
None
None
-
In use case 3, we cluster test with multiple instances of Llama 3 models to load and distribute as many Llama 3 8B instances on two R760xa’s as possible. Each R760xa contains four L40S GPUs, which means each R760xa can hold four Llama instances. Scaling across two R760xa’s gives a total of eight Llama 3 8B instances, where each Llama 3 instance consumes one L40S GPU. A front-end load balancer is used to distribute the load across all eight instances.
Table 8.
2 x R760xa with L40S GPUs
Concurrency
Throughput (tokens per second)
TTFT (millisecond)
Request Latency (millisecond)
1
53.8
32.96
2,697.73
5
261.43
41.35
2,707.19
10
510.52
48.52
2,809.30
25
1,254.25
54.18
2,826.78
50
2,460.92
65.19
2,776.39
100
4,782.33
82.24
2,888.05
250
10,198.48
149.96
3,353.54
500
17,637.73
256.38
3,878.21
The test ran up to 500 concurrent users before encountering failures with the NVIDIA testing tools. At 500 concurrent users, the latency was approximately 25ms. The peak throughput was around 17.6k tokens per second. The actual maximum throughput is likely higher but could not be tested beyond 500 concurrent users due to tool limitations.
Figure 11 use case 3 latency diagram.
Figure 11.
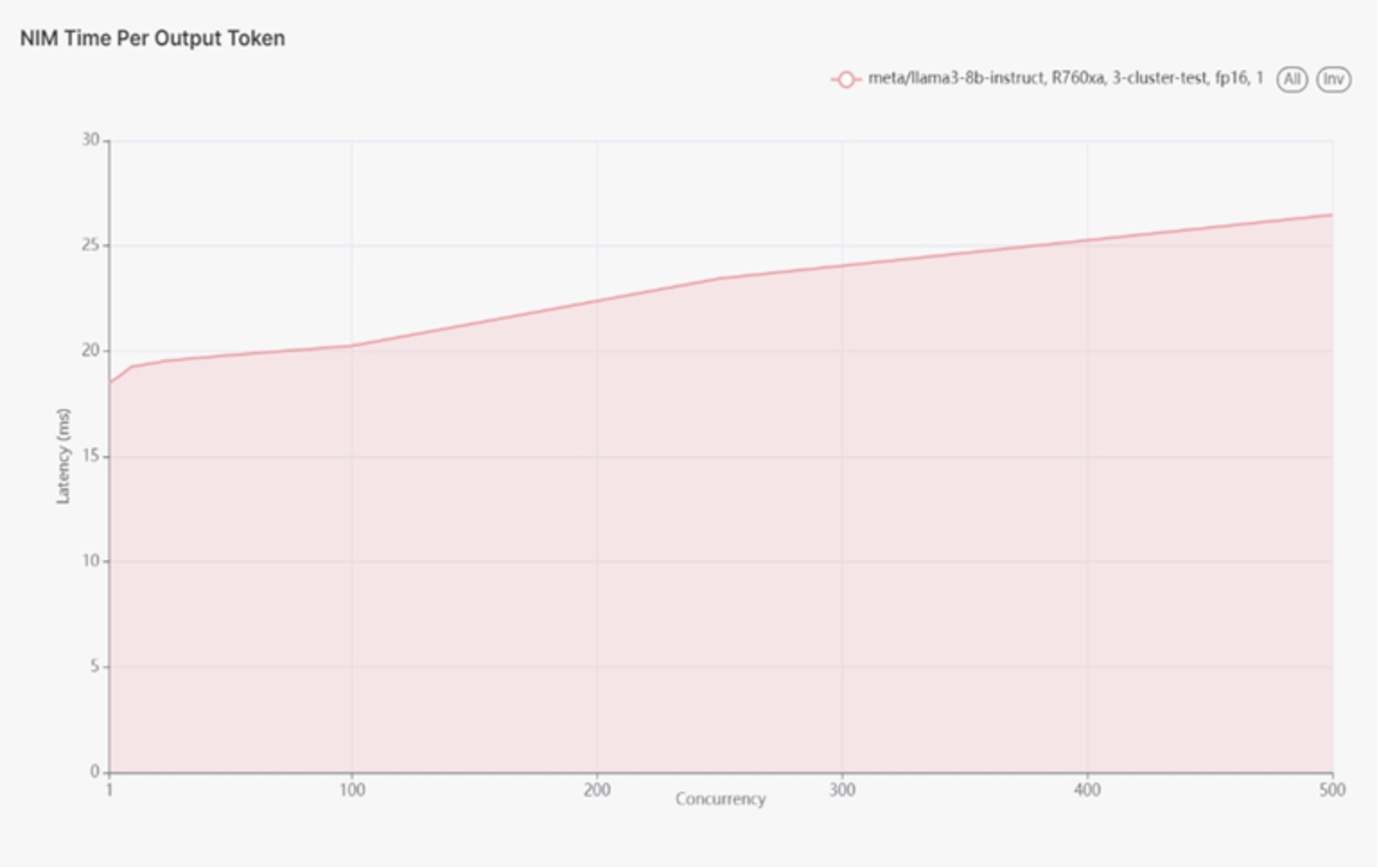
This test only went as far as 500 concurrent users. We received failures in the testing tools from NVIDIA after this.
At 500 users the latency was ~25ms
Figure 12 use case 3 throughput diagram.
Figure 12.
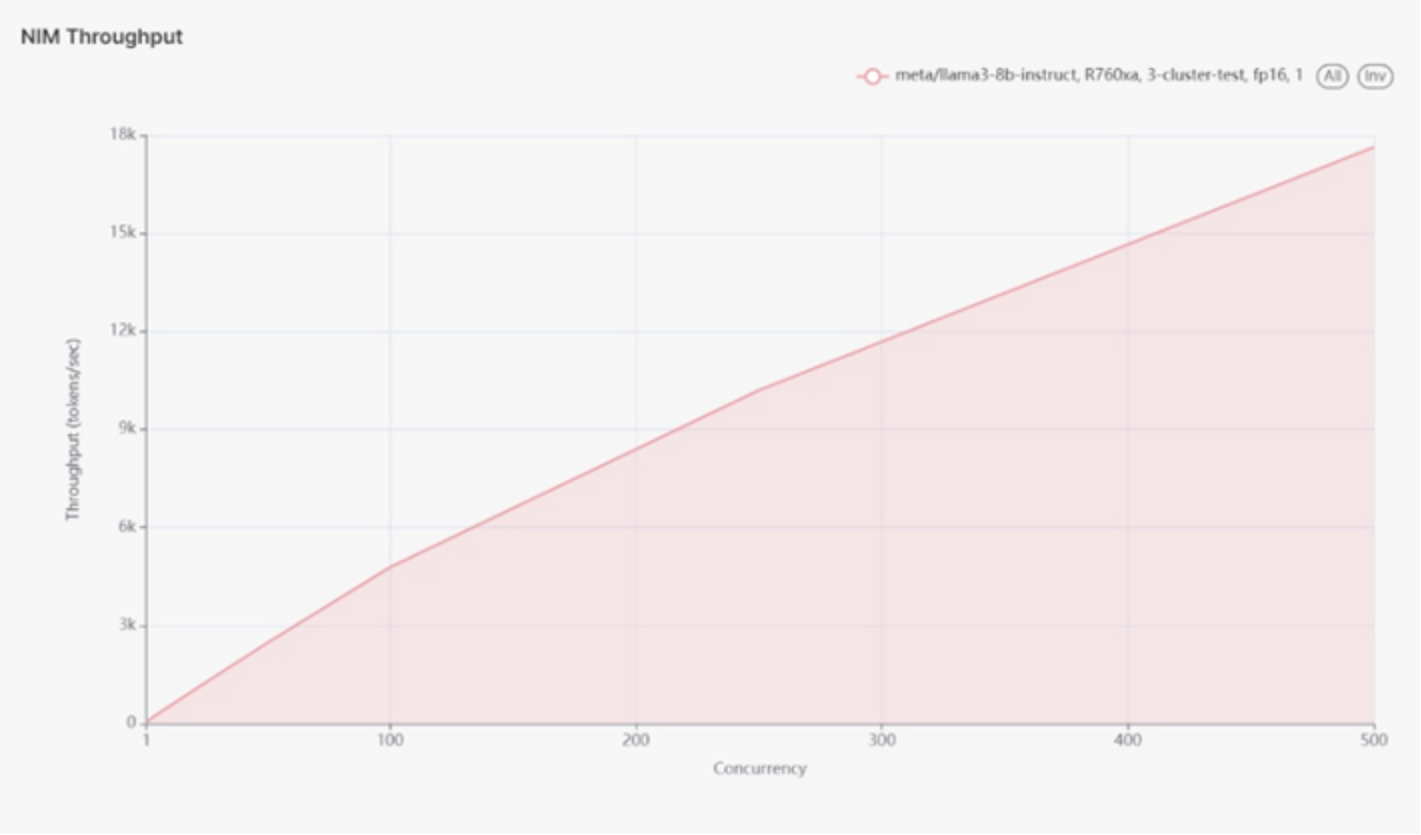
The Throughput peaked at ~17.6k tokens per second.
Looking at the chart, the true maximum is likely higher, but we were unable to push it beyond 500 concurrent users.
Analysis
The cluster test results highlight the scalability and performance of the R760xa servers in a Kubernetes environment. Deploying Llama 3 8B models across a cluster of two R760xa servers demonstrated substantial throughput and manageable latency for up to 500 concurrent users. The load balancer effectively distributed the load, ensuring efficient utilization of all GPUs.
The FP16 test showed that the system could handle significant load, with a peak throughput of 17.6k tokens per second and latency around 25 milliseconds at maximum tested concurrency. An additional exploratory FP8 test provided further insights, illustrating how different quantization methods impact performance.