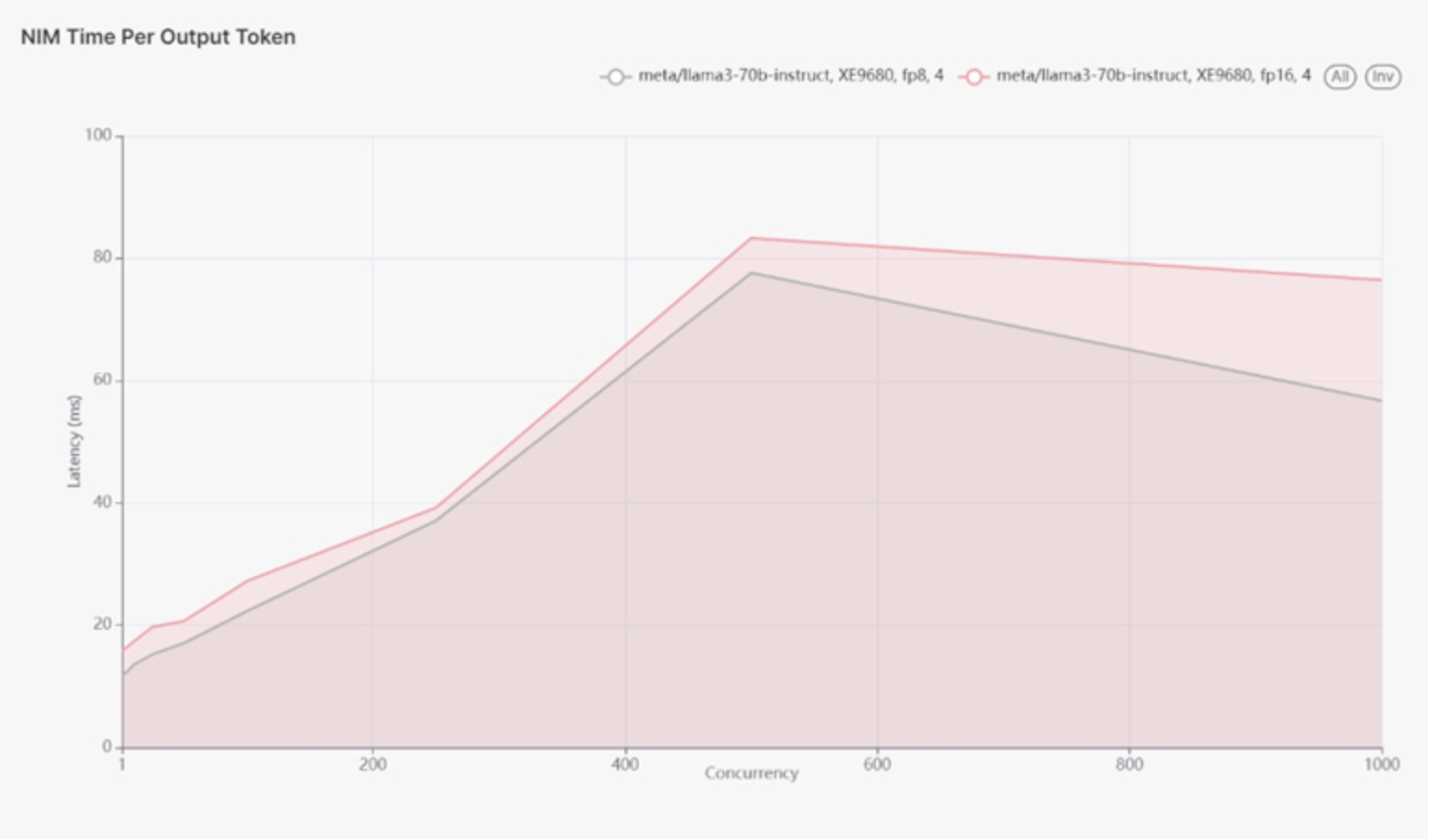
Figure 15 shows latency in terms of milliseconds and number of concurrent users. As the number of users increases from 1 to 250 concurrent users, we can see the latency increases respectively from about 15 to 18 milliseconds up to about 38 milliseconds. Notice the number of calculations for floating point 8 (FP8) and floating point (FP16) is very similar with FP16 a small percentage higher than FP8. In other words, switching from FP8 to FP16 increases workload calculations a small fraction or small percentage is increased GPU utilization, not doubling the number of calculations as one might assume. So, switching from FP8 to FP16 would not double the required capacity, but increase required capacity a small percentage point. We can see this pattern continue as we ramp from 250 concurrent users to 500 concurrent users. The latency for the FP16 model 83ms is slightly higher than the FP8 model 77ms for 500 users. Then after 500 concurrent users there is a different trajectory with latency and concurrent users differing. The number of concurrent users can increase up to 1000 users. The pattern remains consistent and FP16 produces slightly higher latency than FP8. This is in line with expected behavior where running inference on an FP8 model should be faster than FP16.
Figure 15.
Now let’s look at token throughput at floating point 8 and floating point 16 in figure 16. The throughput for the FP8 model 4.9k tokens/sec is higher than the FP16 model 4.27k at 500 users. That gap gets larger as we approach 1000 users. This is in line with expectation since an FP8 model is expected to have higher throughput than an FP16 model.
Figure 16.
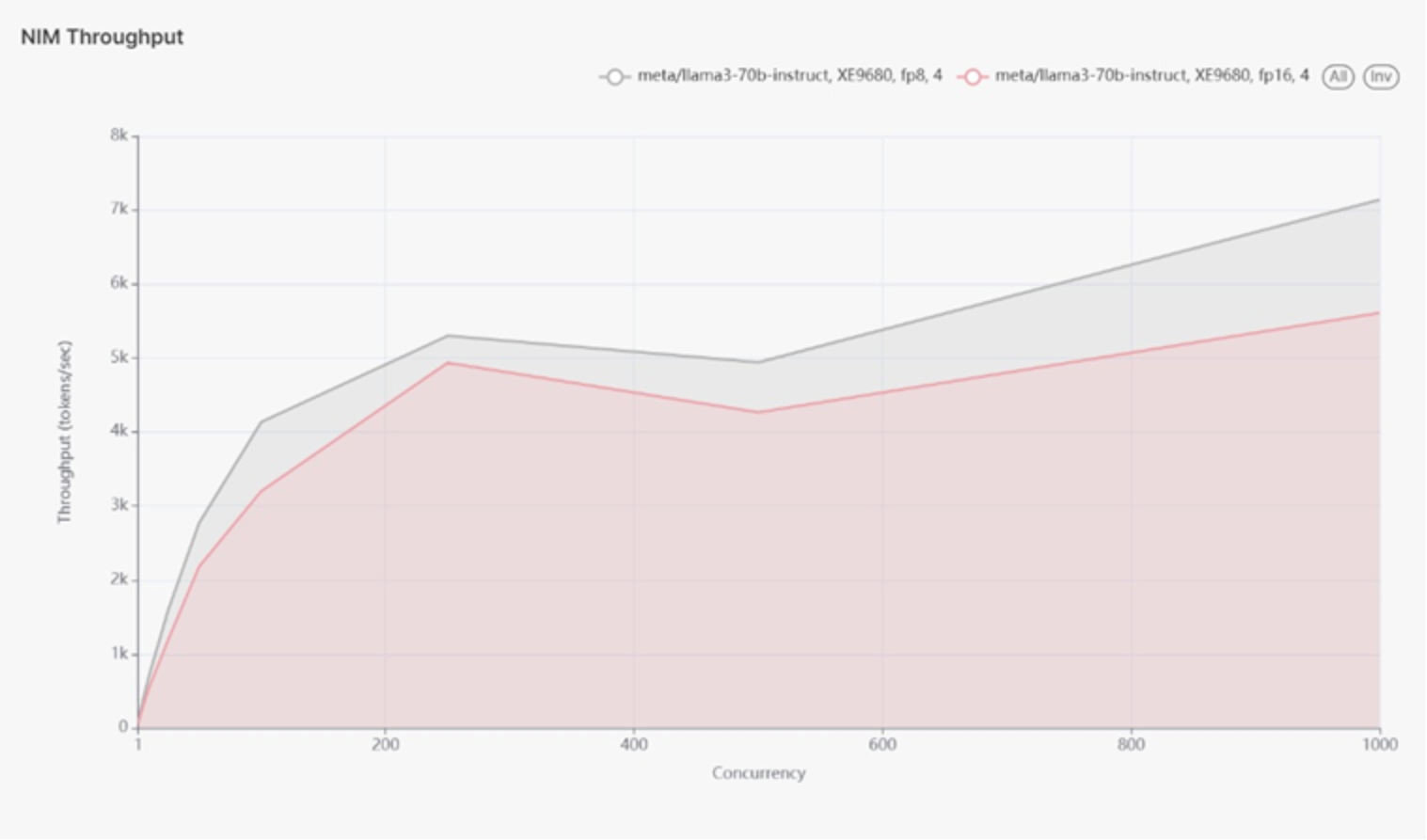
The XE9680 server demonstrated improved performance with FP8 quantization compared to FP16, achieving lower latency and higher throughput. This makes FP8 quantization a preferable choice for applications requiring rapid inference and high throughput. By understanding the performance implications of different quantization methods, enterprises can optimize their AI models for better efficiency and faster processing times. Therefore, making the XE9680 a versatile and powerful platform for diverse AI workloads.
- Benchmark results are highly dependent upon workload, specific application requirements, and system design and implementation. Relative system performance will vary as a result of these and other factors. Therefore, this workload should not be used as a substitute for a specific customer application benchmark when critical capacity planning and/or product evaluation decisions are contemplated.
- All performance data contained in this report was obtained in a rigorously controlled environment. Results obtained in other operating environments may vary significantly. Dell Technologies does not warrant or represent that a user can or will achieve similar performance results.