
None
None
-
In use case 4, we run multiple different models on the XE9680. We run a single Llama 3 70B model consuming four H100 GPUs, and simultaneously, we will run four instances of Llama 3 8B models. In other words, we are testing a single XE9680 with 8 GPUs in use, with five models (1x 70B + 4x 8B) to max out the GPU count. Now that we have five models running, we then gather metrics and compare to baseline with a single model running on a XE9680. This use case will be run with FP16.
A typical method to run multi-model for different quality of inferencing.
Table 9.
XE9680 with 4xH100 - 1x Llama3 70B
Concurrency
Throughput (tokens per second)
TTFT (milliseconds)
Request Latency (milliseconds)
1
61.98
31.51
2,377.22
5
298.26
62.04
2,472.27
10
555.83
105.11
2,636.96
25
1,188.08
183.70
3,090.78
50
2,231.64
280.40
3,336.81
100
3,210.77
535.31
4,526.07
250
4,864.33
1,639.95
7,247.85
500
4,986.51
3,119.18
13,946.16
1000
5,598.97
11,683.56
22,683.29
Table 10.
XE9680 with 4xH100 - 4x Llama3 8B
Concurrency
Throughput (tokens per second)
TTFT (milliseconds)
Request Latency (milliseconds)
1
161.91
13.59
892.12
5
789.59
15.82
907.71
10
1,564.05
16.98
915.43
25
3,765.83
19.14
947.77
50
7,111.02
23.95
967.37
100
13,085.72
30.41
1,058.03
250
24,157.45
127.77
1,422.77
500
28,866.42
344.66
2,377.18
1000
27,187.98
1,071.57
5,013.20
Figure 13 shows 1 instance of Llama 3 70B on the higher latency line. Figure 12 also shows 4 different Llama 3 8B models as a single line representing all 4 models running with lower latency.
Figure 13.
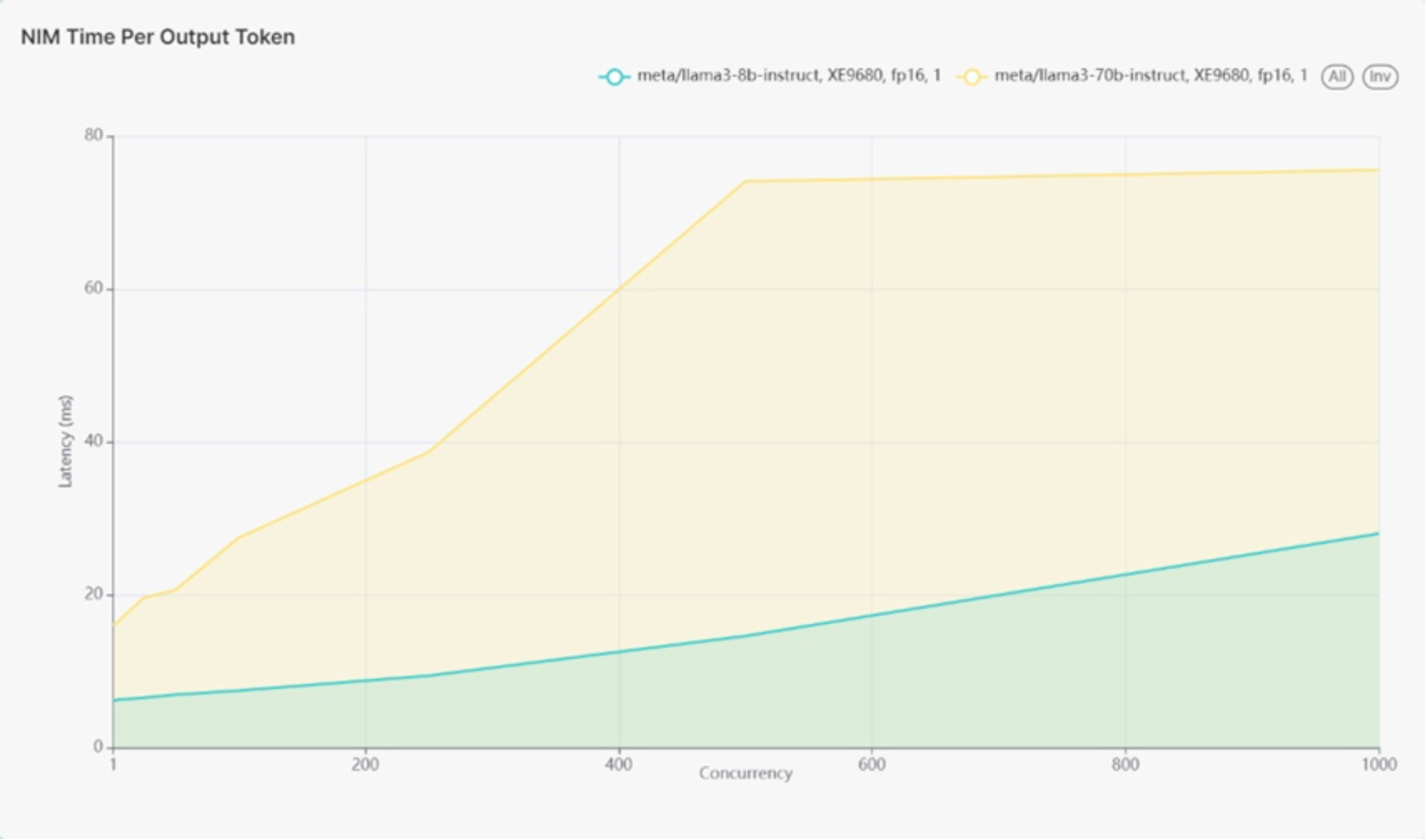
At 500 users, the latency of the four Llama 3 8B models remained at 14.6 milliseconds per token, close to the baseline of approximately 18 milliseconds for a single model. This suggests that running multiple models on the XE9680 does not significantly impact latency, indicating efficient resource management.
Throughput for the four Llama 3 8B models demonstrated a higher throughput compared to a single instance in the baseline, with four models producing approximately 29k tokens per second compared to the baseline of 10k tokens per second. The increase in throughput is not exactly four times that of a single model load, likely due to the limitations of the load generation tool, which did not exceed 1000 concurrent users.
Figure 14 shows 1 instance of Llama 3 70B on the higher latency line. Figure 14 shows 4 different Llama 3 8B models as a single line with lower latency.
Figure 14.
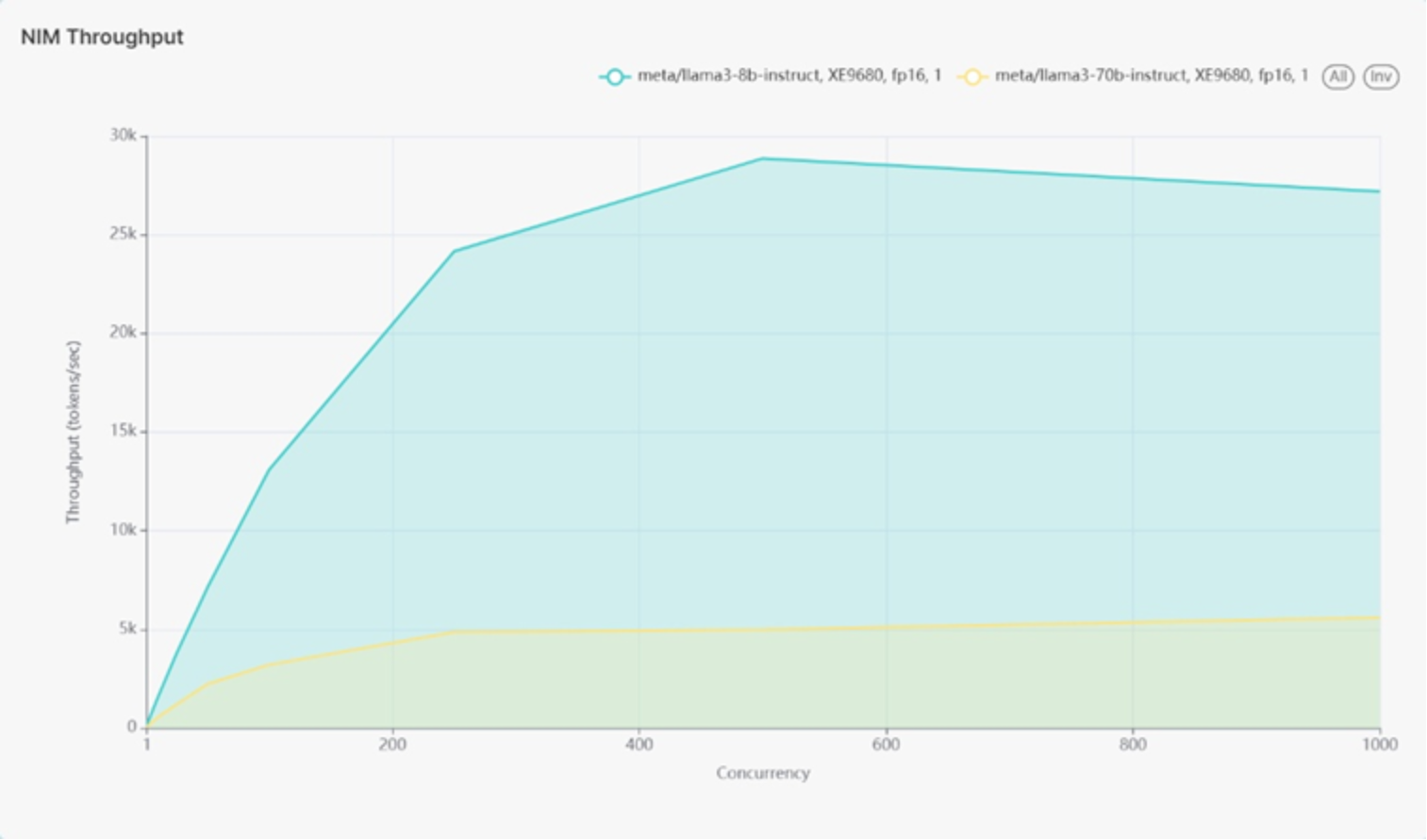
Latency for the Llama 3 70B model improved to approximately 74 milliseconds at 500 concurrent users, better than the baseline of around 83 milliseconds per token. The throughput for the Llama 3 70B model remained consistent with the baseline, achieving 4.99k tokens per second compared to the baseline of 4.27k tokens per second.
The XE9680 server efficiently handled running both one Llama 3 70B model and four Llama 3 8B models concurrently, demonstrating its capability to manage diverse and high computational workloads. The latency and throughput metrics indicate that running multiple models does not significantly degrade performance, suggesting that the XE9680 can be effectively used for complex AI tasks requiring multiple models. Additionally, the results highlight the importance of resource management, with each model reserving 100% of the memory from its respective GPU, ensuring efficient utilization of available hardware.